Conclusions: Real Data, Fake Data & Google Translate

Facts matter. In 1962, Der Spiegel published a fact-based article that led to mass demonstrations, the end of the career of the German defense minister and marked a turning point in Germany’s embrace of a free press as foundational to a democratic society. 56 years later, randomly spinning the wheel for German test material for this study, I landed on a Wikipedia article about Der Spiegel that discussed the 1962 scandal, shown in Picture 15 and discussed in the empirical evaluation. About two months after that, Der Spiegel was shaken to its core when it emerged that one of its star reporters had been fabricating stories for years. In their own reporting, the newspaper says their reporter “produces beautifully narrated fiction. Truth and lies are mixed together in his articles and some, at least according to him, were even cleanly reported and free of fabrication. Others, he admits, were embellished with fudged quotes and other made-up facts. Still others were entirely fabricated” [zotpressInText item=”{PYHBJTQA}”]. The editors released a long mea culpa, stating:
We want to know exactly what happened and why, so that it can never happen again…. We are deeply sorry about what has happened…. We understand the gravity of the situation. And we will do everything we can to learn from our mistakes… We allowed ourselves to be defrauded: the top editors, the section editors and the fact checkers… Our fact checkers examine each story closely on the search for errors. Now we know that the system is flawed… For a fact checker back home, it’s not always easy to determine if assertions in a story are true or false… We will investigate the case with the humility it requires. That is something we owe you, our readers. We love our magazine, DER SPIEGEL, and we are extremely sorry that we could not spare it, our dear old friend, from this crisis. [zotpressInText item=”{NAGAIBTH}”]
In comparison, Google Translate processes 100 billion words a day [zotpressInText item=”{45FTMG28}”]. GT makes error after error in all 108 languages it treats, often fabricating words out of thin air, as analyzed throughout this report. It has no effective method to fact check their proposed translations, as shown in my four year test across dozens of languages that are discussed as Myth 5 in the qualitative analysis . Their results, though, are presented to the public without humility, as the pinnacle of advanced artificial intelligence in language technology. Where Der Spiegel experienced a foundational crisis when one reporter was found to be inventing fake news, GT’s entire production model is built upon invented facts.
To make use of the ongoing efforts the author directs to build precision dictionary and translation tools among myriad languages, and to play games that help grow the data for your language, please visit the KamusiGOLD (Global Online Living Dictionary) website and download the free and ad-free KamusiHere! mobile app for ios (http://kamu.si/ios-here) and Android (http://kamu.si/android-here). How much did you learn from Teach You Backwards? Your appreciation is appreciated!:
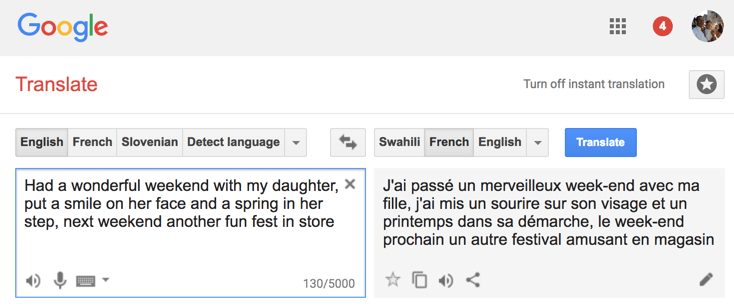
Picture 55 displays a typical translation scenario for GT, a tweet from a British dad translated to French. GT gets a lot of the words right, but makes major errors with the party terms “spring in her step”,1 “fun fest”, and “in store” – the translation points toward a springtime festival at the mall, instead of cheerful father-daughter time. The verb “had” and its implicit subject “I” are perfectly rendered, while the verb “put” and its use with “a smile on her face” puts a frown on the face of a Parisian informant: “Definitely not. I would say ‘ça l’a fait sourire’” (it made her smile). Taken in total, the output works at the MTyJ level, earning a middling 33.13 BLEU score, because the central sentiment “Had a wonderful weekend with my daughter” sails through with flying colors. The remainder of the tweet is a composite of fake data that would get a student an “F” and get a translator fired. [Update from November 2023: Automatic translation of the tweet in Picture 55, using GPT 4 on Bing, is almost identical to the translation produced by Google more than four years ago, with the exception that the word “ressort” was chosen for spring instead of “printemps”. AI large language models have taken over the public imagination, and are producing better results in certain situations than translations from the neural networks discussed in this work, but the near-identical results for this tweet show that machine translation has not been solved.]
What Hofstadter [zotpressInText item=”{DLK6QG2B}” format=”(%d%)”] documented from German, GT’s second highest scoring language, to English holds for the text above for English to French: “It doesn’t mean what the original means—it’s not even in the same ballpark. It just consists of English words haphazardly triggered by the German words. Is that all it takes for a piece of output to deserve the label ‘translation’?” Der Spiegel’s editors would print an immediate correction and apology if they discovered themselves printing such misinformation.
The consequences of mistranslation can be quite high. This is a note from the wife of a political prisoner in Egypt about attempts to arrange her first visit to her husband in five months:
!لا نزلهم نمر، ولا علقوا تعليمات تخصهم (رغم ان كل السجون التانية اتعلقلها تعليمات عالبوابة) ونمر مصلحة السجون الارضي ما بتجمعش ابدا
Picture 55: An English tweet translated to French by GT. Justin Naughton,(@HitchinCavalier)
The Google “translation” from Arabic to English has a word stew that is clearly related to prison, but might lead toward danger in the context of trying to deal with a totalitarian regime: “We do not put them down as a tiger, nor do they post instructions pertaining to them (although all other prisons are subject to instructions on the gate), and the ground prison authority does not assemble at all!” And yet, GT unhesitatingly offers itself as a tool for the justice system, and is uncritically used as a legitimate linguistic authority by police and courts around the world.
Apologists might object that the tweet in Picture 55 is too informal, or that the text attempted by Hofstadter was in some way atypical. A tenured computational linguist reacted to a draft of this report, “I still think that your use of what you call “party terms” like “out of milk” makes for a very high bar for a translator to surmount.” What, then, is the bar? If translating “in store” as “predicted” is too high, then your local weather forecast with “rain in store” for tomorrow is off limits for MT. A human who could not translate “in store” could never hold down a job as a translator. As an academic exercise, it is fine to experiment with the extent to which a translation engine can recognize when “in store” is related to shopping venues. Since MT claims to compete in the same space as human translation, though, it is reasonable for consumers of a commercial product like GT to expect that it will handle whatever correctly-composed text they put before it.

Picture 55a: Google Translate version of the famous Italian song “Bella Ciao”, in comparison to a human translation. Is “goodbye” too big an ask for machine translation?
Granted, chat messages peppered with abbreviations and irregularities might require natural intelligence to decipher, like “La dr sto la ora 13 data 7august”,2, but are goodbyes too high for machines? GT manhandles common farewells such as the French “à toute” (GT: to all) and “à tout à l’heure” (verified 🛡 wrongly by the GT community as “right away”), or the Swahili “kwa heri” (GT: for good), “kwa herini” (GT: to the herd) and “tutaonana” (GT: we will see, shown in Picture 37). The problem extends throughout the NMT universe – regard, for example, how DeepL translates the essential closing “Regards” from English to French. And, the problem extends to each and every language GT covers. “Vice”, for example, is “uvane” in Norwegian and Danish, spelled as “ovana” in Swedish, but given as the lei lie “vice” for all three in Googlenavian. Making up stuff about common words and phrases is not a virtue.
Objections that such-and-such a text has some unusual aspect that makes it unfairly tricky to GT, of course, obviate the claim that it has omniscient command of that language. For successful public translation, it should not be incumbent on the user to monitor their own expressions, in order to not get held up by inadvertently confusing the program with any old normal speech such as the tweets in Table 2. In practice, while discovering text that GT cannot handle is easy as pie, manipulating text on the source side to nudge the target output into shape can involve considerable backing and forthing by a knowledgeable user.
One reviewer proposes that “there are controlled languages and for controlled languages, MT can be error-free”. That is, perfect translations are possible if the vocabulary and set of concepts are kept within a discrete domain. Having written rejected proposals for international agencies to seek funding along those lines for refugee and emergency communications, and having apps for other domains inching through the lab, I agree that stellar translation is possible among a consistent stock of phrases that are invoked in restricted ways.3 For example, a weather vocabulary can be built so that weather sites can slot in the local terms expressing a limited range of occurrences, such as “[Rain], [heavy at times], [continuing until] [12:00]”.
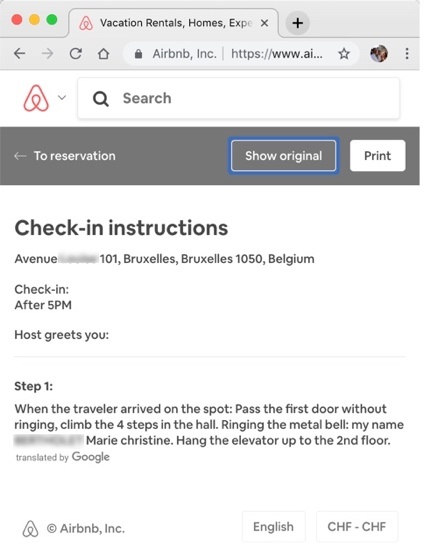
Problems occur the minute one ventures away from a human-curated controlled vocabulary. Malinda Kathleen Reese puts GT through its paces by running a text from English to another language, or a few, and then back to English. (Because she does not leave breadcrumbs about the languages involved, her results are not reproducible.) In the video above, she used standard weather report verbiage for her source material. The closest GT came to adhering to the original was that “Average winds steady from the northeast at 9 miles per hour” came back as “A major windstorm in the northeast will be prolonged to 9 years.” Similar drift can be seen in Picture 56, where a controlled situation with millions of texts for training data produces a Tarzan arrival situation for Airbnb – fortunately, in this case, without making a crucial mistake as in Picture 60 that could have left a guest wandering the streets in the snow. In most circumstances, though, neither the user’s vocabulary nor their phraseology can be controlled, and GT does not attempt to do so. The selling point of MT is that it accommodates the language of the user, not that users adjust their language to the machine. In this respect, the blame-the-user argument that certain language is too casual and that other language is too this-or-that falls apart prima facie as an excuse for poor performance. The idea that users should control how they talk to machines makes their language unnatural – a fine project to enhance the way humans and computers interact, but, by definition, not true Natural Language Processing.
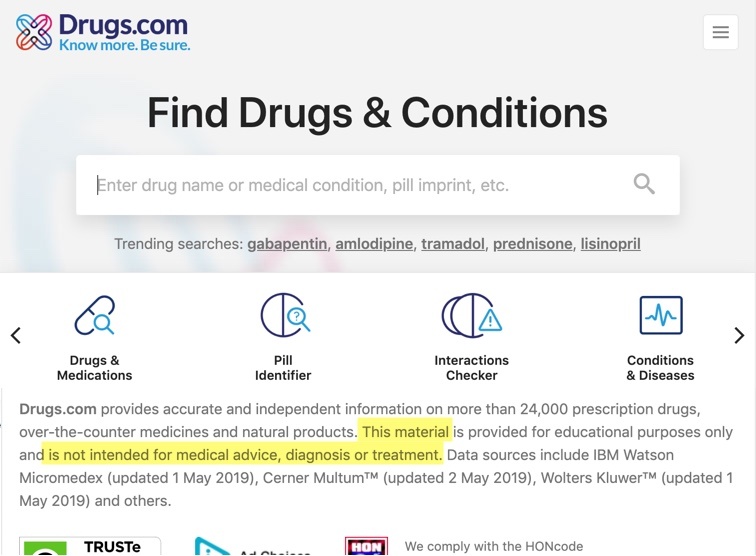
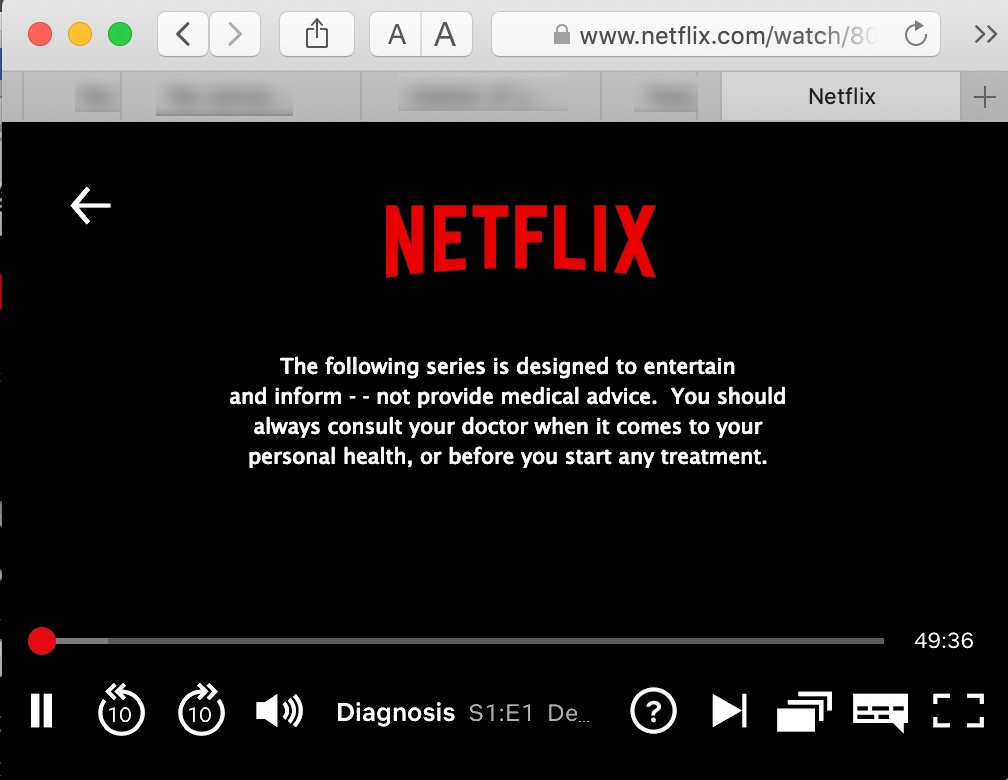
Picture 56.1: Drugs.com finds it necessary to warn visitors against relying on the site for “medical advice, diagnosis or treatment”, and links to a more detailed disclaimer from thousands of its pages. Google Translate is used by doctors and other professional staff as a tool to perform diagnoses and dispense instructions and advice in medical situations worldwide, with no such disclaimer.
For one aspect of translation, the medical domain, I would suggest that Google is under an ethical obligation, if not a legal one, to invest however many millions are needed to offer a functional product.4 With GT on countless Android devices, and their aggressive PR campaign to implant the idea that they provide reliable translations, the service is often used in medical settings where the patients and the care givers do not speak the same language. In a study published in the Journal of the American Medical Association, 8% of hospital discharge instructions translated from English to Chinese were found to have the potential for “serious harm” [zotpressInText item=”{759FWFCJ}”]. Chinese achieved a Tarzan score of 65 on TYB tests, along with 5 other languages. The medical translations will clearly get worse for the 86 languages that scored lower, such as for languages with large immigrant communities in the US like Hmong (Tarzan = 40, see Fadiman [zotpressInText item=”{PIEHSLWM}” format=”(%d%)”] for a gripping ethnographic portrait of Hmong interactions with US health care, including language difficulties), Filipino (35), Somali (30), and Haitian Creole (0). A study of GT translations from English to 26 languages of medical phrases in the British Medical Journal, that over-represented well-resourced languages that tested highest in TYB, found that, on a binary scale, 42.3% were “wrong” [zotpressInText item=”{5248838:JZP4HQKT}”] – including a Swahili instance that was translated as, “Your child is dead”. The problem is exacerbated in continental Europe, where English is usually not one of the languages in host/immigrant interactions, and GT will fail. (Note: this is presented as a definitive statement, not they will “probably” fail. No doubt the occasional medical phrase will survive passage in GT from Norwegian to Kurdish, but there is no way for either participant to know whether any given meaning has been adequately communicated, and the preponderance will be garbled beyond intelligibility.)
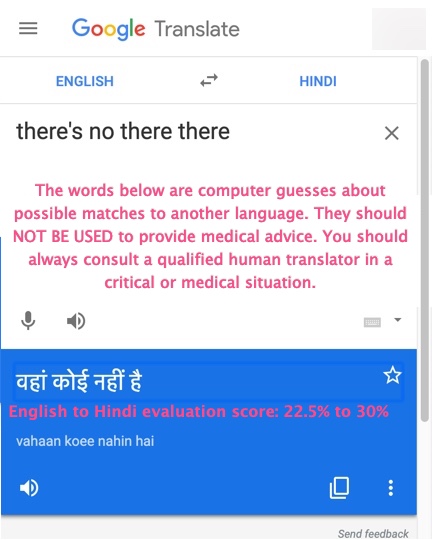
For languages at the bottom of the scale, the potential for serious harm is 100% of instructions that could cause harm if not followed correctly. Google does not have a medical license, and they do not have poetic license to manhandle medical terms. Having planted themselves in the middle of life-or-death considerations (does the doctor understand the symptoms? does the patient understand the prescription instructions?), it is incumbent on Google to get those translations right. 8% to 100% risk of harm for 91% of their languages vis-à-vis English, and closer to 100% for 5149 non-English pairs, is medical malpractice. Improving their controlled medical translations would require gleaning terminology and typical phrases from the domain, and paying professionals to translate those items to 101 languages (Latin does not pertain). The cost does not matter – Google has established the notion that their translations are valid in medical situations, so they should spend however many minutes of next Tuesday morning’s profits it takes to fulfill that promise. Anything less is a violation of their professed code of conduct, “Do the right thing”. Until they do, every GT translation should be printed with the same sort of warning that comes on a bottle of untested dietary supplements: THIS PRODUCT HAS NOT BEEN APPROVED FOR MEDICAL PURPOSES. When research in two leading medical journals, JAMA and the BMJ, converges on the same proscription, it is imperative to pay attention: “Google Translate should not be used for taking consent for surgery, procedures, or research from patients or relatives unless all avenues to find a human translator have been exhausted, and the procedure is clinically urgent” [zotpressInText item=”{5248838:JZP4HQKT}”].
Google welcomes visitors to its homepage with a button saying “I’m feeling lucky” that usually leads to the first result for their search. Do you ever click it? Certainly not. You prefer using your own intelligence to sift through for the result that most appropriately matches the search you have in mind. Google maintains the button for the sake of tradition, but essentially put it out of service in 2010 when they introduced Google Instant to provide as-you-type search predictions. The company realized that their strong suit was parsing search strings in a way that reveals the most likely candidates, rather than choosing which candidate the user will ultimately select. Yet “I’m feeling lucky” is the guiding precept of GT, although translations typically involve search strings that are more complex or ambiguous or unusual than most web searches – about 66% of web searches are 3 words or fewer [zotpressInText item=”{I5T85BZ4}”], and frequently skew toward known terms such as “weather” to which Google can attach certain behaviors based on past user clicks and other heuristics. GT pretends that “I’m feeling lucky” is a legitimate strategy for translation output, and the public, the media, and even many ICT professionals fall for that claim. When people do not speak the language they ask GT to translate toward, they have no way to use their own intelligence to evaluate the results, so they trust what the computer tells them. In a phenomenon I call Better-than-English Derangement Syndrome (BEDS), people are well aware that Google still falls short at NLP tasks in English – such as their Android phone replacing “was” with the unlikely “wad” as they type – but suspend their disbelief for other languages, even though those languages have far less actionable data and linguistic modeling research. Based on my empirical research across GT’s full slate of 108 languages, our trust has not been earned.
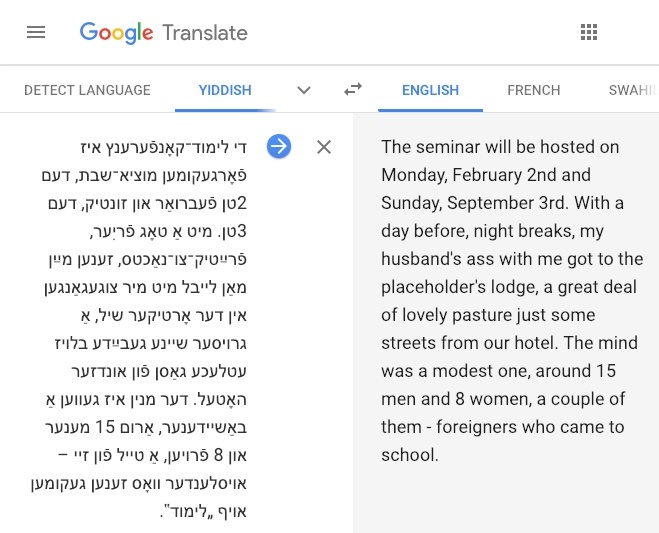
Picture 57: A paragraph from a news article from the Yiddish Daily Forward, translated by GT. Saturday is Monday, and February is also September, so book your travel accordingly.
Some people forgive the shortfalls in GT with the expectation that the service is getting better all the time. “Continuous updates. Behind the scenes, Translation API [the paid version of GT] is learning from logs analysis and human translation examples. Existing language pairs improve,” Google tells its Cloud customers. GT is undoubtedly improving in its high-investment languages as it funnels ever more parallel human translations into its training corpus. On a purely subjective basis, news articles translated to English from German or Russian feel to me like they read better than they did a couple of years ago, and others also report a sense of improvement at the top. Even so, at holiday shopping time in 2021 on a big retailer’s German website, “getting better all the time” GT generates this nonsensical collection of English words for “Das könnte dir auch gefallen”, to guide shoppers toward additional recommended products, in big, bold letters: That could you also please
For most languages, there is little possibility of harvesting large numbers of well-translated parallel texts before the glaciers melt in the Alps. Even websites that deliver daily news in more than one language, such as the BBC and Deutsche Welle, do not line up neatly enough among versions to match with confidence which articles are discussing the same events, much less how the internal structures of the articles compare (sentence-by-sentence translations are rare). None of the articles from synchronic online versions of the English and Yiddish newspaper The Forward were the same at the time of writing, meaning there is no way to learn by scraping the web for a human version of the dumpster fire5 in Picture 57. My four year test of Google’s claims to learn from user contributions found that their “suggest an edit” feature incorporates suggested translations a maximum of 40% of the time, and a detailed analysis of the procedure by which they use the crowd to verify translations shows they deviate widely from accepted best practices for both crowdsourcing and lexicography. The section of this web-book on artificial intelligence details why AI is only conceivable as an aid to MT for the few languages with substantial parallel corpora, and the sections on the mathematics of MT enumerate the confounding factors of lexicography and linguistics that present an astronomical number of translation challenges many orders of magnitude greater than the finite capacity of any supercomputer to account for with today’s best NMT methods. The statement that GT is continuously improving is undoubtedly true, but the implication that those incremental improvements will transform the majority of languages on the list to viability the next time you need them is undoubtedly false.
The computer scientists who develop MT systems like GT will object vociferously to my imputations against their veracity. I do not mean to accuse them of dishonest work – for all the reasons discussed above, MT is extraordinarily complicated, and most people I know in the field dedicate long hours pushing forward on the frontiers of technology. Rather, I suggest that computer scientists have a definition of successful translation other than the smooth transfer of meaning across languages. Within the field, translation is scored like basketball. You do not expect that every shot will go in. Some shots will roll off the rim, some won’t even hit the backboard, but some will swish through the net and there will be high fives all around. NBA players consider a field goal percentage north of 50% to be very good. MT engines compete using similar metrics for success, with the winning team being the one that lands the most hoops even if the final score is low.
When Facebook’s chief AI scientist states that, “amazingly enough”, their NMT systems are capable of producing “what essentially amounts to dictionaries or translation tables from one language to another without ever having seen parallel text” (see the video and transcript), he genuinely believes that the game is won if some fraction of shots go through the hoop. At Google, Johnson et all [zotpressInText item=”{EWBHWBHM}” format=”(%d%)”], Schuster, Johnson, and Thorat [zotpressInText item=”{K2IBBSGY}” format=”(%d%)”], and Wu et al [zotpressInText item=”{4DUXVV8G}” format=”(%d%)”], are not lying about the results of their research. They are earnestly reporting scores that show some amount of successful approximation between the languages they measured. Tristan Greene, in an article about AI software from Facebook that created dangerous misinformation, offers this colorful counterpoint: “there’s no reasonable threshold for harmless hallucination and lying. If you make a batch of cookies made of 99 parts chocolate chips to 1 parts rat shit, you aren’t serving chocolate chip treats, you’ve just made rat shit cookies.”6
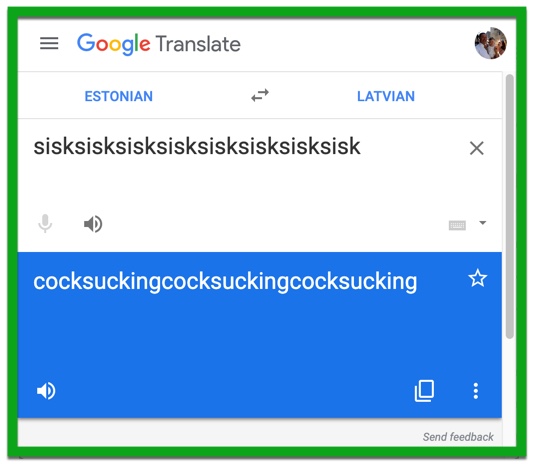
Picture 57.1.1: Google “translation” from Estonian to Latvian; the same result is given from the geographic cluster Estonian/ Latvian/ Lithuanian among each other and to English. Finding MUSA translations is a parlor game for the members of the Google Translate Reddit.
The falsehoods come when their experiments are presented to the world by their company as “translation between thousands of language pairs”. In fact, Google researchers measured 60% average improvements in BLEU score between English and three high-resource languages when they switched from statistical to neural machine translation – nice! – but offered no evidence regarding the 99 other languages in their system, versus English or from Language A to Language B. Nevertheless, mumbo jumbo about NMT bringing Google to near-human or better-than-human (whatever that means) quality across the board, as well as “zero-shot” bridging between languages that have no direct parallel data, has made computer scientists and the public at large believe that we have reached a golden age of automatic translation. While in certain top languages, exclusively when paired to English, GT often swishes pleasantly through the hoop, declaring those successes as victory throughout the translation universe, as measured empirically herein and also seen in virtually every non-systematic spot test (humorously exposed in Picture 57.1.1), is patently untrue.
Particularly awry is the oft-touted notion that translation can be – and by some miracle already has been – achieved by AI for languages where copious training data has not been:
- Collected (from humans for most languages, in conjunction with digital corpora for the few dozen where that is feasible)
- Reviewed (by humans)
A.I., most people in the tech industry would tell you, is the future of their industry, and it is improving fast thanks to … machine learning. But tech executives rarely discuss the labor-intensive process that goes into its creation. A.I. is learning from humans. Lots and lots of humans. Before an A.I. system can learn, someone has to label the data supplied to it. [zotpressInText item=”{5248838:UNPYMX7N}”]
AI systems to identify polyps or pornography depend on paid human labor to wade through the millions of images from which machines can learn. Kamusi has now implemented the first stage of a system that can collect granular linguistic data for all 7000 languages, to be put at the service of translation, through a suite of games and tools designed to work on any device. The work would go much faster if there were a bankroll behind it, but the principle of human collection and review remains the same with or without money:
- most linguistic data has not been digitized
- what has been digitized has generally not been regimented as interoperable data
- the data exists in human heads
- well-crafted interactive systems can enable people to transfer their knowledge to digital repositories where that knowledge can be preserved and put to use.
In the future, I expect that AI will be able to learn from a massive compendium of real, verified translations among a world of languages – but we are not there yet. We are not even close, but the prevailing fantastical belief is that GT has already brought us much of the way to translation Nirvana, and better-than-human AI-based translation for every language is just a few tweaks away.
Table 11 shows the state of the art for Google’s neural machine translation from Hawaiian to English. Hawaiian is a representative language from the lower 2/3 of my tests from English to Language X, with a Bard rating of 15, a Tarzan rating of 25, and a failure rate of 75% in that direction. The text is an authentic “hula” narrative, with simple sentences, chosen because a native-speaker had published their translation [zotpressInText item=”{5248838:K5EGHKM7}”]. The overall BLEU score is 5.69, with the best line scoring 63.89 because it identified “the woman”. As with any text, some terms will be “out of vocabulary” for the machine, but with your natural intelligence you should be able to discern three Hawaiian words for “dancing”, understand that “Nānāhuki” is a proper noun that should not be transposed to “Nephilim” (GT correctly recognizes that “Puna” is a name), and learn from line 4 to translate “wahine” as “woman” instead of “Wife” as GT posits in line 12:

Picture 57.2: Making up translations in MT is like selling motor oil in a milk bottle when the store does not have milk. Picture photoshopped from public domain images.
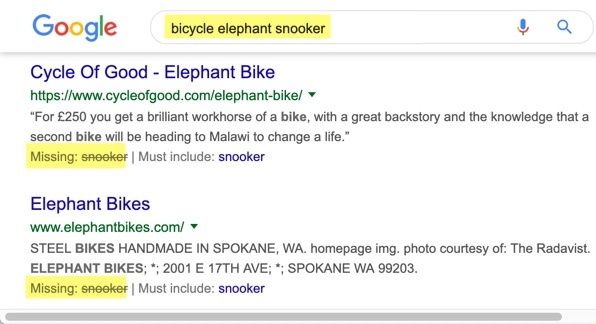
I propose that GT, Bing, DeepL, and every other MT engine should conform to a minimal standard: Scrabble rules. In competitive Scrabble, players are not allowed to use words that are not in an approved dictionary. For MT, there are two tests. First, does the word exist on the source side? In GT’s world view, the answer is always yes – we saw that they will find you a translation of “ooga booga” from any language in their system to any other, even though the term exists in none. Consumers might know that the translation of a nonsense term like “ooga booga” is bogus, but if they input a term that is legitimate on the source side (something like “brain scan” in Sinhala, say), but does not occur in the GT dataset, they have no way to know that Google is plugging that hole with random fluff. Second, if the word is in Google’s vocabulary on the source side, does a known equivalent exist on the target side? If a translation for “snookered” does not exist in French, for example, then an MT engine has no right to invent the verb “snooker”, much less to conjugate it as “snooké”. Rather, missing data should be flagged as such, so that users can see the gaps in translations that they cannot necessarily read. This technique has been engineered into Google Search, as seen in Picture 57.1 and, differently presented, Picture 49.1. Graphically, missing items could be shown inline using strikethrough (snookered) or tofu ☐☐☐☐ characters or shrugs 🤷🤷🤷, or the out-of-vocabulary items could be listed below the output. Making holes in the data transparent would increase the value of the translation, because it would show the user where to focus in the effort to achieve intelligibility.
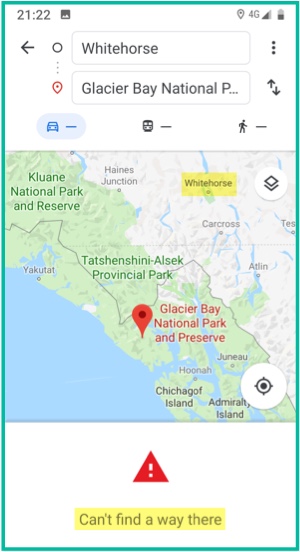
Picture 57.3. A screenshot of Google Maps showcasing the absence of a pathway between two endpoints, rather than inventing roads and bridges. (Yellow highlighting added.)
At Kamusi, it is a fundamental precept that if we do not have data for a particular sense of the term a user searches for, we show the English definition and tell the user that we do not have the data for their language yet, rather than leaving them to believe that, for example, the result we give them for “dry” meaning “not wet” can also be used for “dry” meaning “not funny”. A grocery delivery service that does not have milk cannot fill milk bottles with motor oil for its customers to pour on their breakfast cereal (picture 57.2). “We don’t know” is a valid response for a computer to provide. “Snooké” is not. One company that sometimes knows this is Google, inasmuch as Picture 57.3 shows that they inform their customers when their data does not allow them to propose a driving route between two points.
I therefore propose that MT engines, not just Google, commit to displaying a confidence index for their translations. Arguably, user satisfaction would increase if they were provided with an estimate of doubt. Surely, rather than an absence of information about how to gauge their expectations, international customers of Wish.com appreciate knowing not to hover over their mailboxes while their orders take their sweet time moseying their way from China (Picture 57.4). Translation customers would similarly appreciate an earnest gauge between believability and bunkum. I do not have a firm method in mind for how to calculate this, but it should be industry practice to provide some graphic depiction based on factors such as the amount of polysemy, the adherence to known syntactic models, and the distance within NMT between facts and inferences. People who work within MT know that every translation should be taken with some salt. The public should be able to look at the salt shaker and know how much.

Picture 57.4: Wish.com shipping notification that gives customers an estimated confidence range for delivery
Many corporations hold themselves to high standards for success. Lego, for example, has perfected its production processes to the point that only 18 bricks out of a million fail inspection – you would need to buy 55,555 bricks to see one with a chip, crack, or air bubble. The airline industry struggles to maintain on-time arrival performance against such variables as weather and mechanical issues, but that is in the cause of a greater standard at which US airlines are now nearly perfect – delivering all their passengers alive, with only one death on a large scheduled commercial flight in the US since February 2009. (Internationally, some thousands of passengers have died during this time in various large crashes.) Google, too, holds to the don’t-kill-folks philosophy in their development of self driving cars. The company will not introduce autonomous vehicles that fail to interpret a stop sign 50% of the time, or 2%, or 18 times in a million. Google is so well aware of the necessity of unassailable data for autonomous vehicles, in fact, that they subcontract a large staff in Kenya, at $9/day, to label each element of millions of photos captured with their Street View car [zotpressInText item=”{YXDDJQ9Q}”]. Der Spiegel maintains a fact-checking staff of around 80 full-time equivalents, and considers it a crisis that that bureau failed.
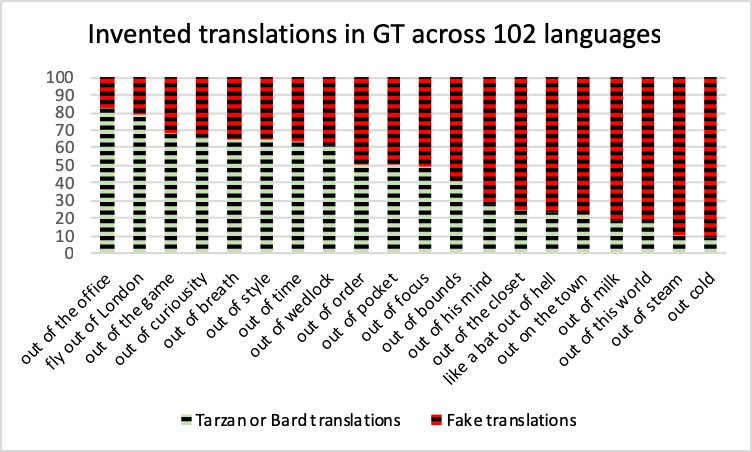
Figure 7: Proportion of test translations across all 102 pre-KOTTU languages for which the results supplied by GT were unrelated to the meaning of the candidate expression
As measured in this study, GT fails 50% or more of the time from English for 67 of the languages they list in their drop-down menus, and I extrapolate this to a 99% failure for the 5149 non-English pairs that take on errors on both sides as they transition through the English pivot. For 35 languages, the gist of English source text is transmitted more than half the time. 13 of those render human-quality translations between half and two thirds of the time. Comparable to studies that show “where there are more guns there is more homicide“, even though many bullets only cause injury or miss entirely, in MT, where there is more data there is more translation. Failures result from numerous causes, including the prevalence of ambiguous terms and incomplete linguistic data. Perhaps most problematic, the MUSA algorithm diagrammed in Myth 4, including but not limited to lei lies, is specifically geared to display invented results when no results occur within accepted statistical parameters; Figure 7 shows the rate at which GT invents translations across languages, with understandable results displayed on the bottom of each bar and nonsense data shown in red in the sky above those functional results. Stating that GT’s output predominantly fails is not meant to disparage the effort, but rather to provide an objective statement of the empirical evidence of what that effort actually achieves.
The 5 conditions for satisfactory approximations with Google Translate:7
On the basis of the empirical and qualitative research conducted for Teach You Backwards, I conclude that Google Translate usually produces acceptable conversions if the following five conditions are all met. The fewer of these conditions that apply, the less you should place credence on the GT results. Even in cases that satisfy all five conditions, errors are a constant risk, ranging from minor to serious.
- The language is at the upper tier of TYB tests, which generally indicates high investment by Google and the existence of substantial training data
- The conversion is to or from English
- The text is well structured and written using formal language and short sentences
- The text relates to formal topics
- The translation is for casual purposes where misunderstanding cannot result in unpleasant consequences
So, is Google Translate an earnest effort to set technology to the cause of multilingual communication? Yes. Do they succeed in providing understandable translations between languages? For their top languages versus English, frequently, but for most configurations GT results are like playing golf in the woods.8 Are their translations fake data? Based on empirical analysis of Google Translate across 108 languages, the conclusion is: more often than not.
References
Items cited on this page are listed below. You can also view a complete list of references cited in Teach You Backwards, compiled using Zotero, on the Bibliography, Acronyms, and Technical Terms page. [zotpressInTextBib style=”apa” sortby=”author” order=”asc”]
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- I have used “the spring in her step” for casual testing of translation services for years. GT, Bing, Systran, and DeepL all always get it wrong. They argue about which sense of “spring” and which sense of “step” to deploy, but never recognize that it is a party term with a meaning that requires deeper learning than a verbatim translation. I expect that engineers from the translation services will manually fix this particular goof for some of their languages once they encounter this footnote.
- In English: Dentist at 1pm on 7 August”. Can you guess the source language?
- Even the most exquisitely controlled vocabulary presents problems. An intern at Kamusi Labs is currently working on a tiny Facebook app with one function, to return the equivalent of “Happy Birthday” in the language a user selects among the hundreds for which we have data. It turns out that we cannot deliver the correct result in every language unless we know the (binary) gender of the speaker, the gender of the recipient, and the level of formality of their relationship. Our app has buttons for the user to make the right selection. GT does not.
- link here: https://teachyoubackwards.com/conclusions/#medical
- A Yiddish consultant commented on Picture 57, “Somehow I don’t believe this is an actual Google Translate snippet. I vote for ‘hoax’.” When he was sent the original text and ran it through GT himself, he wrote back, “OK, I was wrong. Truly strange.”
- Tristan Greene, Meta takes new AI system offline because Twitter users are mean, thenextweb.com, 19 November 2022, https://thenextweb.com/news/meta-takes-new-ai-system-offline-because-twitter-users-mean
- link here: http://kamu.si/five-conditions
- It was difficult to find an image to accompany this simile because of the ambiguity of “woods” in association with “golf” – “woods” can refer to Tiger Woods or a type of club, in addition to the forest. After some searching, I found the animated gif below to be the most illustrative picture to show likely results with GT among all but three dozen pairs. Credit: http://gif-finder.com/hitting-a-golf-ball-through-the-trees/