Facebook NMT Misrepresentation

Transcript of the language segment of “Self-supervised learning: could machines learn like humans?”
Yann LeCun, VP & Chief AI Scientist, Facebook
The chapter “Qualitative Analysis of Google Translate Across 108 Languages” quotes Yann LeCun, Facebook’s Chief AI Scientist. LeCun amplifies the misinterpretation of the research results for “zero-shot” translation as solving the question for all 25 million pairs in the grid,1 only missing by about 24,999,990, “How do we translate from any language to any other language?”, he asks. In his full explanation, based on Lample [zotpressInText item=”{RF3QWNJZ}” format=”(%d%)”], LeCun declares, “in fact, that actually works, amazingly enough!”
You can read the transcript of LeCun’s egregiously erroneous assertions below the video on this page, or watch the video here, or at online at https://youtu.be/7I0Qt7GALVk?si=HovVNYkWU31nHq78&t=1546. Segment starts at 25:30.
It should be noted that both LeCun and Lample were invited to respond to this page, but did not. However, Facebook banned the posting of a link to this page on 15 June, 2021, saying “Your comment goes against our Community Standards”. A screenshot of Facebook’s censorship is posted at the bottom of this page.
“You can see convolutional nets for other things, in particular for text, in particular for translations…
This is a system that was built at Facebook to do translation, evolving all the time. You can think of text as a sequence of symbols. You can turn it into a sequence of vectors, and then that becomes something you can build convolutions on. The cool thing about this is, there is a huge problem on Facebook, which is that we want to be able to translate from any language to any other language that people use on Facebook, and people use maybe 5000 languages on Facebook, or 7000. We don’t have parallel text from Urdu to Swahili, or something, so how do we translate from any language to any other language?
 It would be nice if there were a way of training translation systems with very little or no parallel text. And in fact, amazingly enough, that is possible. What you do is, you take a piece of text in one language, you can run what is called an unsupervised embedding algorithm. So for those of you who know what Word-to-Vec is, that’s kind of similar, but it is a little more sophisticated than that.
It would be nice if there were a way of training translation systems with very little or no parallel text. And in fact, amazingly enough, that is possible. What you do is, you take a piece of text in one language, you can run what is called an unsupervised embedding algorithm. So for those of you who know what Word-to-Vec is, that’s kind of similar, but it is a little more sophisticated than that.
You find a vector that basically encodes each word or each group of words corresponding to what context it can appear in. Now what you have is, a language is a cloud of points, right, a cloud of vectors. Now you have a cloud of points for one language, a cloud of points for another language, and if you can find a transformation that will match those two clouds of points using some distance, perhaps you will find a way of translating one language to another.
And in fact, that actually works, amazingly enough. So you do this, you get different shades of clouds of points, but there is some commonality between them which makes it so that you can transform one into the other with a very simple transformation and build what essentially amounts to dictionaries or translation tables from one language to another without ever having seen parallel text.”
Below are three examples of Facebook translation.
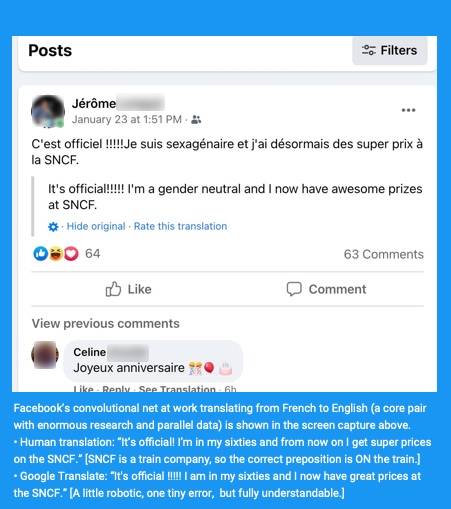
- The first is from Norwegian to English. You can quickly fathom that the poster is commenting on a new piece of state architecture, but you won’t know what she is really trying to communicate about the planned new regjeringsbyggene.
- The second example is from Reddit of a Facebook translation from Japanese to English. The original is おはよう♪今週もがんばろう! Google and Systran both give this one as “Good morning ♪ Good luck this week!”, and Bing goes with “Good morning♪ Let’s do our best this week!” Bing almost gets this one – as translated by a Japanese/Canadian bilingual speaker, the clear translation is “Good morning! Let’s do our best this week too!”
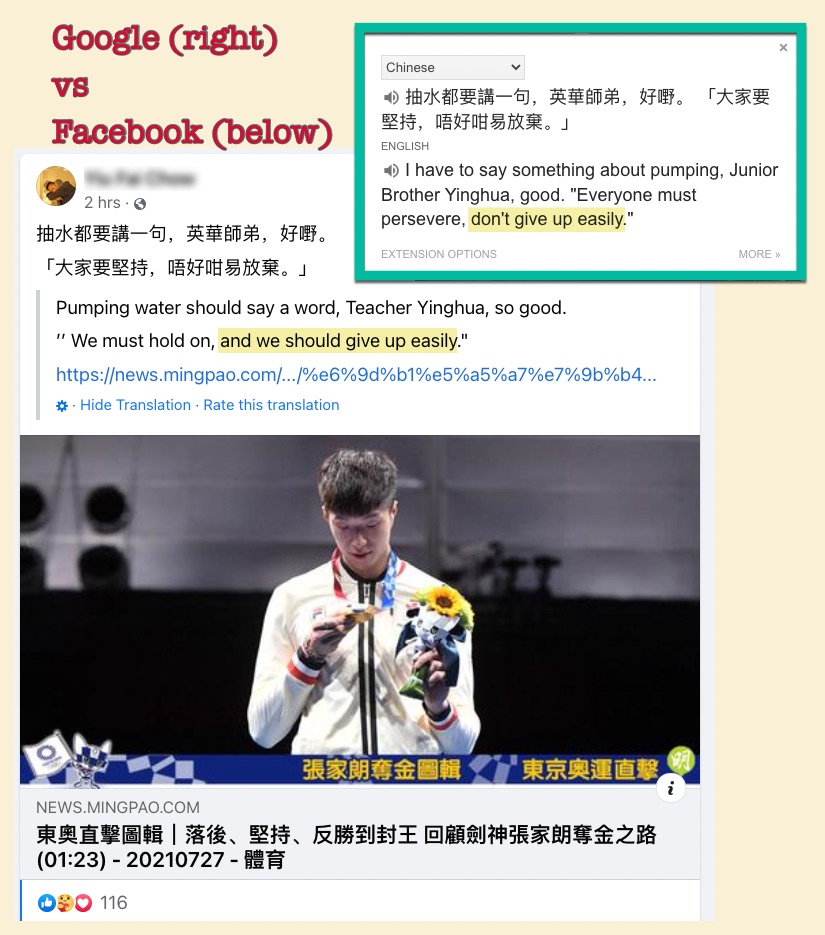
- The third example is from Chinese to English, from a Chinese article posted during the Tokyo Olympics in 2021. We can glean from the image that, in this case, Google gets the sentiment, while Facebook is off by 180°. The services mistranslate 抽水 as “pumping” or “pumping water” instead of “news-jacking”, which is more than a minor detail – the author of the post is prefacing his statement with the disclaimer that he does not wish to hijack the news to seize the glory attained by the athlete. On the same wall, on the same day, Facebook produced a translation from Spanish to English that was entirely readable, one from Arabic to English that was muddled in the details but gave the overall gist that a travesty of justice was occurring in Egypt, and one from Vietnamese to English that begins with this word jumble: “′′ VIETNAMESE DON ‘ T KNOW THE PILLOWS, HERE YOU COME, YOU WILL DIE ′′ – these are the steel replies of Heroes of the Martyrs Do Painter when Chinese army attacks and asks me for headache Goods.”
From Facebook but…thanks Cinnamoroll! from r/googletranslate
……………………………
……………………………
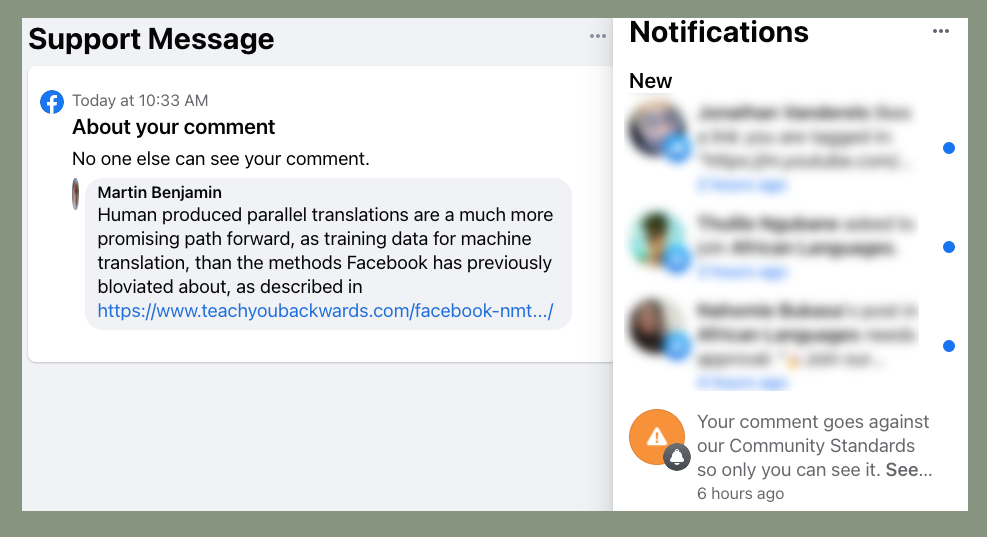
The comment above was posted on 14 June, 2021, to a Facebook discussion group that focuses on technology for less-resourced languages, with a link to this page. The screenshot above, 15 June 2021, shows Facebook’s reaction.
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- 25 million is a round number. If we go with the estimate of 7000 languages in the world, then the number of language pairs is 24,496,500 (=7000×6999/2). To arrive at 25,003,056 pairs, we would need to posit that the world contains precisely 7072 languages. Neither number is unreasonable. You really do not want to wade through the endless discussions of what constitutes a language versus a macro-language or a language versus a dialect – for example, the politics of what is often called “Berber”. Suffice it to say that neither 7000 languages nor 25,000,000 pairs are settled numbers, but are easy on the eyes and just slightly lowball the shifting total arrived at by the people at SIL’s Ethnologue – which is currently touting “7111 known living languages”, or 25,279,605 pairs .