Qualitative Analysis of Google Translate across 108 Languages


The notion that Google has mastered universal translation is built on several prominent myths. These myths feed stories that you may have seen in the press, or even heard from Google itself: earbuds that can translate 40 languages in nearly real time, underlying artificial intelligence that can teach itself any language on earth, neural networks that translate words with better-than-human accuracy, executives saying their system is “near-perfect for certain language pairs”, shining improvements from user contributions. This chapter inspects the myths, looking at what has been said versus what my research shows Google Translate (GT) has accomplished. The next chapter examines the finite limits to what GT can ever hope to accomplish using its current methods.
To make use of the ongoing efforts the author directs to build precision dictionary and translation tools among myriad languages, and to play games that help grow the data for your language, please visit the KamusiGOLD (Global Online Living Dictionary) website and download the free and ad-free KamusiHere! mobile app for ios (http://kamu.si/ios-here) and Android (http://kamu.si/android-here). How much did you learn from Teach You Backwards? Your appreciation is appreciated!:
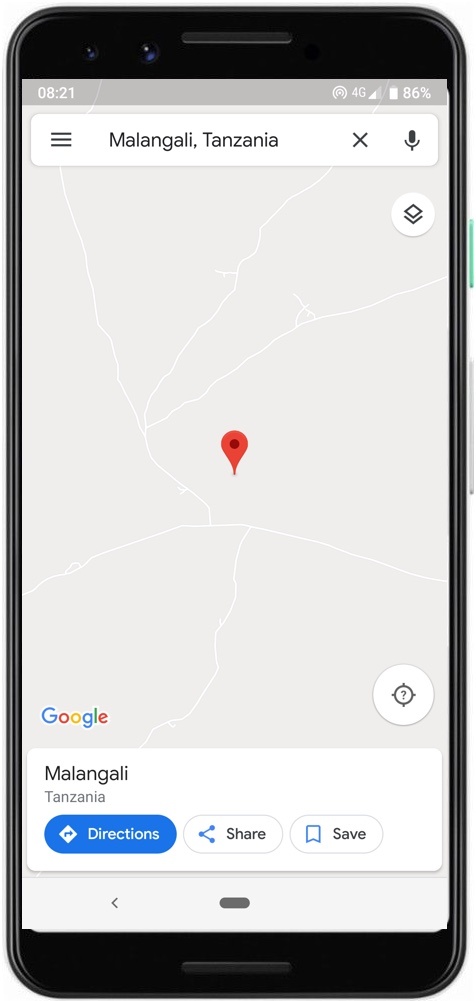
Picture 17.1: Google Maps for rural Tanzania, with about as much information, I presume, as Stanley had on his way through to find Livingstone in 1871. Detailed 1:50,000 topographic maps, produced since 1967 by the Tanzania Ministry of Lands, can easily be found and digitized from places such as Yale’s Sterling Memorial Library Map Collection.
I should preface this discussion with a note about Google as a corporation. People often view corporations in binary terms, as forces for good or forces for evil. I view Google as a disparate group of nearly 100,000 people, each doing their best on their particular project. Images, Maps, Search, self-driving cars, Android, Translate – these are all different things, all earnest efforts, and none directed by a cackling overlord in a mountain lair. Google has become huge and powerful not because it has the best solution for every market, but because it has a brilliant business model that pumps in cash that it can use to probe ever more ventures.
The corporation itself, founded in September 1998, turned 21 (the age when one is legally adult enough to drink alcohol in the US) just five days before the release of this web-book. It is not omniscient. It has failed in many efforts, such as social media, and been half-hearted in others, such as the perpetually limited functionality of Google Docs versus more robust office software. Some of its practices have seriously broken laws in dozens of countries, with billions of dollars in penalties for doing things wrong. Each thing that the corporation produces deserves to be judged on its own merits.
Google Maps for Paris is amazing. Google Maps for the area where I’ve lived in Tanzania is pathetic, as shown in Picture 17.1. While in no way reflecting badly on the Maps engineer diligently writing code in Zurich, Maps executives long ago made a decision that African villages do not have big enough markets to justify the product at the same quality they produce for Europe (87 of the world’s ~200 nations have been “largely mapped” to the Street View level); they will lend camera equipment to volunteer visual cartographers and compensate them by offering, says a product manager, “a platform to host gigabytes and terabytes of imagery and publish it to the entire world, absolutely for free,” but, as a geography professor states, “Google Maps is not a public service. Google Maps is a product from a company, and things are included and excluded based on the company’s needs” [zotpressInText item=”{5248838:PAVW7LNE}”].
When the company produces something great, they deserve plaudits. When they produce something wretched, that should be known. Nobody anointed Google as master of 108 languages – the company hired some engineers and some people with linguistic knowledge, assembled some data, and presented a product to the world. The point of this study is to figure out what is good in GT and what is wretched, and what can be done by Google or others to overcome the problems this knowledge exposes. In the interests of transparency, you should know that I have consulted with Google regarding African languages, I use a Google Pixel telephone, produced this web-book on their Chrome browser, communicated with the hundreds of people involved in this project using Gmail, distribute the empirical data from this study using Google Docs, and in many other ways benefit from and appreciate products they create. That does not mean, however, that I should hold back from investigating whether their offerings for languages from Afrikaans to Zulu live up to their promises, and for praising their efforts for the former (12.5% failure rate) while decrying as fraudulent (70% failure rate) their efforts for the latter. For people to know what they are getting when they use Google Translate, it is essential to examine where they produce results like Google Maps produces for Paris, where they merely pin a red dot on a grey background, and where they break laws in the science of translation. This study is meant to judge the quality of the translation service Google claims to provide, putting to the test their new corporate slogan, “Do the right thing“. It takes no position on whether the corporation lives up to its old motto, “Don’t be evil“.
The Dangers of Bad Translation1
Before looking at the results of the study, we need to ask why translation matters. Here I might be speaking especially to Americans, who are prone to seeing translation as an afterthought – if you just speak English louder, foreigners will understand what you are saying, and doesn’t everyone in the world know some English these days? While it might sound like a caricature, indifference to other languages pervades police departments, hospitals, schools, philanthropies, and most other walks of American life, to the point that hostility to anything but English is a common feature of the political landscape.
Elsewhere, Europe suffers from Split Personality Disorder, with Dr. Jekyll investing billions of euros for translation among languages on the continent as vital to peace and trade, but Mr. Hyde assuming that the rest of the world should fall into line behind English, French, and Portuguese. Asian countries tend to see translation with English as important for international engagement, but translation with other languages as beyond the pale of where to invest time and money – for example, the papers at the annual Asian Association for Lexicography conferences are usually about monolingual dictionaries or bilingual dictionaries vis-a-vis English. African countries, conversely, see multilingual translation as important, not just with the colonial souvenir languages but among languages on the continent, but have very few resources to put toward the cause and are resigned toward making do with the technologies that external developers such as Google see fit to produce. (I say all this based on years of engagement on all four continents mentioned. Please read Benjamin [zotpressInText item=”{AVTZA3CH},{4PKKPKD8},{VM8RCGI2}” format=”%d%”] and watch Part 1 and Part 2 of an academic workshop presentation.)
Despite these attitudes, though, migration and globalization result in millions of encounters every day where people face unpredictable translation needs – Japanese businesses with Vietnamese suppliers, refugees, workers on China’s Belt and Road Initiative, Africans seeking opportunities to move, study, or trade, Estonian tourists in the Peruvian highlands. Bad translations for tourists might be inconsequential, until they have a medical crisis. Bad translations for secondary students in Africa often mean failure for the international exams that they must take to qualify for university.
I discuss more real-world situations briefly in the embedded TEDx talk “Silenced by Language”, and expound in more detail in the bulleted paragraphs that follow, the point being that translation is not esoteric entertainment, but a vital component of communications in the modern world. It is important that the words that people believe are translations actually render the intent of what is being translated.

You expect that a product will substantially live up to the claims on its label. A badminton racket should not allow a birdie to pass through its holes. A deodorant that you apply in the morning should keep you from smelling like a goat by the time you come home. You probably do not expect a “72 hour” deodorant to actually last three days, but you would consider six hours to be a failure and 24 hours a minimum standard for usability. Unfortunately, the product shown in Picture 18 lasts not even 6 hours on a hot summer day that includes a short bike ride, and barely a full day in autumn chill without any notable sweat-making event; I, for one, will not buy it in the future. Nor will I buy sports equipment again from the superstore that sold the racket shown in Picture 17, which frequently traps the birdie between its strings instead of rebounding it into the air. The extent to which GT lives up to its label as a translator, versus the measurable rate at which it leaves you bleating like a goat, is important, because translations often have consequences. Some real examples:
-
- When Facebook mistranslated “يصبحهم”, the caption on a selfie a Palestinian man posted leaning against a bulldozer, as “attack them” in Hebrew, or “hurt them” in English, instead of “Good Morning”, the man was arrested and interrogated for several hours [zotpressInText item=”{ZZFLLGBM}”]. (I did not test translations of Arabic or any other language on Facebook, but my personal experience trying to read Arabic posts on the FB walls of friends from the region has always maxed out at Tarzan, transmitting enough of the gist for an English speaker to get the general idea of the original post.)
- When a mother and her son seeking asylum turned themselves in to the US Border Patrol, declaring that they had a fear of returning to their home country of Brazil, an agent used Google Translate to explain, as the little boy erupted in tears, that because she had not presented herself at an official port of entry, she had entered Trump-era America illegally, so she would go to jail, and he would go to a shelter. (Portuguese ranked in 3rd place in my tests from English at the Tarzan level.) It is not clear what either the mother or son understood before the boy watched his mother being handcuffed and he was abducted by the Trump administration, not to see her again for a month [zotpressInText item=”{LJPXIT4P}”]. Because many of the words that are generated by GT in Portuguese are, as found by TYB, certifiably fake data, it is almost certain that some or all of the verbiage from the uniformed kidnappers was incomprehensible, or reversed the speaker’s intent. A human translator would probably be the only legal way to make sure that the family’s rights were protected, under either US asylum law or the 1951 UN Refugee Convention. In 2019, Google declined to respond to a ProPublica investigation of the use of its services in immigration cases. However, rather than acknowledge evidence that their services were causing debilitating miscommunications in official proceedings, when Reuters asked a Google spokesperson about concerns over the use of machine translation in asylum cases in 2023, they were told that the tool underwent strict quality controls, and pointed out that it was offered free of charge (as though that were a justification – we didn’t charge for the spoiled food, so we are not responsible for the food poisoning). “We rigorously train and test our systems to ensure each of the 133 languages we support meets a high standard for translation quality,” the spokesperson said.
- Developers put enormous time and effort into preparing their Android apps to meet the requirements to appear in the Google Play store, including writing careful descriptions of their products. Google then automatically translates the descriptive content for each local market. When, after months of work, the Kamusi Here app (http://kamu.si/here) was uploaded to Google Play, we soon received mail from Romania about the incoherent product description – especially embarrassing for a product that was promising precision translation from Romanian (tied for 10th place) to dozens of other languages.
- Picture 19 shows an example of GT used in a Swedish business context. While the consequences of “an endless cat and rat anal” sound more painful than they probably are, many corporations utilize GT instead of paying professional translators, with serious ramifications for incomprehensible or patently incorrect text on the target side. An international conglomerate that owns media companies with archives of several million articles in French (French and Swedish tied for 9th) recently inquired about using GT to translate that content for its other markets, because the CEO believed Google’s assertions about the service’s capabilities; such an investment would necessarily result in a product that would be widely ridiculed and rarely purchased.
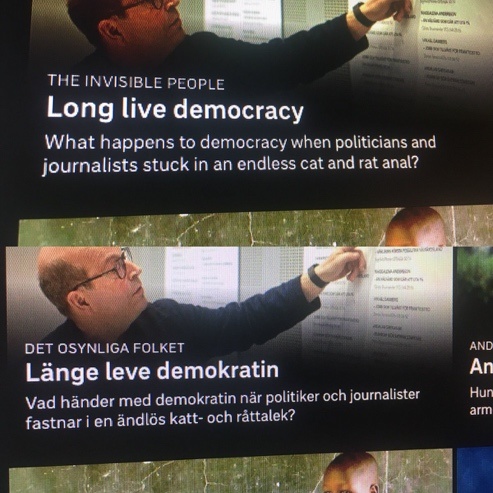
Picture 19: GT used from Swedish to English on the site of Sweden’s largest public service television company: https://www.svt.se/lange-leve-demokratin/
-
- The first Spanish-language version of the Obamacare website was apparently created via MT, leaving millions of Spanish-speaking Americans mystified when they attempted to sign up for government-mandated health care [zotpressInText item=”{SBTEXKLN}”]. (I cannot verify whether GT was the service used. The Spanish-language site has presumably been professionally translated by actual people since the initial fiasco. Spanish remains the only language for which healthcare.gov has been localized. Spanish ranked among the top 4 languages for both Bard and Tarzan scores in my tests.)
- Reports are legion of GT being used in patient/doctor interactions, with medical staff unaware that the service is not well trained in the health domain. Poor medical translations lead to overlooked symptoms, incorrect diagnoses, medications, and procedures, increased suffering, and even death. As a small example, the question in an emergency room, “How many shots did you take?” would lead to very different interventions depending on whether “shots” was automatically translated in the sense of photographs, drug injections, alcohol, or bullets. A pregnant woman looking for the delivery room at a hospital in Germany, relying on GT, would be directed to the mailroom instead (see Picture 46).Immigrants and travelers around the world interact with health services where they do not speak the language. Khoong, Steinbrook and Fernandez [zotpressInText item=”{759FWFCJ}” format=”(%d%)”] found that 8% of discharge instructions translated from English to Chinese and 2% from English to Spanish at a hospital in San Francisco had the potential for “significant harm” – Chinese being among the top 7 languages in the Bard rankings and among the top 12 for Tarzan scores. When a crisis arose after 72 hours of labor during the birth of my own daughter in a hospital in Switzerland, we were fortunate that the head doctor directed a member of the medical team with an Irish grandfather to switch to English, as neither our level of French at the time nor GT had the capacity to maneuver cogently through the situation. A study in the British Medical Journal [zotpressInText item=”{5248838:JZP4HQKT}”] that was skewed in favor of languages that performed best in our tests (European languages with the most data and financial resources) found:
Ten medical phrases were evaluated in 26 languages (8 Western European, 5 Eastern European, 11 Asian, and 2 African), giving 260 translated phrases. Of the total translations, 150 (57.7%) were correct while 110 (42.3%) were wrong. African languages scored lowest (45% correct), followed by Asian languages (46%), Eastern European next with 62%, and Western European languages were most accurate at 74%. The medical phrase that was best translated across all languages was “Your husband has the opportunity to donate his organs” (88.5%), while “Your child has been fitting” was translated accurately in only 7.7%. Swahili scored lowest with only 10% correct, while Portuguese scored highest at 90%. There were some serious errors. For instance, “Your child is fitting” translated in Swahili to “Your child is dead.” In Polish “Your husband has the opportunity to donate his organs” translated to “Your husband can donate his tools.” In Marathi “Your husband had a cardiac arrest” translated to “Your husband had an imprisonment of heart.” “Your wife needs to be ventilated” in Bengali translated to “Your wife wind movement needed.”

Picture 20: A clue in The Atlantic Crossword that came from GT, not actual French (16 November, 2018)
-
- The Fourth Amendment of the US Constitution prohibits searches and seizures without a warrant. A person who agrees to a warrantless search must provide consent knowingly, freely, and voluntarily. After a police officer used GT on a traffic stop to request to search a car, resulting in the discovery of several kilos of drugs, a Kansas court found that GTs “literal but nonsensical” interpretations changed the meaning of the officer’s questions, and therefore the defendant’s consent to the search couldn’t really have been knowing [zotpressInText item=”{4EN7H4EA}”]. Nevertheless, the top judge of England and Wales has stated, “I have little doubt that within a few years high quality simultaneous translation will be available and see the end of interpreters” [zotpressInText item=”{EUMUMYUV}”] (Welsh ranked 8th). If courts around the world come to accept that MT provides adequate legal understanding, miscarriages of justice will inevitably ensue.
- Nearly 90% of students learning languages in one US university report that they commonly use online translators as an aid in their studies) [zotpressInText item=”{MAU63N74}”]. When used cleverly to home in on potential vocabulary and sentence structure, GT and its cohort can help with language learning. However, many students use GT the way they use a calculator, to perform rote computations and accept the output uncritically. 89% of 900 students surveyed at another US university reported using GT as a dictionary, to look up individual words and party terms [zotpressInText item=”{IWCY3KIK}”]. GT is not a dictionary. Its results for single words are statistical best guesses with a high chance of failure, and its results for party terms are generally catastrophic. A calculator will always return correct results: 2+2=4. This is patently not the case for GT, where 2+2=i in the proportions I measured for each language. The consequence is that students learn and hand in assignments using a simulacrum of their foreign language rather than the language itself.
-
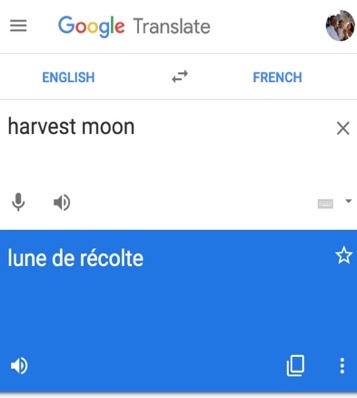
- GT is blithely used as a go-to source for translations that end up in publications or other professional contexts. An example is shown in Picture 20, where the crossword editor of The Atlantic, a prestigious US publication, ran with GT’s rendition of “harvest moon” in French as “lune de récolte”, instead of “lune des moissons” as expressed by actual French speakers.2 It is true that lune=moon and récolte=harvest, but putting those two together as a translation of the English party term is a fake fact, an invention by a machine. GT is the only place on the Internet that makes the pairing posed by The Atlantic, but their puzzle creator did not know that because, unaware that the MUSA Make Up Stuff Algorithm is designed to fabricate a cosmetic response when the data falls short, he trusted GT when he made his clue. Then (as kindly confirmed by their fact checking department), the fact was checked using GT, and of course this alternate reality creation confirmed itself as French. Especially for party terms, proper translation often is not possible to obtain using standard search techniques. For example, Linguee does not have a large repertoire of English source documents containing “harvest moon” that have been translated to French, even proposing texts involving UN Secretary General Ban Ki-moon for consideration. “Harvest moon” is a subsection of “full moon” in the English Wikipedia, from where the interwiki link to French reaches the general concept of “pleine lune” – there is no pathway for a computer to use Wikipedia to infer a bridge between the concept as expressed in English and the way it expressed in any other language. Nor does the term appear in a battery of print or online dictionaries. Companies frequently consider GT outputs to be facts because they come, as in Picture 21, with an almost trillion dollar imprimatur that has surface visual resemblances to the outputs of deep lexicographical research at Oxford or Larousse, rather than, as in Picture 22, verifying translations with actual speakers. Human translations can be time-consuming and costly, but the consequences of machine mistranslations, in contexts more significant than the daily crossword, can be more so.
- “Latino outreach or Google Translate? 2020 Dems bungle Spanish websites” [zotpressInText item=”{I8V9RSWE}”]. The headline says a lot, but it is worth giving the full Politico article a read. Several contenders to be the Democratic presidential nominee in 2020 were found to have used GT for the Spanish-language versions of their websites. In the three cases where Rodriguez shows side-by-side translations from GT and the final web version, only Cory Booker followed the recommended procedure of using the MT service as a convenient starting point from which to embark on radical human post-editing with a knowledgeable speaker (if Booker’s team used GT at all, because the similarities are words a human translator would also likely have chosen). Julián Castro at most changed four words in the passage Politico analyzed (or GT was in a different mood when his translation was run versus when Rodriguez tried it, as often happens), and Amy Klobuchar did a pure copy-and-paste. Castro got lucky with a high-Bard output, while Klobuchar’s text literally stranded her in the middle of the Mississippi River. What is noteworthy is that these are serious political campaigns seeking to woo the votes of a substantial part of their electorate, and raising millions of dollars to spend on persuasion. They, or their staff, went to GT with the belief that the output was human caliber, and that finding a qualified volunteer or investing a small amount for a professional translator was an unnecessary step. Rodriguez’s reporting prompted most of the campaigns to abandon GT in favor of humans going forward, but botched outreach courtesy of GT will inevitably come back around for future candidates.
- And then there’s this:3
Why is #googletranslate doing me like this.
This is not what I said ..🤦🏿♂️ pic.twitter.com/OXjF3vwGHS— 沃爾特 (@a1kindoe) September 20, 2019
- And this (Maltese tied for 9th), which Air Malta quickly fixed once they learned they were selling seats to non-existent cities: https://lovinmalta.com/humour/now-boarding-to-sabih-air-maltas-translate-mishap-creates-a-bunch-of-new-european-cities/
- And this (Galician tied for 9th): https://www.thelocal.es/20151102/galicia-celebrates-its-annual-clitoris-festival-thanks-to-google-translate
- And the video below. Airline safety instructions may be tedious, but they are important. If you ever fly Kenya Airways and see a placard regarding “Life Vest Under Center Armrest” in Swahili, please feel secure that considerable effort went into ensuring that every piece of signage communicated the exact intent.
The examples above show that translation is often a deadly serious activity with substantial consequences in the real world. Many of the puzzles in MT do not harm the lives of computer scientists or journalists if the solutions are imperfect, however, so the experiments that raise the bar are venerated as research success even though the outcome fails its consumers at the rates I have measured. An error that reverses the meaning of a randomly chosen text might be just one word in an otherwise Bard-level translation, and affects GT engineers as little as the small software error in the stabilization system of the 737 MAX affected the Boeing executives who swore that travelers had nothing to fear after the first crash of their jet, in Indonesia. It is entirely conceivable that an airplane could crash someday because a maintenance worker followed an instruction that was erroneously translated by GT, similar to a 1983 near disaster when ground crew read the number in their fueling instructions as lbs instead of kgs during Air Canada’s transition to the metric system.
The public has a confidence in MT, particularly in GT, that has not been earned. This confidence is built on several foundational myths:
Myth 1: Artificial Intelligence Solves Machine Translation4
AI is the big buzz in computer science these days, eclipsing the enthusiasm for Big Data earlier in the decade. Some recent headlines about AI and machine learning exhibit the current hype:
- How to solve homelessness with Artificial Intelligence
- Artificial Intelligence can help in fight against human trafficking
- Machine learning is making pesto even more delicious
- What can Artificial Intelligence do about our food waste?
- How machine learning and the Internet of Things can help the world’s poorest people
- How Artificial Intelligence can save our planet
Students looking for internships regularly approach Kamusi Labs in hope of a project that combines AI and NLP. I must always point them in other directions because, at this moment and for the foreseeable future, AI is impossible for most MT and other NLP tasks. I hear your shrieks: many interesting advances have already been made! Yes, I reply, if you constrain your scope to English and a few other investment-grade languages – and even then, impressive linguistic feats cannot crash the barrier of meaning [zotpressInText item=”{H9CLJ3RK}”]. For most languages, and even for a lot of activity relating to English nuance, there is no scope for AI because there is not enough data on which a machine can act – regardless of headlines such as this from MIT Technology Review [zotpressInText item=”{5248838:PCIUNFI2}”]: Artificial Intelligence Can Translate Languages Without a Dictionary.
Additionally, the phrase “machine learning” as it is usually applied to MT is a misnomer. In most contexts, “learning” implies that knowledge has been ascertained, whereas in MT the data has merely been inferred. No teacher is standing by to either guide or correct the inferences. Consider: my nine-year-old does not have English instruction at her Swiss public school, so she learns the written language by reading books to me at home every evening. The only way for this to work, though, is for us to sit on the couch together so that I can help her through tough words like “though” and “through” and “tough“.5 Without a teacher at her side, she would make guesses at such words that would often be wrong, but that she would lock into her head as fact – she’ll have “learned” the wrong thing. I can think of many things that I “learned” wrongly by inference – thank you to my grandmother, an English teacher, for her yeoman’s work catching my writing errors all the way through graduate school, such as using “reticence” when I meant “reluctance”. We can feel empathetic embarrassment for the narrator on This American Life6 for his assumption that “banal” does not rhyme with the word it most resembles, keeping in mind the aphorism that “assume” makes an ASS out of U and ME; we can hope he learned from someone gently correcting him after his broadcast, but also fear that some listeners learned the mispronunciation from hearing his bungled English.
Yet, when AI computes associations between languages that are presented as data without any human verification, data science writers tout it as gained knowledge, in confidently written reviews such as “Machine Learning Translation and the Google Translate Algorithm” [zotpressInText item=”{5248838:XBCD3D89}”]. Consider: in the TYB test, GT translated “out on the town” into Dhivehi as “ރަށުގެ މައްޗަށް ނުކުމެއްޖެއެވެ”. Our evaluator gave that a C rating, completely wrong, and translated it back to English as the word-slaw “came out top of the island”. GT’s reverse translation back to English, though, is “out on the town”, which has nothing to do with what a Dhivehi speaker sees or infers. Obviously, GT taught itself from its own faulty translation (perhaps when I ran the phrase to prepare the evaluation document) – the computation decided “out on the town” is ރަށުގެ މައްޗަށް ނުކުމެއްޖެއެވެ , so therefore ރަށުގެ މައްޗަށް ނުކުމެއްޖެއެވެ is “out on the town”, q.e.d., machine learning in action. Unless you are one of 340,000 Maldivians, you don’t speak Dhivehi, while GT has “learned” the translation. Who are you to question Google?
As you continue reading, please keep in mind any indigenous African language of your choosing. Africa is home to roughly 2000 languages, spoken by approximately 1.3 billion people.7 About 5% of the continent is literate in one of the colonial souvenir languages (English, French, or Portuguese), with no indication of that number increasing significantly for new generations. A few languages have contemporary or historical written sources that could become viable monolingual digital corpora at the service of NLP (limited corpora exist for Swahili8 and a few other languages in forms that could be exploited through payment or research agreements), but none have substantial digitized parallel data with any other language. 12 African languages have words in GT: Afrikaans (a sibling of Dutch and the best-scoring language globally in TYB tests), Arabic (which straddles Africa and Asia and had a 60% failure rate), and 10 languages that originated on the continent: Amharic (60% failure), Chichewa (70% failure), Hausa (65% failure), Igbo (40% failure), Malagasy (60% failure, which makes it better than the 5.5 million pellets of robot-produced space junk that is the Malagasy Wiktionary), Shona (70% failure), Swahili (75% failure), Xhosa (77.5% failure), Yoruba (70% failure), and Zulu (70% failure). It would be racist to posit that Africans speak languages that are so much more complicated than those that have already experienced NLP advances, that it would be too difficult to extend systems originally engineered for the more feeble minds of Europe. It would be racist in the other direction to assert that Africans do not deserve to be included in global knowledge and technology systems because they do not speak languages that wealthy funders choose to invest in. Your mission as you read, then, is to envision how your chosen African language can effectively be incorporated within the realm of MT, so that its speakers can communicate with their African neighbors and with their international trading partners.
You may extend this mental exercise to any of the thousands of non-market languages of Asia, Austronesia, or the Americas. With around a quarter billion native speakers, Bengali is a good candidate. Hakka Chinese, one of China’s 299 languages, with 30 million speakers (more people than Australia and New Zealand combined), is another good example, as would be Quechua spoken by about 10 million people in South America. The exercise can also be brought to Europe, for example regarding around 7.5 million people who speak Albanian. Which of these languages is too complicated for ICT? Which people would you choose to exclude? If your answer to those questions is “none”, read on with an eye toward why current technologies have failed each of these languages, and what among existing or realistic technologies can be implemented for them to reach parity within the computational realm.
Consider these scenarios:
1. A language with virtually no digital presence – the majority of the world’s languages.9 The first step in digitizing thousands of languages is collecting data about them: what are the expressions, what do they mean, and how do they function together? Without a large body of coherent data, a machine could not even perform basic operations on a language. For example, it cannot put all the words in alphabetical order if it does not have a list of words. Digital information for perhaps half the world’s languages consists solely of metadata – where it is spoken, how many speakers, language family – the minimal information that someone who knows something about linguistics has gathered sometime in the past 150-ish years to determine that Language X exists and is distinct from its neighbors. Machines cannot pluck data out of the ether. Surely you will agree that AI is impossible in this situation.
2. A language with some digital presence, but no coherent alignment to other knowledge sets.10 For example, the language might have a digitized dictionary, and that dictionary might indicate that the basic form of a word matches to an English word such as “light”. There is still no basis for a computer to infer whether that is light in weight, or in color, or in calories, or in seriousness. Nor could the machine begin to guess aspects such as plural forms or verb conjugations, much less the positions of words to form grammatical sentences. Most digitized linguistic data exists in isolated containers that, you will probably agree, AI does not have the basis to penetrate. As a human who has mastered languages and knows what research questions to ask, you could stare at someone else’s dictionary for weeks on end and gain no traction in conversing in their language. Although we might regard them with mystical talismanic power, computers have no magical ability to spin gold out of floss.
As a case study, consider how to treat the Sena language spoken by 1.5 million people in Malawi and Mozambique. Religious organizations have published an online Bible, and audio recordings of Bible stories. The Bible has been parsed into words that are listed by frequency, in files available at http://crubadan.org/languages/seh. A 62 page Portuguese-Sena print dictionary from 2008 is available in the SIL Archives in Dallas, Texas, and a 263 page Portuguese-Sena/ Sena-Portuguese print dictionary, completed before 1956, is available in the Graduate Institute of Applied Linguistics Library, also in Dallas. 15 articles about Sena are listed at http://www.language-archives.org/language/seh, including one from 1897 and one from 1900. The only study that is available in digitized form is a scan of a book chapter written in German and Portuguese from 1919, that you will want to look at to visualize the technical challenge of extracting operationalizable linguistic data or models.
You have before you the sum total of resources for Sena. You are now challenged to lay out a strategy to use AI to produce an MT engine for the language. You cannot do it. Neither can Larry Page11 and a phalanx of his engineers at Google. Again, AI is impossible in this situation.
Picture 24: Ambiguity that natural intelligence can slice through in an instant, but is opaque to AI.
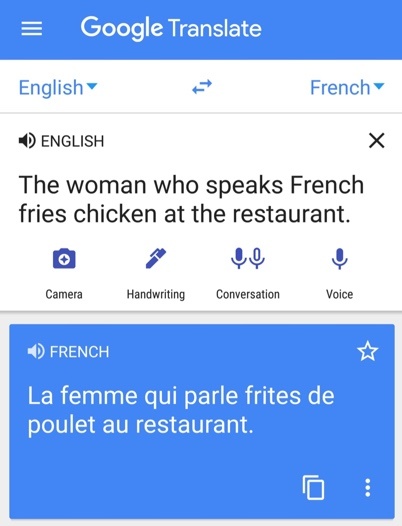
3.12 A language with considerable digital presence. Here we can begin to see the possibilities for the computer to make some high-level inferences. For example, with a large text corpus, a machine could learn how a language speaks of potatoes. Seeing that a language has baked, boiled, fried, or couch potatoes, and that chicken can also be baked, boiled, or fried, AI can even surmise the existence of couch chickens. However, unless there is a lot of parallel information, you should still agree that AI will be ill-equipped to fathom that “French fries” might or might not refer to deep-fried potatoes that have particular translation equivalents in other languages that have nothing to do with France (see Picture 24).
Parallel data opens doors for machines to learn patterns between languages. However, these patterns will always be limited to the training data available – direct sentence-aligned translations between two languages, or potentially a somewhat wider relational space with NMT. (The case of “zero-shot translation”, with nonsensical results , relies on two stages of direct translations, with the third (bridge) language removed after training.) The largest set of topically related multilingual data outside of the official European languages, Wikipedia, is entirely unsuited as a source for MT training. To glimpse inside the major parallel datasets on which MT is actually trained, spend some time trying words and phrases on Linguee.com. Compare the areas that Linguee highlights in yellow as translations from the source side to the target side, as shown in Picture 25. These are extremely useful when you filter with your natural intelligence, but are devilishly difficult for the machine to match with certainty, because:
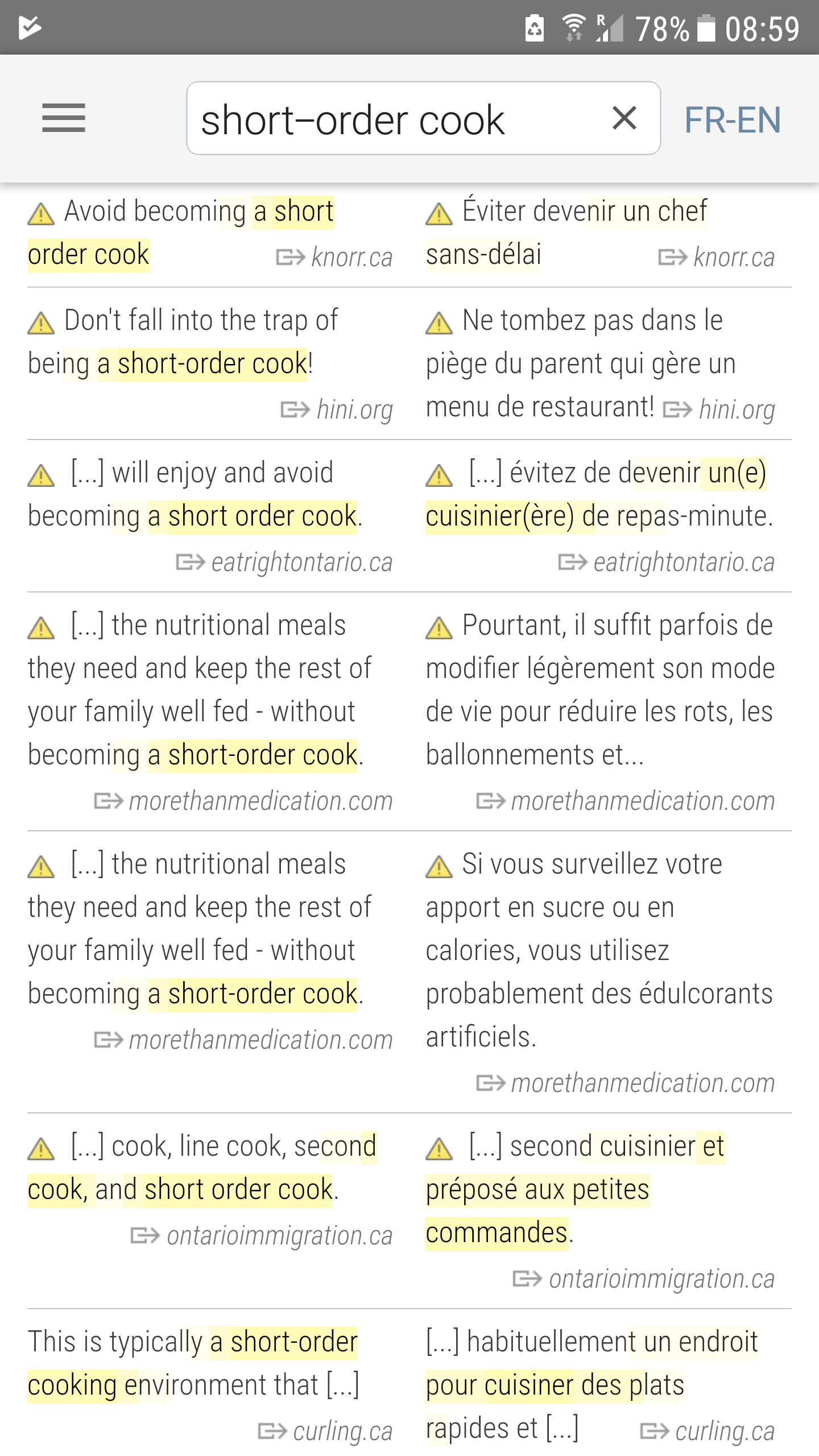
Picture 25: Results for “short-order cook” in Linguee. The best translation is “cuisinier(ère) de repas-minute”. Notice (a) that translation occurs only one time, and (b) making the translation useable, in this case factoring around the parentheses for gender, would require human intervention. It is worthy of note that all of the valid translations come from Canadian sources, where greasy spoons are popular, and none from France, where a short-order cook would be summarily guillotined. Also, do not hire whoever was responsible for the translation on the second line.
- one source phrase might be translated in many ways (in a lot of ways, in a variety of ways, in multiple ways, varyingly) by different people across source documents
- current algorithms cannot identify most party terms, especially those that are separated (e.g., “cut corners” can be separated by one or many words: “Boeing executives wouldn’t let the engineers do their job and they cut those deadly corners on the 737 MAX 8.”13).
- the source phrase might be rare within the training corpus, without enough instances for a machine to detect patterns. This is especially true for:
- colloquial expressions, which might be used all the time by regular folks but are frowned on in the formal documents that enter the public record
- ironically, American English expressions, often missing because the most-translated texts come from official EU documents where UK English is standard. For example, people don’t “call an audible” when they change plans at the last moment in the UK, so the expression does not make it into parallel corpora, and (look yourself) GT translates the words devoid of the meaning of the expression in all languages
- non-English as the source. Although every language has its own set of complex expressions, only the most powerful are likely to be the source of widespread official translation. For example, all EU documents must be translated to Lithuanian, but they are likely to start out in English, French, or German; precious few documents start in Lithuanian for translation throughout the EU language set. If you can find a source of party terms for a non-investment language such as Kyrgyz, much less their translations to any other language, please sing about it in the comments section
- the machine can pick out the wrong elements on the target side as the translations
- polysemy: one word or phrase with several meanings
Using some test phrases that are evident to most native English speakers (e.g.: chicken tenders; short notice; hot under the collar; off to the races; mercy killing; top level domain; short-order cook), you can see in Linguee that current parallel corpus data is probably sufficient for AI to learn from human translations from English to French for mercy killing and top level domain, maybe for short notice, highly doubtful for chicken tenders (see Picture 45), and inconceivable for hot under the collar, off to the races, or short-order cook. AI can discover many interesting patterns that can be combined with other methods to advance translation where data is available (for example, short-order cook could be mined from Canada’s official Termium term bank), but it can only ever be a heart stent, not an entire artificial heart.
Swahili is a good case study of a language with a lot of digitized data. Kamusi has a database with rich lexical information (such as noun class designations) for more than 60,000 terms, as well as a detailed language model that has been programmed to parse any verb; unfortunately, funds for African languages are so dry that the data has been forced offline. TUKI [zotpressInText item=”{JX3GIVM2}” format=”(%d%)”], an even more extensive bi-directional bilingual dictionary between English and Swahili, from the University of Dar es Salaam, is available, but entries are bricks of text that can barely be interpreted by a knowledgeable bilingual human, much less by a machine (see Picture 26). An open monolingual Swahili corpus based on recent newspaper archives is being constructed at http://www.kiswahili-acalan.org, and an older corpus is available for research purposes, with difficulty, via https://www.kielipankki.fi/news/hcs-a-v2-in-korp. No parallel corpus exists with English, though one could probably be created as a graduate project using the digitized archives of the Tanzanian parliament and other well-translated government documents.

Picture 26: Partial entry for “light” from TUKI English-Swahili Dictionary.
Swahili has research institutes, a large print literature, an active online culture, a moderate investment in localization from Google and Microsoft, and crowdsourced localization by Facebook and Wikipedia (full disclosure, I have been involved in all four of those projects). Currently, GT and Bing both offer Swahili within their translation grid, but the results are only occasionally useable.
For example, for an article in the Mwananchi newspaper about prices for the crucial cashew crop, GT translates the fifteen occurrences of “korosho” (cashews) as riots, crisis, vendors, bugs, cats, cereal, cuts, raid, and foreign exchange, or leaves the term untranslated, but never once uses the word “cashew”. Meanwhile Bing recognizes the central word, and gives a passable rendition in English at the Tarzan level (one knows that farmers are facing insecurity selling their crop because of fluctuations in the international market) – but uproariously translates the word “jambo”, which has its major meaning in written and spoken Swahili as an issue, matter, or thing, as “hi”. ( “Jambo” is the tourist version of a complicated Swahili greeting based on negating the verb “kujambo” (to be unwell), which Kamusi log files confirm is a lead search term for first time visitors, and which Bing has evidently chosen to hard-code regardless of context.)14
Google claims that Swahili makes use of their neural network technology, but that technology is clearly mimicking the brain of some lesser species. In fact, it may be that the technology is actively delivering worse results, by finding words that occur in similar vector space; in tests using the word “light”, in cases where GT actually picks up the right sense, it delivers the Swahili equivalent of the antonym heavy when the context is weight (“light load” is rendered as a heavy load, “mzigo mzito”) and the antonym harsh when the context is gentle (“light breeze” is rendered as a harsh wind, “upepo mkali”). The question is, with proper attention and the digitized resources at hand, could AI make significant headway? To the extent that a clever algorithm was set to work finding patterns within the corpus, then calculated rule-based connections through the lexical database that links to English, a much smarter MT platform could emerge. Creating such a system, though, would demand a lot of human intervention – the computer is the tool, but that tool needs an artisan to craft with it. AI can aid MT for those few language pairs that have significant parallel data, but it is not a stand-alone solution.
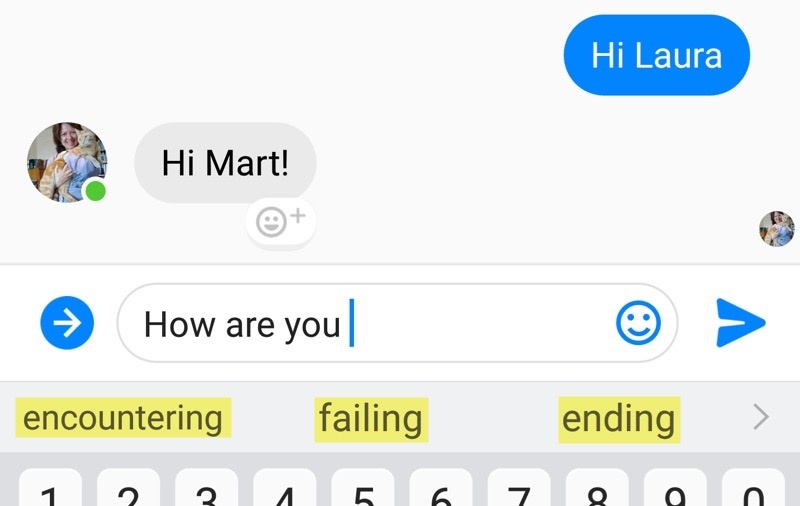
Picture 27: English predictions based on AI might include “doing”, “feeling”, and “today”, rather than the options captured in this image from an Android phone.
4. The best-resourced language.15 English provides many cautionary examples showing why you should be skeptical of the notion that AI is the cure for NLP. Think of all the ways you interact with machines in English that, after decades of intense research and development, do not yet work as envisioned. Speech recognition, for example, causes you cold sweats whenever you are asked to dictate your sixteen digit account number into a telephone, although in theory AI should be able to interpret sounds to the same extent that it can recognize images.16 Word processing software that learns from people should be able to flag when you have typed that someone is a good fiend rather than a good friend, and learn from millions of users repeatedly mistyping and correcting “langauge”. Auto-predict should know that “fly to” is likely to be followed by one of a limited set of cities, and “fly in the” will call for ointment or afternoon. Google combines language processing and some AI brilliantly in its English search – figuring out the relevant party terms, correcting typos, and combing your personal data to provide you results based on your movements, purchases, and perceived interests. Take it from their research leaders: “Bridging words and meaning — from turning search queries into relevant results to suggesting targeted keywords for advertisers — is Google’s core competency, and important for many other tasks in information retrieval and natural language processing” [zotpressInText item=”{386P2DAL}”]. Yet still, Google Search frequently misses; to find out about fruit by typing in “apple” you will need to do some serious scrolling, and be prepared for an ad hominem slur on 1.8 billion people if you seek to learn the difference between Shia and Sunni (Picture 28).
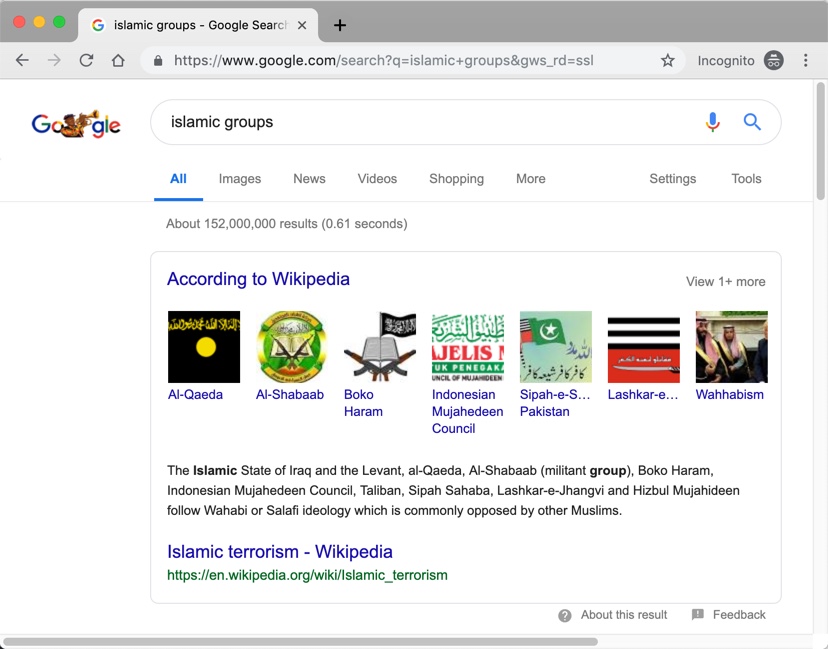
Picture 28. Google Search uses their NLP machine learning techniques to parse the user’s search term and give a phenomenally offensive first result for “Islamic groups” (4 April, 2019). Search results may vary depending on your location, your browser history, the processor’s mood, or whether someone at Google has seen this image and taken corrective action.
When it works – when you say “tell my brother I’ll be ten minutes late” and it sends an SMS with the right information to the right person – you feel as though yesterday’s science fiction has become today’s science fact. Yet you know enough to not really trust the technology at this stage in its development. You would be a fool not to double check that your message was sent to the right person with the right content. During a pause while writing this paragraph to send a WhatsApp message to someone that “I will be in U.S.”,17 the phone proposed that the next thought would be “district court”, an absurd prediction for most people other than an attorney or a member of Donald Trump’s criminal cabal. For AI to make actual intelligent predictions [zotpressInText item=”{CQCEJ6R4}”] for your texting needs, your phone would merge billions of data points from the consenting universe of people sending messages, combined with your personal activity record, and recognize that “for Mary’s wedding” or “until the 30th” would be more appropriate follow-ons to “I will be in [place name]”. (See McCulloch [zotpressInText item=”{5248838:DQYVC53G}” format=”(%d%)”] for a nice gaze into autocomplete.)
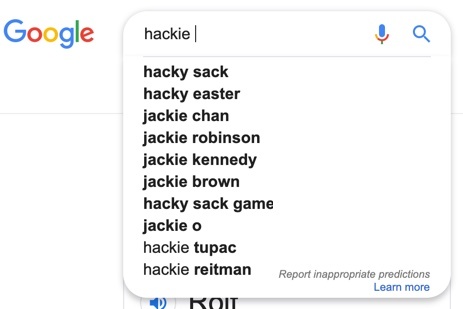
Picture 28.1: The magic of Google Search is an interactive process between user and machine, teaming computation and natural intelligence to whittle toward relevance.
In fact, much of what seems like AI magic in Google Search is actually Google casting a wide net based on their huge database of previous searches, and using your personal knowledge of your personal desires for you to select the intelligent options from the many off-base ones also on offer. Examine Picture 28.1: Google knows that people who have searched for the term “hackie” have ended up clicking most frequently on “hacky sack”, so that is the top result they propose. Previous searchers have evidently also back-tracked and ended up looking for “jackie”s instead, even more so than hunts for people whose name is actually spelled “Hackie” as typed by the user (such as Tupac Shakur’s bodyguard). If you were looking for Jacqueline Kennedy Onassis and had started by typing “hackie”, you would think that Google was genius for suggesting her. If you were looking for “hacky sack”, you probably wouldn’t even notice that “jackie o” was one of your options. Getting you to your destination relies on a few tricks that may involve brute frequency counts (e.g. 47% of “hackie” searches end up at “hacky sack”), some NLP (e.g. “hackie” could be a typo for “hacky” or “jackie”), or even some AI (e.g. “hackie” could be a typo for “hacky” and we have detected a trending site called “Hacky Easter“). The proposal “hackie tupac” clearly appears because previous users had not found the man they were looking for until they used the modifier of his famous employer, thereby using their natural intelligence to train Google.
You can try the magic yourself: do a search for “Clarence Thomas”, then search for “Ruth Bader Ginsberg”, then search for “John Roberts”, and finally search “s”. Do your choices include “Sonia Sotomayor”, “Stephen Breyer”, “Samuel Alito”, and “supreme court justices”? Pretty cool, no? The biggest trick to matching you to the information you are seeking, though, is that your own eyeballs scan the 10 options Google presents, sends those signals to your brain, and your flesh-and-blood neural network processes the options and makes the intelligent decision. When your search fails – when you want to know why the devil is called Lucifer but searching Google for Lucifer only gives you information about a TV show by that name – you simply refine your search to “lucifer devil” and write off the cock-up. Google Search is awesome, and certainly involves increasing use of AI to find patterns that respond to what is on your mind, but that is a far cry from the notion that AI can now, or in the future will be able to, predict your thoughts better than you can yourself.
The brilliant citation software Zotero (https://www.zotero.org) demonstrates the difficulties.18 The task for Zotero is to find information on web pages and pdfs that can be used for bibliographic references. That is, Zotero searches for specific elements, such as title, author name, date of publication, and publisher. The program is aided by frequently-occurring keywords, such as “by” or “author”, and by custom evaluation of the patterns used by major sources such as academic publishers. Even so, Zotero often makes mistakes. For example, sometimes it cannot identify an author who is clearly stated on the page, sometimes it will repeat that author’s name as a second author, and sometimes it will miss one or more additional authors. Zotero assigns itself one job, in one language, and it does that job as well as any user could hope. Nevertheless, it is unable to overcome the vast multiplicity of ways that similar data is presented on similar websites; non-empirically, at least half the references in this web-book needed some post-Zotero post-editing. A next-generation Zotero could conceivably use ML for an AI approach that homes in on recognizing how diverse publications structure their placement of the author names variable, but better resolution of this one feat in English text analysis is akin to landing a probe on a single asteroid as a component of charting the solar system.
Systems are constantly improving to recognize increasingly subtle aspects of English, because the language has enormous data sets and research bodies and corporate interests with extraordinary processing power to devote to the task, but it is crucial to recognize that (a) English is not “language” writ large, but a uniquely privileged case, and (b) analysis of a single language is just the train ride to the airport, while translation is everything involved in getting you into the stratosphere and landed safely across an ocean. The New York Times, speaking of English, states that Google’s “BERT” AI system “can learn the vagaries of language in general ways and then apply what they have learned to a variety of specific tasks,” but then goes on to say they “have already trained it in 102 languages” [zotpressInText item=”{CQCEJ6R4}”]. Looking at what BERT has actually done for those languages,19 however, shows much less than the comprehensive language data you might expect would aid in the analysis of “the vagaries of language”: Wikipedia articles, which are next to useless as a corpus resource for comparing languages (you can read a detailed side article written to justify this statement) have been scraped and processed with a number of reductionist linguistic assumptions (e.g. no party terms) that invalidate any glimmer of adhering to science. Nevertheless, the New York Times journalist continues to repeat his formulation that “the world’s leading A.I. labs have built elaborate neural networks that can learn the vagaries of language” [zotpressInText item=”{5248838:AU9KL5BA}”] – conflating the ability to learn from vast troves of English text with the ability to learn any of the languages a bit farther to the right on the steep slope of digital equity. We are still far from AI that comes close to producing English with a speaker’s fluency, or recognizing nuances when a person strays off the text or acoustic patterns our devices are trained on. We know this, and we laugh about it, with funny tweets about Alexa and autocorrect, or this video employing the latest AI from 2022 on one relatively simple linguistic task in English:
Google puts some of the same NLP that it uses for search into English-source GT (e.g. recognizing “French fries” as a party term in some cases), but the service is a long way from interacting with English with a human understanding. What is not done with English is by default not replicated to any of the top tier languages discussed in point 3 above, and most certainly does not trickle down to data-poor or data-null languages. In the words of noted AI researcher Pedro Domingos [zotpressInText item=”{9VKF36X5}” format=”(%d%)”], “People worry that computers will get too smart and take over the world, but the real problem is that they’re too stupid and they’ve already taken over the world.”
Nobody recognizes the need for good data as essential for good AI, in fact, more than Waymo, Google’s autonomous car division. Waymo has decided that it would be bad for their driverless cars to kill people. As part of the billions they are investing in designing vehicles that can interpret every road sign, reflection, and darting dog, they hire a bureau of Kenyans at $9/day to label each element of millions of pictures taken by their Street View cars [zotpressInText item=”{YXDDJQ9Q}”]. There is nothing artificial about the intelligence of the people who spend their days telling Google what part of an image is a pothole and what is a pedestrian. The AI comes in later, when the processor in a car zipping down the street has to interpret the conditions it sees based on the data it was trained with. It is not such a leap to assert that effective translation is impossible without data similarly procured from natural intelligence. Google hires its Nairobi employees for $9/day to make it safe for Californians cruising to the mall to stare at their phones instead of watching the road. They could easily double their staff and pay $9/day for linguistic data from Kenya’s large pool of unemployed, educated youth to power NLP for Kenya’s 60-odd languages. That they choose not to do so is not an indication that they have mastered AI with their current techniques, but rather that they do not see the investment in reliable translation to yield the same return as investment in non-lethal cars. As long as people believe the myth that AI has conquered or soon will conquer MT based on the current weak state of data across languages, rather than demanding systems that have a plausible chance of working, such mastery will never occur.
“Latest Planes Herald New Era of Safety: With Inventors’ Producing Foolproof, Nonsmashable Aircraft, Experts Say We’ll All Fly Our Own Machines Soon” [zotpressInText item=”{IDMFRLAF}”]. Thus read the headline about Henry Ford’s plans in the November 1926 edition of Popular Science magazine, half a year before Charles Lindbergh flew across the Atlantic. Before a brief exegesis21 of why we will never live in a world where flying cars are common transportation, we could amble through the next 93 years of articles promoting this fantasy. Let us land at “You Can Pilot Larry Page’s New Flying Car With Just an Hour of Training” [zotpressInText item=”{LHCNX8D2}”], however, because it unites two themes relevant to MT: a huge investment in a much-hyped technology by a co-founder of Google, and journalists falling for and promoting the hype, hook, line, and sinker. Before continuing, please enjoy this video and the Fortune article about Page’s aircraft, Kitty Hawk. On that line, companies that are not Google have developed substantially better models; the Dutch PAL-V, at $400,000, is a gyrocopter that flies higher and faster, for much longer distances (no information on the noise profile of its 200hp engine), then can have its wings folded in a parking lot and perform reasonably on the road, with energy usage comparable to contemporary vehicles in both air and land modes. Were such machines to become affordable to millions, though, numerous factors would prevent their viability in urban or suburban environments, with acceptability plummeting as lower monetary cost increased uptake. Operating a vehicle in three dimensions requires a skill set that greatly surpasses movement along the ground – for example, constant awareness of safe landing spots and the ever-shifting localized wind conditions needed to take off and land safely. Among the major causes of fatal automobile accidents [zotpressInText item=”{3XTLHDMM}”], all of which are variations of driver error, weather conditions, road conditions, mechanical failures, and encroachments, only a few (running red lights and stop signs, potholes, tire blowouts, sharp curves) would not occur in the air. We can fairly predict that operator strokes and heart attacks will occur at roughly the same rate in the air as on the ground. Drunk flying will occur at about the same rate as drunk driving, without the possibility of police patrols to stop impaired people from operating their vehicles. Meanwhile, the skies introduce many new dangers, such as birds, icing on the wings, insects clogging the pitot tubes essential to determining airspeed and altitude, wind shear, and vehicles approaching from any angle. People will sometimes fail to make sensible decisions, such as how much fog, rain, or wind is too much to abort a trip, or keeping loads balanced and within weight limits, or maintaining adequate fuel reserves. RIP, Kobe Bryant. Mid-air collisions are rare today because planes are few and spaced by miles, with pilots adhering to a variety of protocols. A significant increase in low-altitude traffic, though, with vehicles hopping among random points like popcorn, would produce insupportably dense skies. A fender-bender on the ground is Game Over at 1000 feet. A car with a sudden mechanical problem stops and the passengers go home in a taxi; a gyrocopter with a sudden mechanical problem drops and the passengers go home in a box. Automation would exacerbate the dangers, with myriad people punching buttons in aircraft they did not know how to control in emergencies as simple as a fatigued engine bolt. Has an electrical failure ever caused your phone or computer to shut off? If your avionics shut off in the air, your race to reboot would fare poorly against gravity. On-board sensors would have even more difficulty than human eyes in picking out hazards such as electric wires, flag poles, fences, overhead road signs, rocky landing surfaces, geese, and drones. People will maintain their flying cars with the same diligence with which they maintain their earthbound rides, which is to say they will not keep their fluids topped or have their equipment serviced on tight schedules, much less conduct pre-flight walk-arounds or detailed safety inspections (if they even know what to look for and have access to view critical components). As risky as flying cars would be to the people inside them, they would be a greater terror to people on the ground. Perhaps you’ve heard a book-sized drone buzzing around your neighborhood; increase the engine to a size needed to lift a few humans and their cargo and you increase the noise proportionally (and don’t imagine an electric propellor would be silent); increase the number of vehicles and you’ve got the clamoring cacophony of lawnmowers overhead night and day. What is your risk tolerance for an occasional disabled machine falling through your roof? Or a drowsy or suicidal pilot? When anyone can get a flying car, anyone can drop a homemade bomb on their ex’s house, or unload a vat of acid over a church picnic, then flee without a trace. People toss cigarette butts and McDonalds wrappers out of their cars all the time – now they are small missiles heading straight for your head. Vehicles such as Kitty Hawk could some day see service autonomously airlifting venture capitalists around Silicon Valley. However, they will not and cannot provide to the masses the transportation solution of the future. No matter a century of drool from a gullible press that does not dig even as deeply into the question as this sidebar does. No matter continued headlines such as “We were promised flying cars. It looks like we’re finally getting them” [zotpressInText item=”{492KUD5C}”]. After all, the dream, which many of us have shared since our childhood fantasies, is put forward confidently by proven innovators like Henry Ford and Larry Page who we want to believe. All this is to drive home a point: artificial intelligence is to translation as the flying car is to transportation: extremely interesting in privileged contexts, infeasible in most.
Artificial Intelligence, Machine Translation, and the Flying Car20
Page’s team has produced a tremendously cool vehicle that would be a rush to fly. It takes off from the water, flies at the altitude of a basketball, moves at the speed of an electric bike, makes the noise of a delivery truck, stays aloft for about as long as it takes to make and eat an omelet, and, could it physically rise above power lines and rooftops, would not legally be allowed to fly over populated areas. And, what should be obvious: it is not a car. It does not take off, land, or taxi on a roadway, it cannot ferry you to work, it cannot carry passengers or groceries, it cannot go out on a rainy or windy day, it cannot fit in a parking space. It is not a car, though “flying cars”, machines that can operate on roads and in the air, will soon exist as a toy for rich people.
Myth 2: Neural Networks Solve Machine Translation22

Picture 29: Bettors predict the winners of horse races based on small statistical variations. People who put their money on 19 of the 20 horses in this picture will lose. Credit
Lest you noticed that previous generations of GT did not quite produce perfect translations, you might be reassured that recent developments in neural networks (NN) have ironed out previous wrinkles, and the sun is rising on flawless universal translation. A 2016 cover story for the New York Times Sunday Magazine [zotpressInText item=”{MLXRFY49}”], for example, presents the story of GT’s conversion from statistical (SMT) to neural (NMT) machine translation, with the assertion in the opening section that GT had become “uncannily artful”.
In SMT, a lot of data is compared between two languages, and translations are based on imputed likelihoods, like predicting the winner of a horse race based on a set of knowledge about past performance (Picture 29). Much of the challenge of translation arises from the ambiguity wherein a single spelling can mask multiple meanings, the problem of polysemy. Assume, for example, that “spring” in English is found to correspond to “primavera” in Portuguese in 40% of parallel texts, and corresponds to terms matching six other senses (bounciness, a metal coil, water flowing from the ground, elastic force, stretchiness, a jump) at the rate of 10% each. As the plurality sense, SMT will offer the translation pertaining to the season much more than 40% of the time, because it is four times more likely than any of the others individually.
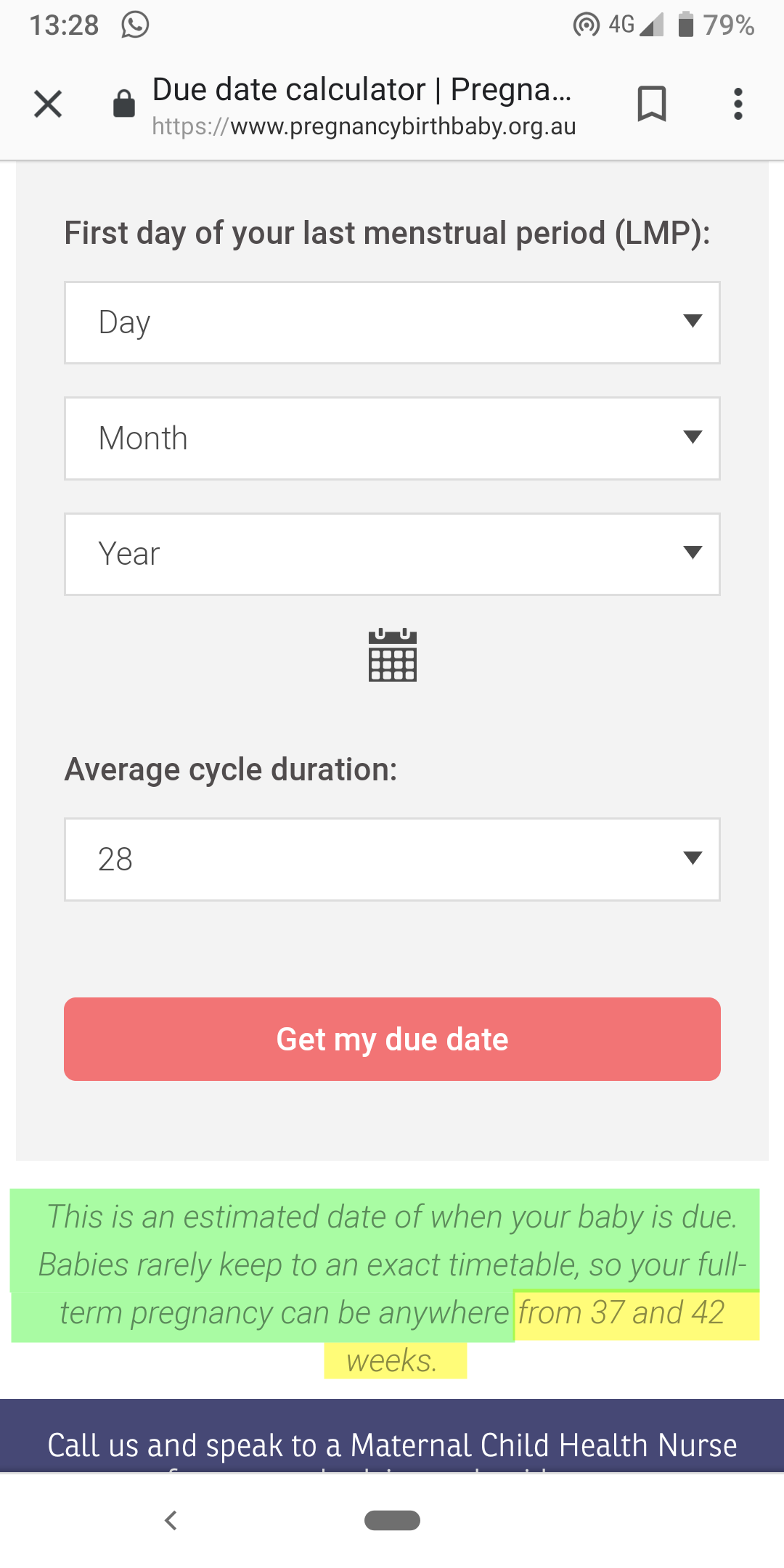
Picture 29.1: An honest pregnancy due-date calculator that stresses the weakness of its statistical prediction. By contrast, although basing its predictions on exactly the same algorithm, mamanatural.com woos parents to its site by claiming in the metadata optimized for Google search results that they have an “Amazingly Accurate Pregnancy Calculator”.
Let’s look at a non-linguistic example of using statistics to make predictions. Babies are notoriously poor at scheduling their emergence from the womb. Natural births usually occur within a one month range, the mid-point of which is about 280 days after the mother’s last menstrual period (which itself is rarely marked on a calendar). About 4% of babies, or one in twenty-five, are actually born on the date projected by the algorithm. My own daughter was born two weeks after the “due date”. Had we booked flights for her grandmother to be in the hospital for the birth based on that statistical guess, my mother-in-law would instead have spent many days watching us trying to induce labor by playing beach paddle ball in our local lake, and been home before the first contractions kicked in. There is a scientific basis for proclaiming that a baby will be born somewhere around a given date – but the wise and honest emphasis should be on the “somewhere around”, done well as shown in Picture 29.1. For translation, SMT makes similar guesses that are only sometimes, like race predictions that have some additional information about the horses and jockeys, based on more sophisticated algorithms.
NMT, by contrast, infers connections based on the other words embedded in the “vector space” surrounding a term. Vector space, which sounds impressively mathy, is used in MT to describe the mapping of different words and phrases in a corpus to capture their degrees of similarity [zotpressInText item=”{5248838:KVMAIFYU}”]. Theoretically, NMT should recognize that, when mountain and spring appear together, “spring” likely pertains to the sense of flowing water. GT’s self-professed “near perfect” NMT Portuguese produces the erroneous “primavera de montanha” when given “mountain spring” by itself, but with tweaking (collocation with the word “water” is necessary but not sufficient), a sentence can be found that generates the correct “nascente”, demonstrating that NMT can improve on statistics: “A água flui da nascente da montanha” when shown the context “Water flows from the mountain spring”. The guesses that NMT makes when mapping its vectors, though, are often wildly erratic. DeepL, for example, intuits that “Regards” is the closing of a letter, compares that to a French closing from some official letter in the EU archive, and proposes “Je vous prie d’agréer, Monsieur le Président, mes salutations distinguées” (see Picture 68). GT recognizes that 习近平 is the Chinese president Xi Jinping, finds text about presidents, and translates the name as Эмомали Рахмон in Kyrgyz – that being Emomali Rahmon, president of Tajikistan.
In cases where two languages have substantial parallel data, and the domain is well treated in the corpus, results can be astounding. This can be seen in action with DeepL’s spot-on translation of “his contract came to an end” to French, correctly using the non-literal “prendre fin”; using Linguee to view the data on which DeepL (discussed in this sidebar) is presumably based, one can see numerous examples where a contract “came to an end” in English and “a pris fin” in French (mot-à-mot “has taken end”). In GT, the English phrase “easy as pie” is improperly verified 🛡 “c’est de la tarte” for French, but given the correct colloquial translation “simple comme bonjour” in some, but not all, longer test sentences.
I recommend reading “Understanding Neural Networks” [zotpressInText item=”{5248838:VB33DRQ9}”] for a somewhat approachable overview of the computer science involved. At the nub of Yiu’s explanation: neural networks are models of a complex web of connections (and weights and biases) that make it possible to “learn” the complicated relationships hidden in our data. Basically, the computer does a lot of checking of some elements A, B, C, and D in comparison to other elements W, X, Y, and Z, and patterns often emerge. There can be a lot of layers – A, B, C, and D are first checked against E, F, G, and H, and then those results are checked against I, J, K, and L, and then onwards toward W, X, Y, and Z and beyond. The more layers in a system, the “deeper”, and thus the name “deep learning”.
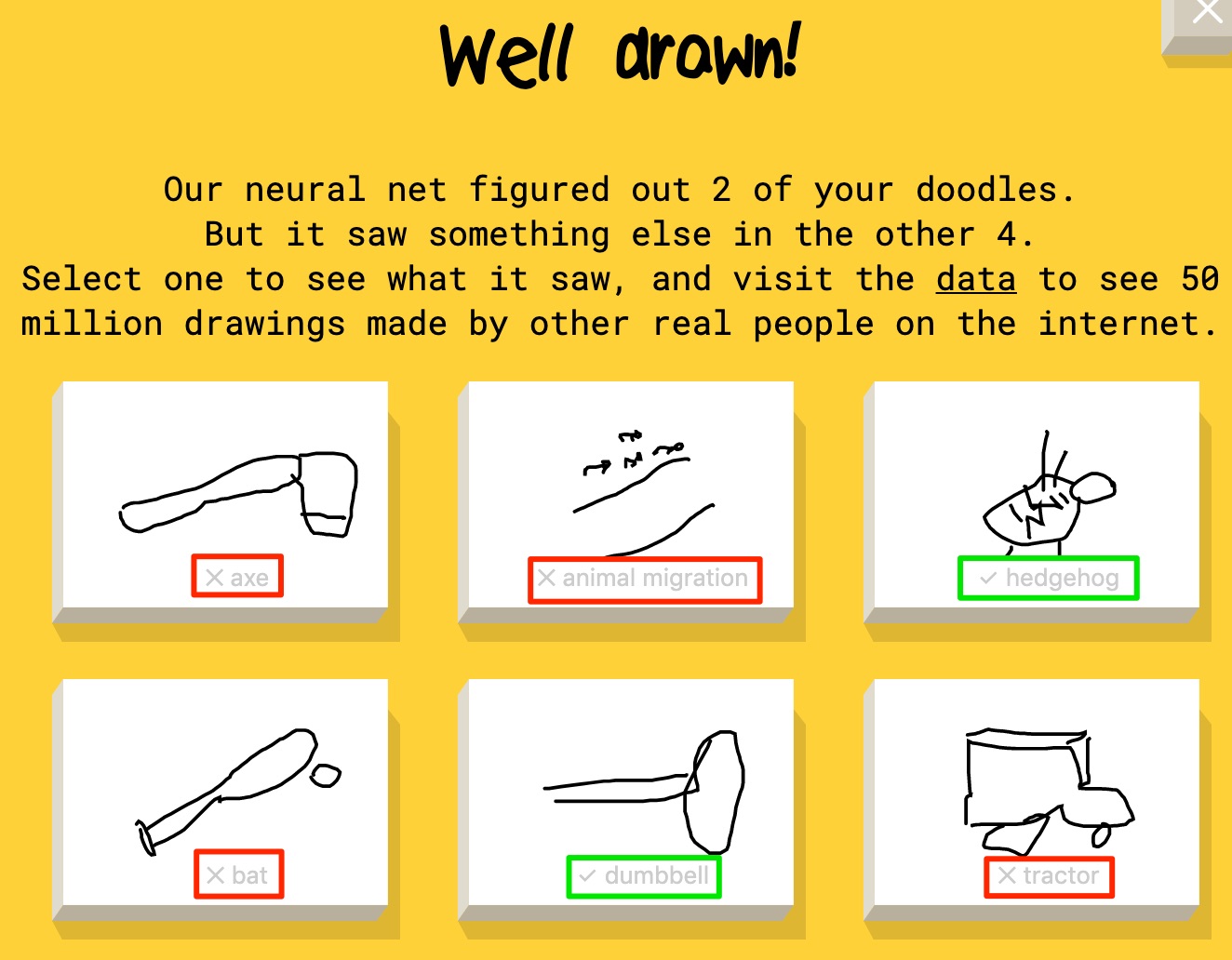
Picture 29.2: The Quick Draw neural network experiment, https://quickdraw.withgoogle.com.
A fun neural network experiment called Quick Draw (sponsored by Google) that invites your participation gives an indication of both the strengths and limitations of what neural networks can achieve. Players are given a term and 20 seconds to sketch it on their device. (High art is not expected, or possible.) Picture 29.2 shows some results: the program recognized my “dumbbell” before I had a chance to complete it, based on thousands of other people taking a very similar approach to the same prompt. It also recognized “hedgehog” before the clock ticked over, though I myself would not guess the result from my own drawing. However, it did not recognize “bat” because I drew “baseball bat” instead of the flying mammal it was expecting, and it did not recognize “axe” or “animal migration” although I suspect many human readers will discern the terms from the doodles. (It also did not recognize my “tractor”, but who would?) The game is fun for the whole family, and sometimes the program will correctly glean all of your drawings. The first point here is that a neural network working on a limited data set of a few dozen terms, with more than 50 million data points and counting, is still highly constrained in the inferences it can make. Neural networks can discern a lot of patterns that machines cannot otherwise recognize, but they can only dive “deep” to the extent that they have lots of clean data to learn from. A second point is that a neural network could not have guessed any item I drew outside of its training set – for example, had I drawn what I intended as a cowboy hat, it would have guessed “flying saucer”, because only the latter is within its data universe.
In certain circumstances, NMT thus offers a marked improvement over phrase-based SMT. Toral and Way [zotpressInText item=”{Y2ST9WI3}” format=”(%d%)”] measure this for three literary texts translated from English to Catalan, and give the level-headed comparison that sentences attaining human quality rose from 7.5% with SMT to 16.7% with NMT in one text, 18.1% to 31.8% for a second, and 19.8% to 34.3% for a third, concluding, “if NMT translations were to be used to assist a professional translator (e.g. by means of post-editing), then around one third of the sentences for [the latter two] and one sixth for [the first] would not need any correction.” This study went to great lengths to stay within the lanes of reporting on a single language with rich data (more than 1.5 million human-translated parallel sentences), and reached the notable conclusion “NMT outperformed SMT”. It was puffed by the tech media cotton candy machine, though, into “Machine Translates Literature and About 25% Was Flawless” [zotpressInText item=”{CUV9F2UL}”].
Ooga Booga: Better than a Dictionary23
Nota bene: because neural machine translation (NMT) is based around the context in which words appear, it can offer no improvements to statistical machine translation’s (SMT’s) horse-race guesses for the 89% of users [zotpressInText item=”{IWCY3KIK}”] who improperly attempt to use a machine translation (MT) service as a bilingual dictionary.
A window into how NMT performs as a dictionary comes from translations of the nonsense phrase “ooga booga” from all 107 languages to English.
In 82 cases, NMT does not find a friend, so the MUSA mandate to supply a word, any word, repeats “ooga booga”. If Google is giving us “better than human” translations [zotpressInText item=”{FNRQGIGV}”], these results must be “better” than a dictionary. After all, no dictionary would be bold enough to include “ooga booga” in any of those languages.
Another 8 cases transform the capitalization and/or the number of o’s and g’s in various ways (when delivering mass in Latin, for example, the Pope apparently considers “Ooga Booga” to be a proper noun). And then things get weird.
For 5 languages, the neural networks found independent translations to English (with Urdu helpfully proposing that the purported English term be read in Urdu script).
But for 16 languages, the neural machine translations form into geographic clusters. The three Baltic states and distant Hungary all change “booga” to “boga””; Latvian and Lithuanian are about as close to each other as English is to Dutch, but unrelated to the other two, which are distant Finno-Ugric cousins of each other. The three Celtic languages around the Irish Sea go all downward-facing dog, though “ooga yoga” is the popular style in Ireland while “soft yoga” is the rage in Scotland and Wales. I posit that the neural net has transmuted “booga” to “blog” and then elaborated on some word embedding for three unrelated African languages from north of the equator (two spoken in Nigeria). The six African languages from south of the equator are the biggest puzzle – they are all Bantu languages with sparse parallel data versus each other and versus English, so perhaps GNMT mixes them all in the same blender in an attempt at enhanced results?
I can only report the odd way that Google’s neural networks performs in their simulation of a dictionary. I cannot begin to explain. I can only suggest that we do “ooga booga” as any good Tamil speaker would: Go speculative!
Africa middle latitudes (except Hausa)
Amharic: look at the blog
Igbo: look at the blog
Yoruba: look at the blog
Africa southern latitudes
Chichewa: you are in trouble
Sesotho: you are in trouble
Shona: you are in trouble
Swahili: you are in trouble
Xhosa: you are in trouble
Zulu: you are in trouble
Baltic + Hungary
Estonian: ooga boga
Hungarian: ooga boga
Latvian: ooga boga
Lithuanian: ooga boga
Celtic languages
Irish: ooga yoga
Scots Gaelic: soft yoga
Welsh: soft yoga
Two South Asia + one Baltic + Latin
Belarusian: Ooga booga
Kannada: Ogga Boga
Latin: Ooga Booga
Telugu: Oga Boga
Four South Asia + one middle Africa
Bengali: Booga in the era
Gujarati: Grown bug
Hausa: on the surface
Tamil: Go speculative
Urdu: وگا بوگا
The research that Google presented in correlation with the launch of GNMT (Google NMT) assigns a specific numerical value to this improvement. “Human evaluations show that GNMT has reduced translation errors by 60% compared to our previous phrase-based system on many pairs of languages: English↔French, English↔Spanish, and English↔Chinese” (Wu et al [zotpressInText item=”{4DUXVV8G}” format=”%d%”] – read this article for the definitive mechanical overview of GNMT). Without fixating on “many” being defined as 3 out of 102 in each direction in relation to English, do note that a) all three of these high-investment languages are in the top tier in my tests, and b) not a word is said about non-English pairs. Not Urdu, not Lao, not Javanese, not Yoruba, not any testing reported in any down-market language. Not Afrikaans nor Russian where results for formal texts might surpass the study languages. There is no scientifically valid way to extrapolate the findings in Wu to any GT language that has not been tested. That is, the blanket conclusion that GNMT produces “better” results than previous models when comparable corpus data is available is likely correct, but Google’s research does not support a blanket “60%” claim for the 99 languages within GT at that time. Nevertheless, a great many academics now take the plausible-sounding claim in a peer-reviewed publication at face value as applying across the board.24
Even were that level of improvement to be consistent across languages, most of the languages in the system, as measured in this study, began at a much lower starting point, begging the baseline question “60% better than what?” Nevertheless, the headline the public sees erases any nuance in interpreting what Wu legitimately shows, blaring “Improvements to Google Translate Boost Accuracy by 60 Percent” [zotpressInText item=”{QXKYCHRV}”]. So, NMT (or what my testing indicates inconclusively to be a hybrid deployment using SMT for short phrases) is better than SMT by itself, and in some cases produces Bard-like results. This is encouraging for resource-rich languages, leading to the recommendation that you use GT, with caution, in certain advised situations. But there is no plausible research underlying headlines about GNMT such as “Google’s New Service Translates Languages Almost as Well as Humans Can” [zotpressInText item=”{5248838:ITGN3ASL}”].
The manner in which this news has been extrapolated leads us back to the flying car. Hofstadter [zotpressInText item=”{DLK6QG2B}” format=”(%d%)”] notes “verbal spinmeistery” beneath use of the term “deep” to suggest “profound” instead of its technical signification of “more layers” of processing than older networks. For example, a second New York Times Magazine cover story about AI expounds, “Deep neural nets remain a hotbed of research because they have produced some of the most breathtaking technological accomplishments of the last decade, from learning how to translate words with better-than-human accuracy to learning how to drive” [zotpressInText item=”{FNRQGIGV}”]. Read that again: in a major article, the US “newspaper of record” rhetorically ratcheted NMT from “near perfect” all the way to “better than human”. Google’s own research [zotpressInText item=”{5248838:DHK87Z3A,10}”], far from “better-than-human” results, reports, in conjunction with the milestone achievement of all 103 languages then incorporated into GNMT, an average BLEU score of 29.34 from English to its top 25 languages, 17.50 for its middle 50, and 11.72 for its bottom 25 (they do not share disaggregated data) – numbers that very much adhere to the empirical findings of TYB. It is the journalistic spin, not the MT results, that should leave you gasping for breath.
When people repeatedly hear plausible-sounding hyperbole echoed by sources they trust, those statements become confirmed truth in the public mind, even among ICT professionals who then trumpet that fake news in bars, interviews, and conferences. A translation professional informed me of a client who went so far as to reject human translations on behalf of a major European airline because the results did not look like the output from the alleged authority of Google Translate. A little bit of knowledge is a dangerous thing, or, after that aphorism being translated by a bilingual person to Japanese, 生兵法は怪我の元, is “60% better” reverse translated by GT to say, “The law of living is the source of injuries.”
A few days after the second NY Times article, the prestigious journal Science published an article with the headline, “Artificial intelligence goes bilingual—without a dictionary” (Hutson 2017). Science was reporting on forthcoming articles by Artetxe et al [zotpressInText item=”{6CWRJSJ5}” format=”(%d%)”] and Lample et al [zotpressInText item=”{AZWT9LZN}” format=”(%d%)”] about research in unsupervised learning. In Lample, neural nets processed a random half of the English side of a test corpus, independently processed a random half of the French side of that same corpus, and obtained a non-zero BLEU score of 15.1. In essence, BLEU25 as a (problematic (see [zotpressInText item=”{DYJCH3HN}” format=”%a% %d%”], [zotpressInText item=”{X6X8SKLH}” format=”%a%, %d%”] and [zotpressInText item=”{RAYSQ5K6}” format=”%a%, %d%”])) metric is a scoring, between 1 and 100, of the extent to which MT output has the same words, in the same order, as a human translation.26 A score of 15.1 indicates output similar to a low Tarzan score in my tests, where some word equivalencies are found but the results are largely incomprehensible to a native speaker. Google’s NMT for English to French obtained a BLEU of 38.95, which is 2.5 times higher than the experimental results that Artexte’s and Lample’s groups independently achieved. The production French score is comparable to the 38.30 overall production Dutch-English score attained in my spot test shown in Table 1, indicating a high probability of debilitating errors. A proper reading of the articles is that unsupervised learning as a technique was tried and the results were not entirely futile – like reporting on an anti-baldness medication that was only 40% as effective as the leading product, but did lead to 15% hair recovery on one test subject. An improper reading would be, “For The First Time, AI Can Teach Itself Any Language On Earth” [zotpressInText item=”{KVUZXFTB}”], patently false 7000 times over.27
Yann LeCun, Facebook’s Chief AI Scientist,28 amplifies the misinterpretation of the research results as solving the question for all 25 million pairs in the grid,29 only missing by about 24,999,990, “How do we translate from any language to any other language?” In his full explanation (which you can watch or read), based on Lample [zotpressInText item=”{RF3QWNJZ}” format=”(%d%)”], LeCun declares, “in fact, that actually works, amazingly enough!”
Picture 29.3: Neural Machine Translation of nonsense text, exposing the NMT imperative to deliver the closest result it conjures from the data.
Moreover, when NMT encounters text outside its training regimen, according to Harvard’s Alexander Rush, the system can “hallucinate” bizarre outputs. “The models are black-boxes, that are learned from as many training instances that you can find. The vast majority of these will look like human language, and when you give it a new one it is trained to produce something, at all costs, that also looks like human language. However if you give it something very different, the best translation will be something still fluent, but not at all connected to the input” [zotpressInText item=”{JWQUU4EA}”]. Sometimes the output will be so egregiously concocted that we can see where NMT gropes (“deep learns”) through its training data. Though not examined in TYB, Microsoft makes similar claims to Google and runs on a similar NMT-based system. They title a blogpost from 29 June, 2019, “Neural Machine Translation Enabling Human Parity Innovations In the Cloud“, and assert therein (with a few caveats), “we showed for the first time a Machine Translation system that could perform as well as human translators” that they were beginning to launch “in production of our latest generation of neural Machine Translation models” that “incorporate most of the goodness of our research system”. Picture 29.3 exposes the bricks for some fake Arabic, where a random text input is routed to a selection of English words that represent the closest connection Microsoft could find in the training corpus. GNMT finds the Bible to be a source for deep learning for its five African languages from north of the equator (Amharic, Hausa, Igbo, Somali, and Yoruba), asserting that “da da da da da da da da” translates from all to English as, “and the Lord of the heavens and the earth!” (The same string cleans up along a partial Indochinese Peninsula cluster as “taking a bath” in Hmong and Lao, “shower, bath, bath, shower, bath” in Khmer, and “shower, bath, shower, shower” in Myanmar (Burmese))30 You will usually not, however, see such blatant smoke from the gun in your translations, so there is no way to take cover from such common misfires of the neural synapses.
We can take “spring tide”, the bi-monthly tidal extremes that occur during every full and new moon,31 as a case study. By inspecting Linguee, we can see that the term occurs with some frequency in the documents that DeepL uses to translate between English and French, but not between English and Portuguese. The French term “marée de vives-eaux” has not been mapped by humans to “spring tide” within Linguee, but DeepL nevertheless discovers the right translation to French from their training data. With the term absent from the English-Portuguese parallel text, though, DeepL goes to the “springtime” sense of “spring”, even when given a sentence designed to point the way, such as “There will be flooding during the spring tide tonight.” GT blows the sentence in every language, flailing for the “springtime” sense in French and Portuguese, and rendering Swahili that back-translates as “There will be with floods when water of water night of today” – despite these being three languages of seafaring people who have used their term for “spring tide” for hundreds of years. Bing, which also describes NMT as their default method, translates the sentence to Swahili as “Kuna mapenzi kuwa mafuriko wakati wa spring wimbi usiku wa leo”, which back-translates as “There is lovemaking to be floods when «spring» wave night of today”.
This is not a mistake, it is MUSA, the requirement that the MT system conjure up text of some sort, regardless of its basis in human translation. MUSA is invoked whether the data is merely missing, as with the equivalence between “bamvua” and “spring tide” being missed in GT’s Swahili training data,32 but also when the data does not exist. Nepali is the language of a landlocked country high in the mountains, which has never had reason to develop a vocabulary for oceanic phenomena, but GT sails forth to render the example sentence as “त्यहाँ चिसो चिसो आज रातभरि बाढी हुनेछ।”, which a Nepali-speaker back-translates as “Over there all night long last night will be a very, very wet flood”. This language-like hallucination is not a bug – filling in the gaps with anything at hand is inherent to the NMT algorithm.
In sum, NMT offers certain improvements over SMT, where extensive parallel data training data can be exploited, to the point where MT can be used to transmit information unreliably between English and about 35 languages identified in this study in non-critical situations. From that, FAAMG and the popular press have produced the empirically false myth, stated as fact in no uncertain terms, that we now live in an age of universal translation. To modify a saying popularized by Mark Twain, there used to be three kinds of lies: lies, damned lies, and statistics. Now there’s a fourth contender: neural networks.
Myth 3: “Zero-Shot” Translation33
This section unfurls the tale of how a test became an untruth, and an untruth became a widespread belief. GT produced a lot of buzz around its MT engine when it announced that “our method [GNMT] also enables “Zero-Shot Translation” — translation between language pairs never seen explicitly by the system” [zotpressInText item=”{K2IBBSGY}”]. The announcement, timed to the publication of Johnson et. al [zotpressInText item=”{EWBHWBHM}” format=”(%d%)”], led to headlines such as, “Google’s AI can translate language pairs it has never seen” [zotpressInText item=”{RTH7YZL8}”]. You can review all the coverage at https://www.google.com/search?q=zero-shot+translation. Zero-shot is a fantastic idea, and a long-term goal we are taking early steps toward at Kamusi. The problem is, a close reading of the article underlying the announcement shows that Google did not, in fact, achieve anything close to what they led the public to believe.
That bloggers and journalists came to believe what is patently untrue, that Google can blindly translate between any language pair, can be pinned largely to the deceptive wording of GT’s blogpost and journal article:
This inspired us to ask the following question: Can we translate between a language pair which the system has never seen before? An example of this would be translations between Korean and Japanese where Korean⇄Japanese examples were not shown to the system. Impressively, the answer is yes — it can generate reasonable Korean⇄Japanese translations, even though it has never been taught to do so. To the best of our knowledge, this is the first time this type of transfer learning has worked in Machine Translation. [zotpressInText item=”{K2IBBSGY}”]
In the journal article, they speak of “reasonably good” translations from Portuguese to Spanish, “the first demonstration of true multilingual zero-shot translation”, and “a successful example of transfer learning in machine translation, without any additional steps”. In their conclusion, the paragraph that the non-specialist reader is most likely to inspect, they state: “We show that zero-shot translation without explicit bridging is possible, which is the first time to our knowledge that a form of true transfer learning has been shown to work for machine translation. … Our approach has been shown to work reliably in a Google-scale production setting and enables us to scale to a large number of languages quickly”.

Picture 30: “Zero-Sort Recycling” lets people mix all of their recyclable waste in a single bin that is processed by waste engineers behind the scenes. The name “Zero-Shot Translation” implies that similarly little user effort is required to achieve similarly effective results. Photo by author.
To understand what they actually achieved, it is important to look at the data they actually present. For their experiment from Portuguese to Spanish, they report BLEU scores of 31.50 for NMT based directly on parallel data between those two languages, a close 30.91 for a two-step NMT from Portuguese toward English and then English toward Spanish, and 24.75 for their best zero-shot model. That is, the score drops 6.75 points, or 21.4%. This is in comparison to the best BLEU score they mention in the study, 82.50 for translations from Belarusian to Russian, two very close languages, based on direct parallel data (a perfect 100 score does not occur, because even two human translators will rarely choose identical words across a series of translations). A score of 24.75 indicates that Tarzan-quality results were attained in some portion of situations, but is far from demonstrating the achievement of understandable translation. For their experiment from Spanish to Japanese, the BLEU score drops in half, from an already-low 18.00 with bridging through English, to a floor-scraping 9.14 with zero-shot.34 Nonetheless, their text states that, “despite the quality drop, this proves that our approach enables zero-shot translation even between unrelated languages”.
Let us repeat: the numbers presented show something indicating a near-zero Tarzan rating, yet the article claims that the translation is “enabled”. For Korean to Japanese, the empirical evidence for “impressively reasonable translations” is {Ø} (the empty set): no numerical or human evaluations are given. Again: the entire premise that “true transfer learning has been shown to work for machine translation”, what the blogpost trumpets as “the success of zero-shot translation” for Korean to Japanese, is based on zero quality analysis – it is remarkable that this section did not get shot down during peer review. Google makes an explicit truth claim, using the word “true”, that is swallowed whole by the media but is not supported with data.
Picture 30.0.1: Word cloud from “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation” (Wu et al 2019), generated at http://wordclouds.com
Perhaps we are witnessing a cultural clash here. When computer scientists approach MT, their goal is for their computational methods to achieve discernible results. Getting measurable numbers, even the murky ones scored for Spanish to Japanese, indicates “success” that “has been shown to work”, in that the results were better than zero. Google taught their program to compare two languages via an English bridge, then took away the bridge, and the program had learned enough to retain some equivalents. That is an impressive accomplishment, and offers promise for future research. However, it is a long way from “reasonable quality” as a language specialist understands the term, or as an MT consumer would expect. What is being reported is that the operation was a success, though unfortunately the patient died.
The words they use provide a good window for peering into the culture of computer scientists. “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation” [zotpressInText item=”{5248838:4DUXVV8G}”] is a pertinent entrepôt, but you would get similar results if you pulled any journal article about MT out of a hat. The word cloud in Picture 30.0.1 highlights the concerns of the authors: BLEU, decoder, encoder, layers, constraints, length, beam, operations, stacked, model, function, wordpiece, output, speed, results, score, scores. Lower-frequency terms that you cannot see in the image but can be found in the text include: inference, normalization, vectors, softmax, n-grams, accumulators, axis, quantized. On the other hand, words that do not appear in the article include: noun, verb, adjective, sense, meaning, polysemy, multiword expression, syntax, grammar. That is to say, an entire major article about translation that will be cited thousands of times contains not one word about language or linguistics – not language in general, much less the inner workings of any given language in the system. The visual evidence in Picture 30.0.1 shows that the focus of getting translation right, for computer science, is a matter of finding a procedure that will lead to the highest BLEU score. Language, in this view, is not only secondary within translation – it is irrelevant.

Picture 30.1. A real tomato. Credit
An analogy. When I was young, my grandfather grew wonderful tomatoes in his garden in the hills of Vermont. All August long, we would gorge ourselves on sweet, juicy tomatoes fresh off the vine. In February, though, the homegrown tomatoes were long gone. Nor could tomatoes be bought in the supermarket. Then, some plant scientists engineered tomatoes that could survive a 4000 kilometer truck journey from California without rotting, bruising, or smooshing into juice. Now we could buy tomatoes in the middle of the winter! There was just one slight problem: the tomatoes had the taste and texture of styrofoam. The scientists had successfully produced an object that looked like a tomato, which pleased the agricultural conglomerates that sponsored their work because they could sell something in February that looked like a tomato, and pleased the administrators of my school cafeteria because they could put something on the lunch plate that they could check off as a vegetable. These tomatoes were not the tasty treat of Picture 30.1. Despite a common genetic origin, the industrial product was a simulacrum of the fruit that Mesoamericans had cultivated since antiquity.
Similarly, current MT produces a simulacrum of the languages people have cultivated. This artifice can be better or worse depending on the data and models deployed, but at least shares with human translation the fundamentals of finding words and patterns that some entity can directly compare. Zero-shot is more like the styrofoam ball in Picture 30.2, stained red with tomato juice. To food scientists, maybe the juice could be stored within the ball’s cell structure and the styrofoam tomato could be an interesting harbinger of a way to transport tomatoishness to a future Mars colony. To computer scientists who really understand what is going on, normal MT research is about trying to engineer a more palatable winter tomato (though built on the crunchy styrofoam pillars of lei lies and MUSA), while first results for zero-shot are exciting because they foretell decades more research for the linguistic flying car. To translation consumers, MT satisfies some of the cravings of a tomato that masks the potentially carcinogenic chemical compositions they are swallowing, while zero-shot is best considered the plastic window displays that Japanese call “sampuru” (サンプル). The goal of MT research is tomato engineering: output that achieves incremental improvements in the correspondence with the words a human might choose between languages. The goal of MT for consumers of linguistic services is an edible tomato: the successful conveyance of meaning. We can think of it as the styrofoam tomato paradox (STP).

Picture 30.2. A red styrofoam ball that could be made to look like a tomato. Credit
Unfortunately, though, Google’s claims and journalistic amplification leave the public with the impression that zero-shot translation is now a stunning fact. To wit: “Take Google-size data, the flexibility of a neural net, and all (well, most) of the languages of the world, and what you end up with is … Google’s new neural machine translation system, … that with minimal tweaking, … can accommodate many different languages in a single neural net, that… can do a half-decent job of translating between language pairs it’s never been explicitly trained on”.35 We started with a valid claim shown by Google’s experiments with a few languages – that if you have data to learn from between Language A and English, and you also have data between English and Language B, then machines can learn some direct connections between A and B. In a flash, though, we are teleported to the completely false notions that (1) you can pour some data from A and some data from B into a bottle, give it a good shake, and end up with a translation, and (2) GT has done this successfully for most of the world’s languages.
But let us pull away from the popular media, and look also at the secret world of computer science professionals. In agreement with the ideas expressed above, an anonymous reviewer writes, “An idea that neural network researchers (not from the field of natural language processing, but from the mathematical side of machine learning) have marketed is that you can take any raw data, throw it at a neural network (learning method) and you will get a good system.” The reviewer objects, though to the prevalence of this notion in the subfield of NLP, writing, “It is wrong to assume that NLP researchers (at least the majority) believe or advocate this statement!” All well and good until one reads the second anonymous review for the same article (and the comment that triggered this entire section): “Recent zero-shot NMT approaches learn to translate without using parallel data but just monolingual corpora. I miss a mention to this in the paper.”
To invoke aviation again, misguided journalism has led to the widespread belief that the world’s airplane fleets fly themselves while their pilots hang around to push buttons in case of emergency, where the truth is that pilots will always be necessary to run the show except for the purely mechanical operation of keeping the plane straight and level during cruise.36 In practice, over-reliance on automization leads to aviation accidents in the real world when pilots cannot override algorithms, the cause of 60% of 26 accidents studied by the FAA over ten years and of hundreds of deaths [zotpressInText item=”{SK8H6CW8},{P2ABMYWF},{6RWJEETG}”]. In the words of Patrick Smith, the author of the Ask the Pilot blog, “To be clear, I’m not arguing the technological impossibility of a pilotless plane. Certainly we have the capability. Just as we have the capability to be living in domed cities on Mars. But because it’s possible doesn’t mean that it’s affordable, practical, safe, or even desirable. And the technological and logistical challenges are daunting to say the least” [zotpressInText item=”{7QUSAUCC}”].
AI-dominated translation and full automation in aviation are worthwhile aspirational goals, but cartoon dreams of future systems should not be confused with the technologies that currently exist or are likely in the medium term. I am not saying that it will be impossible to someday achieve zero-shot translation based on good input and output models, good data, and neural learning. I am shouting, though, that my research shows that GT has not implemented effective zero-shot translation for any language pair, and their own research shows their probability of success is somewhere in the vector space demarcated by now-defunct Google Answers, Google Glass, Google Wave, and Google+ [zotpressInText item=”{7FMKFKW6}”].
Myth 4: Magic Wand Translation37
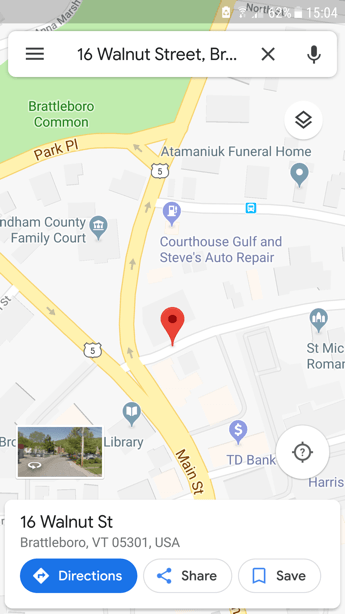
Picture 31: While Google Maps seems to recognize your thoughts as it types, you actually provide the service with quite a lot of information before it offers your target address.
It’s magical. It’s mind-reading. It’s deceptive. GT and its competitors give the illusion that the computer knows what you are thinking even before you are done thinking it; therefore by the time you’ve stopped typing, they must have arrived at an optimized answer. The fact that the software gives you words in real time does not equate to those being the right words, but it enhances the belief that they must be right. After all, if you do the same thing in Google Maps (GM), the service usually finds the correct location as it homes in on what you type, as shown in Picture 31 in Table 7.
But look closely in Picture 32 at what is actually happening with Maps, in comparison with Translate. When I first start typing “16”, GM starts predicting based on where my web searches or location-enabled amblings located me recently. Add a little bit of the street name and the prediction starts getting wobbly, wandering around nearby cities and countries. A few more letters and GM moves toward the right street name, though still on the wrong continent. The start of the next word ascertains that we are looking in English, for “Street” instead of “Close” or “Road” or “Ridge”. When I finally type the initial letters of the name of the town, the search has been narrowed down to the small range of places that have a matching street name, and I can click confidently for directions to get there (or, in the case shown, an honest assessment that GM “can’t find a way there” from my current location).
While the successful result makes it seem as though GM can read your mind, you can see by slowing down the illusion that the system works because it is actively picking your brain for the requisite information. GM whittles down to the best possible result because (a) the possibilities become increasingly limited as the search string becomes more specific, and (b) the user is actively involved in guiding the program by providing ever-more precise parameters.





The behavior of predictive search within GM conditions us to expect similar magic when we perform a similar typing action within GT. However, this is not the way translation works, in the same way that reflexively deflecting a fist thrown your way will not prepare you to swat off an incoming bullet. With translation, an additional letter can radically alter the meaning, and each additional word in a search string increases the opportunity for ambiguity and consequent error. Take the word “heretically”, and choose any language in GT to watch this performance (I have not tested this on all 102 languages, but a random look at Samoan shows mistakes marching up the ladder, from saying that “h” in English is “f” in Samoan, to problems I could uncover in a dictionary when the display word is “he”, and then “her”, (see Pratt [zotpressInText item=”{UX43XDH7}” format=”(%d%)”](1984)), and certifiable inventions along the progression to an obviously wrong choice for the final form). Table 8 shows the progression in Swahili.
Start by typing “h”,38 which has no meaning in English but, taking a sample of GT languages, is shown as “h” not only in Swahili but in Armenian, Chinese, Urdu, and Yiddish (all of which have non-Latin character sets), given local characters in Amharic (ሸ), Arabic (ح), Georgian (თ) and Hebrew (ח), and given words in Albanian (orë), Belarusian (гадзіну), Gujarati (એચ) and Japanese (時間). Adding “e” forms “he”, a pronoun that could, in principle, generate changes to other words already typed in the input box. Another stroke and you’ve changed the gender to “her” and made the pronoun possessive. Add an “e” to form the adverb “here”, add “t” and “i” to produce the lei lies “heret” and “hereti” or random guesses (e.g. GT opined once that “heret” is “tatizo” (trouble) in Swahili, and postulated a conjugated form of “to be”, “huwa”, on another attempt) on the target side, add “c” to form the noun “heretic” with the nonsensical translation offering of “kihistoria” (basically “historical”), add “a” to get the verbal hallucination “hepatica”, add “l” to make an English adjective that is translated with the noun “uongo” that means lie and so could conceivably have come from the same vector space, and finally move through the invented “hapaticall” (“hapa” (here) + “ticall” (letters from the English term)) to finish your intended adverb. All the while, GT has been changing its output to keep up with your keystrokes, and inventing fake words or mappings if it cannot locate a known equivalent. Typing a longer phrase such as “I told the heretical priest” causes emerging words to jump around as the system continuously revises its word associations, creates lei lies, and adjusts word order according to the grammatical patterns for the parts of speech it perceives at the instant. We can call these constant shifts “trumplations”: momentary changes in what is presented as reality that may or may not be related to facts on the ground, like negotiating with Jell-O.
Try “she will he… hear… heart… heartily enter… entertain” with any language to watch a small GT gymnastics show. Unlike GM, each successive keystroke does not build on the previous to guide the system toward a more perfect answer. The end results for “heretically” in Samoan and “she will heartily entertain” in Swahili, examples typed into GT with no greater purpose than to witness the machine in action with shape-shifting source terms, are flat out wrong. The likelihood of having an acceptable translation for any given source text accords with the overall scores for the languages in my tests, with absolutely no regard for the incidental characters typed along the way. Yet GT invests enormous processing power in kneading out latency while you type, so that you ultimately feel confident that the final output is the result of the most precise computation.
There is one other important difference between the way Google Maps and Google Translate deliver data. In Picture 31, GM shows the banks, churches, and funeral homes in the neighborhood of the search address. These are known and verified facts. GM would not invent map features and present them as real, as I did in picture 34. People would scream bloody murder if the map they were relying on invented a zoo, a pizza parlor, a river, and an iconic church. (Although they might be happy to find that there is no river where I drew one, since I forgot to draw a bridge.) GT, on the other hand, has no compunction about putting fictional information on screen, such as “hapatical”.
When GT does not have adequate data to hypothesize a translation, it invokes the Make Up Stuff Algorithm (MUSA). You can watch MUSA in action as performed by a fake sign language interpreter at Nelson Mandela’s 2014 memorial service. In picture 35, I wrote a real sentence that mentions the features on the fake map. Without laboriously breaking down the broken down Swahili output, let’s just state that the only words that are correct are “We can”, “from”, and, because it is an untranslatable name, “Notre-Dame”. The remainder is a combination of (a) wrong word choice (“on our way” becomes “on top of our path”), (b) vocabulary that exists in Swahili but GT does not have (“cathedral”) and thus renders in English, and (c) throwing some English words that do not have Swahili equivalents into the correct Swahili adjective-noun word order (though leaving out the preposition for “of” that should sit between).
Picture 35 is, therefore, the spiritual twin of Picture 34: a made up spattering of seeming facts about things that do not exist in Swahili-speaking Malangali, Tanzania. The difference is that Google has the humility to produce the map that shows the actual extent of their data in Picture 33 rather than inventing features in the physical space, whereas they have the hubris to fill the linguistic space on their screen with froth. The MUSA illusion is rarely subjected to close scrutiny, so users assume that the characters that GT prints to the screen are derived from some legitimately computed linguistic relationship – unless you can read the target language, you are bound to accept that the words they give you are a viable translation.
In fact, GT makes stuff up in every language. You can try the “heretically” test with top-scoring languages like Afrikaans and German, watching GT fill in gaps in its data with blather as you type. Importantly, not everything is made up. The French translation in Picture 35 is pretty good, raising native eyebrows with its handling of “some pizza” (which, unlike Swahili,39 does exist as such in French), but nicely reduces “on our way from” to “between” and converts the English party term “petting zoo” to the correct French party term that literally translates as “zoo for children”. However, examples throughout this web-book show that French, near the top of the GT charts, has many little fails (40% in the empirical tests), often from MUSA, that can wash translations down the drain.
The animation in Picture 3640 shows MUSA for the twenty languages that had the highest Bard scores in my tests. I gave GT a test phrase that should have returned empty results, “sdrawkcab uoy hcaet”, which is “teach you backwards” spelled backwards. For all twenty languages, GT confidently put forth some text, never suggesting that “sdrawkcab” just might be outside the set of words ever voiced on Planet Earth. Twenty languages, twenty lei lies. For a lucrative language like French, Google’s investments sometimes return splendid results like in Picture 35, sometimes complete fabrications like Picture 36, and usually, algorithmically, something in between. When you watch a magician perform, you know that the wave of a magic wand is often masking an illusion – the magician slips the rabbit into the hat in a way that you cannot see. With MUSA, the output is often the illusion: what looks like a rabbit pulled from a hat is actually a rabbit pulled from a hidden handkerchief, and what looks like Serbian or Indonesian or Dutch is actually “backwards” backwards.




















Myth 5: Google Translate learns from its users41
Picture 37: Select “Suggest an edit” to open an input box in GT. (“Tutaonana” does not mean “we will see” under any circumstances.)
<
One reason that people have confidence in GT is that they think its results improve over time via user contributions. They have two reasons to think this. First, GT includes a “suggest an edit” feature (Picture 37 and Picture 38). Second, Google invites people to contribute, and tells them that their contributions will be used to improve translation quality (Picture 39).
In December 2014, I began a test of GT’s “suggest an edit” feature with speakers of 44 languages. The phrase “I will be unavailable tomorrow” was being rendered incorrectly as “I will be available tomorrow” in quite a few languages. My test asked participants to assess the existing translation for their language, and to submit a suggestion if the GT result was inadequate. More than 200 people responded to my online survey that month. It is also possible that some people completed the submission task to GT but did not complete the survey to inform us. No suggestions are known to have been submitted for 7 languages that were rated “very good” or “perfect” by all respondents (Azerbaijani, Belarusian, Danish, Finnish, Norwegian, Swedish, Ukranian). The remaining 37 languages had at least one submission, even for 4 languages (Afrikaans, Dutch, Romanian, Russian) that were judged highly by most participants. 33 languages were judged “marginal” or “wrong” by all respondents.

Picture 38: Type a suggestion and click “submit” to send an edit to GT. (“Tutaonana” literally means “we will see each other”, and is frequently used in the context of bidding farewell.)
Several of the original translations would have received high BLEU scores, since the only difference from a human translation was a small negation such as לא in Hebrew; for example, wrong Irish scored 64.32. I asked participants to all submit changes to this single phrase so that we would be able to follow our bread crumbs later. In the wild, it would be exceedingly unlikely that more than one GT user would come across any particular mistranslated phrase and then go through the steps necessary to submit an improvement. A few phrases, such as “Happy birthday” and “I love you”, might inspire mass editing, or the oft-tweeted “Happy St. Patrick’s Day” from Irish42 as shown in Picture 40, but I felt safe in owning the submissions for “I will be unavailable tomorrow”. I was also conscious not to “Google bomb” GT with wrong answers, but rather to leave their service better off if they accepted our good-faith edits. The one thing I could not control for was whether GT themselves made manual changes to the phrase, beyond their normal review procedures, once they got wind of the experiment. Because participants were recruited via LinkedIn translation groups43 that certainly included members of Google staff, such intervention is a possibility.
Picture 39: “Help improve Google Translate for the languages you speak. Contribute to Translate Community to help people around the world understand your language a little better.” https://translate.google.com/intl/en/about/contribute.html
In December 2018, I ran the phrase again on all 44 languages. Interestingly, 41 languages were different from their 2014 version. For 5 of the changed languages, we did not submit any edits; the changes may come from normal fluctuations as we have seen for other translations tested at different times, or because of new data, or through the transition to NMT. Among 21 languages for which we submitted edits, the 2018 version has changed, but not with anything by study respondents. In 5 cases, we submitted multiple responses and one of those is active in 2018. For 9 languages, we submitted a single change and that is identical to the 2018 GT version. For 1 language, Malayalam, the contributor did not send us the edit they submitted, but GT now has a correct version . Only 1 language, Russian, which was rated highly by 2/3 of the male respondents but was unacceptable for females because it was grammatically incorrect for them and connoted sexual availability, remained the same although two edits were submitted.
Picture 40: GT translation of “Happy St. Patrick’s Day” from Irish to English. (GT will often change its output depending on punctuation and capitalization. Your guess about why is as good as mine.)
14 of the 37 languages for which we submitted an edit, or 38% (and possibly Malayalam), have a 2018 result that matches one of our submissions. I cannot say definitively whether those improvements came from our participants, or whether GT hit upon them independently, nor whether GT made an unusual manual effort to incorporate our data. Submissions did not make it into GT after 4 years for 22 of the 37 languages (59%) to which a human submitted an edit. 2 of those 37 were already deemed passable by most participants, and the new version is judged equally acceptable. 8 of the 22 languages that made changes other than our submissions were unacceptable before, but can now be understood; for example, a new human evaluator was able to give the correct reverse translation for Hindi मैं कल अनुपलब्ध होगा but commented that it was grammatically incorrect, Hungarian mates a singular subject with a plural verb, and Hebrew is correct for a female subject. In many languages, two or more different human translations were submitted by participants and none were accepted. Additionally, in some languages identical translations were submitted by multiple contributors; for instance, five Germans submitted “Ich werde morgen nicht verfügbar sein”, but that suggestion was not accepted, and the active 2018 version has been evaluated as worse than the 2014 version. In short, “suggest an edit” led to an improvement in Google Translate in a maximum of 2/5 of languages, over a 4 year experiment.
Stepping back, we can examine why the GT version of crowdsourcing is not, and cannot be, effective. From the more than 36 trillion words they attempt to translate every year [zotpressInText item=”{45FTMG28}”], they receive untold millions of suggested edits from people who are betting against long odds that their improvements will be accepted. Google has no knowledge of the linguistic skills of their contributors, so they must either accept the contributions blindly, or they must put them through some test. Validation must come from a human, because the act of submitting an edit is a declaration that GT’s best machine effort has fallen short.

Picture 41: Participation statistics from Zooniverse, a successful crowdsourcing project. http://www.zooniverse.org
Crowdsourcing is an emerging field. Various methods have been reported on to elicit knowledge from members of the public, each with their own benefits and hazards [zotpressInText item=”{D49386EB}”]. Among the challenges of crowdsourcing are the problems of motivation, design, and quality. It is not enough to have people click into a crowdsourcing project and complete a few introductory tasks. Participants are scarce, so they must be motivated to return repeatedly in order to make the recruitment effort worthwhile. Once recruited, the tasks they are assigned must be clear and manageable by design – instructions can be misconstrued in the most ingenious ways.44 Finally, participants might provide bad information, either because they do not have the requisite knowledge or attention to detail, or because they are actively intent on malice. Motivation can come in a variety of forms. First is financial, usually in the form of per-task micropayments. Micropayments are effective for circumscribed tasks, such as a thousand dollar study that needs 100 respondents to each answer 1000 questions for a penny a pop. An open-ended project with unlimited billions of microtasks would be a financial black hole, and GT therefore does not pay its crowd. Appeals to people’s sense of civic duty, as GT does in Picture 39, can be instrumental in recruiting them to investigate a crowd project, but are not effective in retaining interest over the long term. In the absence of financial reward, retention comes from making a compelling activity with intrinsic rewards, such as seeing one’s efforts result in evident improvements (such as a better Wikipedia page), or winning a game.
GT makes a nod toward gamification by declaring that participants have reached ever-higher levels, and received some badges of honor, as shown in Picture 42, but such a perfunctory use of badges and levels has been shown to leave users feeling they are on an Escheresque treadmill [zotpressInText item=”{JHPUUNWU}”]. Although there is some intrinsic gratification in feeling that one is nudging GT toward improvement, most people are busy and have many other options for their time. Readers of this web-book probably do not spend hours contributing to GT, and probably do not have acquaintances who do so, and neither do the citizens of Tashkent pass their idle time correcting Google’s version of Uzbeki. The motivations that Google offers are sufficient to attract an intrepid few for some trials, but cannot be imagined to compel sustained input from the millions of volunteers who would be needed to work through the volumes of edits submitted to GT every day. If GT were motivating people to submit and validate hundreds of millions of translations, a tally such as crowdsourcing projects like Zooniverse provides (see Picture 41) would be somewhere Googleable. GT’s design of tasks for the community, from the perspective of obtaining meaningful linguistic data, could not pass a scientific review committee. Participants are asked to either provide their own translations of a short snippet, or asked to validate previous translations. In either case, a few words are presented, completely devoid of context. Here are some English phrases that Google asks its volunteers to translate:
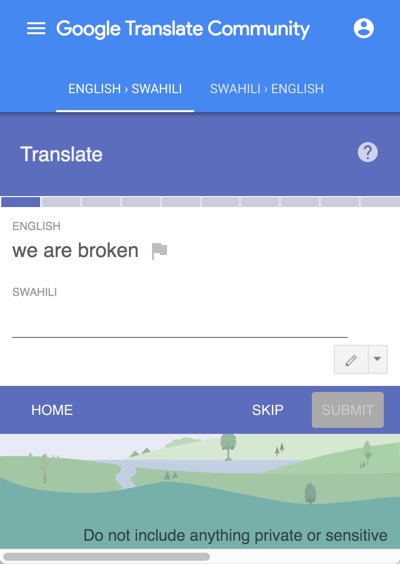
- justin is preparing something, I’m sure.
- score boosters
- neck kisses
- god with you
- is out
- how old are u
- waking the demon
- skill be with you
- not sleep
Here are two examples of items that Google asks its volunteers to translate from a sample language, Swahili, with a best attempt to render the incoherent word jumbles in English. Keep in mind that the starting point is alleged to be Swahili, but these texts are not anything a Swahili speaker would mumble unless they were on heavy meds:
- Moja ya vyumba vya kulala wageni: One of rooms of guests to sleep.
- Hakuna data zaidi roaming gharama: this could be Rorschached (see Trope 7) as “data roaming has no charges”, or “no more data roaming credits”, were data roaming a Swahili term.
Picture 44: Google Translate Community validation example where the translation is correct in one context and wrong in a plethora of others.
Not all requested terms are silly. “What is your favorite actor’s last name?”, “window dressing”, and “drifted apart” are all the sorts of things that occur with regularity in the normal ebb and flow of daily discourse. The latter two are in fact party terms that should be documented with their own dictionary entries. Without context, though, the average Telugu or Danish speaker can only guess at what “window dressing” might be – and many will guess. Consequently, off-target translations are often embedded with a certification badge (🛡) as validated short text translations.
Anecdotally, a group of advanced German learners of English thought the verified mistranslation shown in Picture 46 was perfectly okay until the association with birthing was explained to them. “Drift apart” should be translated with nautical terms when speaking of people on rafts, but lexicalized as a phrasal verb that is not translated with the watery English metaphor when speaking of people in relationships. Assuming the participant intuits the meaning of “drift apart” as an emotional term, “drifted apart” can still not be translated to many languages unless it is known whether it is we, you, or they doing the drifting.
In the Swahili validation example in Picture 44, “linaloundwa” is a perfect translation in the phrase, “The car that is made up of a body, wheels, and windows”, but would be wrong in past or future tense, or for the perhaps 95% of nouns that belong to a different “class”, or if the relative pronoun “that” were removed from the source phrase. The open-ended translation task is destined to cement innumerable translations that are only sometimes correct. The ✓/Ⅹ (yes/no) validation task will elicit many “✓” responses that should really be “sometimes”, as well as many conscientious “Ⅹ” responses that should also be “it depends”, because many participants will feel responsible to give a definitive answer. (In my own efforts to do no harm, I used “skip” for ambiguous terms during this trial.) In most cases, there is no way to give GT a certifiably “right” answer, because the design favors all-or-nothing answers in a situational vacuum. The technical term in computer science for bad input that results in bad output is “GIGO” – garbage in, garbage out, in this case a function of a design that is incapable of generating useable data. Were it clear that GT users understood their task correctly, the company still has not apparently implemented viable quality control. The process is opaque, but apparently works like this:
- User 1 offers a translation
- User 2 validates with ✓/Ⅹ
- Repeat Step 2 with new users until five ✓s are received [zotpressInText item=”{BK5832IV}”]45
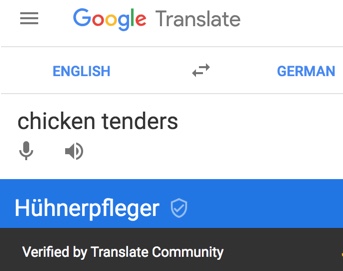 Picture 45: A translation that has been “Verified by Translate Community”. The English source phrase is a food item, processed fried chicken morsels. The “verified” German term is a person who takes care of living chickens the way a shepherd takes care of sheep. Picture 45: A translation that has been “Verified by Translate Community”. The English source phrase is a food item, processed fried chicken morsels. The “verified” German term is a person who takes care of living chickens the way a shepherd takes care of sheep. |
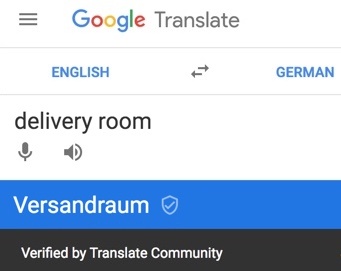 Picture 46: A “verified” translation from English to German in GT. The English source phrase is a place for mothers to give birth. The German construction is firmly a mailroom (https://www.linguee.com/german-english/translation/versandraum.html). Picture 46: A “verified” translation from English to German in GT. The English source phrase is a place for mothers to give birth. The German construction is firmly a mailroom (https://www.linguee.com/german-english/translation/versandraum.html). |
It is not unusual to find laugh-out-loud “verified” translations that should be rejected by a high percentage of volunteers, such as those shown in Picture 45 and Picture 46 (animated in Picture 46.1 below). Either the acceptance threshold is lower than stipulated, or five participants misconstrue an answer as correct for a variety of reasons. For example, a basket of Hamburgers and Frankfurters might not have enough familiarity with American haute cuisine to know that a chicken tender is a food rather than a profession. Or, a respondent might feel that an answer is close enough, even if there are small errors.
Or, a critical mass might choose either ✓ or Ⅹ for a polysemic party term where the translation is indeed correct in one context, e.g. if the translation of “run off” is correct in the sense of forcing someone away from their property, which will almost certainly be wrong in the sense of a second election between the top candidates of a first round, or waste that overflows in a flood – the majority is right (while simultaneously being wrong), but in the end the Google system is set to make a binary decision. The same issue occurs if the translation is correct in one register but not another, for example if a translation is correct for a male subject but not a female, and therefore given ✓ by men and Ⅹ by women.
More ominous is the problem of malicious users. For fun or profit, some users will inevitably try to mess with any system that invites public participation. The GT Community system is perfectly designed for maliciousness. A user could spend hours randomly clicking Ⅹ✓Ⅹ✓✓ⅩⅩⅩ✓✓✓Ⅹ✓✓Ⅹ, or could set up multiple “sock puppet “ accounts to carefully submit the same bad answers until a translation crossed an acceptance threshold. Methods to evaluate and control for trustworthiness are a topic of advanced study; we have no way of knowing how GT addresses this problem, but Picture 45 and Picture 46 demonstrate that bad verifications come through with some regularity.
Even cases where the community makes excellent verifications can ripple through to only limited improvements in actual translations. For example, type in the colloquial English party term “through thick and thin” and you will see not one, but two, verified 🛡 colloquial expressions in French that have the same meaning but do not use any words regarding thickness or thinness. However, vary your input a little bit, typing either “through thick and through thin” (the variation used by singer Randy Travis in a song that hit #3 on the country music charts) or a full sentence such as “She stuck by me through thick and thin“, and the system reverts to the word-for-word approach that renders the translation meaningless. (Spanish and Italian also translated the sentiment for the shorter expression, but slipped back to word-for-word in the other cases. I did not test the phrase systematically throughout the roster, but most languages seem to be word-for-word in all instances. You can test by typing “through thick and thin” on the English side of a chosen language, then individually reverse-translating the words to see if you get back “thick” and “thin” in English, as happens, for example, with Kyrgyz.) This demonstrates that Google is able to learn some stock phrases, varying by language, from its Translate Community platform, but it has not learned how to incorporate that information within its neurons.
When a bad translation is accepted by GT, it is ossified as the sole or primary result that will be returned for that phrase far into the future. For example, “Continua” in Italian has been poorly validated 🛡 as “Keep it going”, which left me befuddled when trying to find the “Next” button on a GT-translated e-commerce site. When a polysemous term is verified with a single translation, all other meanings will perpetually revert to that chosen sense. When a gendered translation is confirmed, half of users will be forever excluded. In the cases where GT is actually changing over time via user contributions (a maximum of 40% according to my tests over four years), those changes often lead to outcomes that are worse because they lock in information that is wrong in at least some contexts. I conclude, through empirical research across 44 languages, that crowd contributions to GT lead to definite improvements in a small percentage of cases, cement bad translations in another percentage of cases, and the majority of user submissions are ignored.
Qualitative Synopsis46
This chapter has shown how expectations about GT have been created, how public perceptions that GT produces scientifically-based translations in 108 languages have been cemented despite the objective low performance this study has measured, and why many of the myths surrounding GT are demonstrably false. We have been led to expect that GT performs like this:
In truth, for the top third of its languages, GT performs more like this, which is remarkable in many ways but is not mastery of the instrument:
However, for the bottom third of languages within the GT system, the video below hews closer to the results they have achieved. The next chapter looks at why translation is much more difficult than the industry leads us to believe, in an exposition of the linguistic challenges that GT and its competitors will never overcome for most languages, with the approaches on which they currently focus.
References
Items cited on this page are listed below. You can also view a complete list of references cited in Teach You Backwards, compiled using Zotero, on the Bibliography, Acronyms, and Technical Terms page. [zotpressInTextBib style=”apa” sortby=”author” order=”asc”]
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- link here: http://kamu.si/dangers
- Lune des moissons, Wikipedia. https://fr.wikipedia.org/wiki/Lune_des_moissons
- link here: https://teachyoubackwards.com/qualitative-analysis/#n-word
- link here: http://kamu.si/myth1
- Even my native English skills failed me the day our train from Oxford to London stopped in the town of Slough. “I can show you where we are on the map, but,” I admitted to my daughter, “I have no idea how to pronounce it.”
- This American Life: The Super. Episode 323, minute 25:19, January 5, 2007
- Worldometers, Africa Population (live).
- The 25-million word Helsinki Corpus of Swahili 2.0 is now available for research purposes. http://urn.fi/urn:nbn:fi:lb-2014032624
- link here: https://teachyoubackwards.com/qualitative-analysis/#point-1
- link here: https://teachyoubackwards.com/qualitative-analysis/#point-2
- To be clear, I have nothing against Larry Page. It is the ways in which the tech media invokes tech magnates and the corporations they run, creating false representations of what exists and what is possible, that is problematic.
- link here: https://teachyoubackwards.com/qualitative-analysis/#point-3
- https://twitter.com/cbcasithappens/status/1113955864858243074?s=20
- See the song “Jambo Bwana”, written by the Kenyan band Them Mushrooms in 1982, as shown in Disney’s “Lion King” cartoon: https://www.youtube.com/watch?v=-TaQaF3k9mc
- link here: https://teachyoubackwards.com/qualitative-analysis/#point-4
- The success of facial recognition in Facebook is one demonstration that image analysis is a stunning AI success. Note that Facebook reduces the complexity of the problem by restricting the possible candidates within a photo to the set of people within your friends list, rather than attempting to find facial matches among
- (possible) all people who have been tagged on Facebook,
- (not possible because not all have been tagged) all people who appear in photos online
- (even more impossible because many of the photos are in print form only, and many digital photos have not been uploaded to an accessible source) all people who have ever been photographed
- (similarly impossible to the AI challenge for thousands of undocumented languages) all people who have ever lived.
- The actual full intended sentence was “I will be in U.S. for a memorial service.” I would like to dedicate this chapter to the memory of my aunt, Laura Lambie Wallace (1943-2018).
- link here: https://teachyoubackwards.com/qualitative-analysis/#zotero
- Google Research Github repository: https://github.com/google-research/bert/blob/master/multilingual.md
- link here: http://kamu.si/flying-car
- Full disclosure: the author is an aviation buff who first learned how to fly in a two-person experimental aircraft, but gave up the hobby for financial and environmental reasons just shy of earning a private pilot’s license.
- link here: http://kamu.si/myth2
- link here: http://kamu.si/ooga
- I started to list a string of citations of the major articles from the Google team in this space, with credulous quotes such as “Johnson et al. (2017) show that a multilingual extension of a standard NMT architecture performs reasonably well even for language pairs for which no direct data was given during training” and “Most recent advances include systems which are able to do zero-shot translation (Johnson, Schuster, Le, Krikun, Wu, Chen, Thorat, Viegas, Wattenberg, Corrado, Hughes, & Dean, 2016), meaning that without parallel corpus from language A and B, the system is able to learn translation among these languages” and, “Perhaps due to the 60% fewer translation errors when compared with the previous phrase-based system, the study concluded that raters had trouble distinguishing MT from human translation”. However, the list began to look like a wholesale attack on every article about MT for the past couple of years, rather than a short compendium of how the limited findings from the Google articles have been amplified by repetition out of context. Not wishing to make enemies by harping on all the researchers who have given credence to the unsupported implications of the articles, I hit the delete key. You can, though, reproduce the experience by delving into the recent literature about NMT yourself.
- link here: https://teachyoubackwards.com/qualitative-analysis/#bleu
- The basic problem with BLEU is that it measures words, not meaning. The eight part, 20 hour Harry Potter movie series has been professionally translated to French at least twice, once for the voiceover artists and once for the subtitles used on Netflix. (Footnote to the footnote: Harry Potter 6 uses the same text for the voiceover and the subtitles. HP5 and both episodes of HP7 use different translations. I have not checked HP1, 2, or 3, which we watched in English, and we won’t watch HP8 until my daughter finishes the book.) Listening to the movies in French while reading the subtitles in the same language, which I usually recommend as a good learning technique, is a jarring experience, because the audio and written scripts contain different words and different phrasings. Yet, they are both perfect renditions of the original English (unlike Netflix subtitles in Swahili, which are monstrous MT carbuncles), and express exactly the same sentiments. On the other hand, a machine translation can produce almost all the same words as a human translation but make one small error that reverses the meaning or renders the phrase meaningless. Based on close attention to the dual French translations of Harry Potter 4, I would predict they would attain a BLEU score closer to 40 than to 100 if measured against each other (I am not volunteering to transcribe the dubbing text).
- The magazine that published this story, Fast Company, plays fast and loose with the truth, showing no interest in correcting errors and offering no channel for doing so. I have tried contacting them twice so far, first to alert them to the errors in their article and then to offer them a chance to respond to TYB. The first time, I got no response. The second time, I was blown off with a single sentence. Their editorial firewall is an interesting angle on promoting the integrity of their journalism.
- link here: http://kamu.si/fb-ai
- 25 million is a round number. If we go with the estimate of 7000 languages in the world, then the number of language pairs is 24,496,500 (=7000×6999/2). To arrive at 25,003,056 pairs, we would need to posit that the world contains precisely 7072 languages. Neither number is unreasonable. You really do not want to wade through the endless discussions of what constitutes a language versus a macro-language or a language versus a dialect – for example, the politics of what is often called “Berber”. Suffice it to say that neither 7000 languages nor 25,000,000 pairs are settled numbers, but are easy on the eyes and just slightly lowball the shifting total arrived at by the people at SIL’s Ethnologue – which is currently touting “7111 known living languages”, or 25,279,605 pairs .
- This geographic clustering is a phenomenon I have noticed, but not investigated. One possibility is that Google pools data-sparse languages in an attempt to squeeze out some hidden patterns. You could imagine it to be effective in a cluster such as Serbian/ Bosnian/ Croatian (essentially one language separated by military checkpoints), and some iffy potential in a group of cousins such as the Semitic trio Amharic/ Arabic/ Hebrew. They have written that they employ such procedures for related languages such as Russian and Belarusian, though have never mentioned it for Africa. There is no published justification for lumping unrelated languages that happen to be geographically proximate, such as Igbo and Yoruba, and no conceivable reason to put together languages like Amharic and Yoruba that are both linguistically and geographically distant.
- >National Ocean Service, “What are spring and neap tides?” https://oceanservice.noaa.gov/facts/springtide.html
- “Bamvua” is far from obscure, featuring in TUKI (2000), the Swahili Wikipedia (https://sw.wikipedia.org/wiki/Bamvua, and the Swahili Oxford Living Dictionary (https://sw.oxforddictionaries.com/ufafanuzi/bamvua)
- link here: http://kamu.si/myth3
- To be fair, this score is still better than their production Yiddish to English translation of “Lead from the back – and let others believe they are in front,” פֿירט פֿון הינטן, זאָלן אַנדערע מײנען אַז זײ גײען אין פֿאָרױס, which earns GT a 2.42 BLEU for “Due to the buttocks, other mice should walk in the front”.
- Linear Digressions, “Zero Shot Translation”, http://lineardigressions.com/episodes/2017/1/8/zero-shot-translation. January 7, 2017.
- A film from inside the cockpit of a jet experiencing engine failure en route from Zurich to Shanghai: Airbus A340 Emergency – Engine Failure, pilotseye.tv. https://youtu.be/rEf35NtlBLg. A film from inside the cockpit of a jet landing at a difficult airport: Quito Approach – Lufthansa MD-11F, pilotseye.tv. https://youtu.be/2gnSWCfPF3k
- link here: http://kamu.si/myth4
- Acronyms and initials defeat state-of-the-art MT, because they are copious, ambiguous, and usually not defined in useful ways in the available data training sources. Kamusi has a method in theory for harvesting and lexicalizing acronyms, but no funding for implementation. I did not conduct extensive testing of GT in this regard. We can observe that acronyms and abbreviations are sometimes recognized from English to top tier languages (for example, NGO is converted correctly to French, while ETA is not), and quickly degrade for the majority of languages where relevant data is sparse. A full measure of the rate of failure across languages would not be interesting, because it would be a question of whether the cup was mostly empty or completely dry.
- Pizza has made an entry in a few upscale urban locations where Swahili is spoken, so one could argue that the word exists at the periphery, but remains unknown for most speakers of the language. It does not appear in my inspection of all genuine Swahili documents on the web available through Google, other than as an untranslated English curiousity.
- This took 2 hours to create, so I hope you enjoy it!
- link here: http://kamu.si/myth5
- http://kamu.si/st-patricks-day
- Digital archeology could not dig up the original announcements in the LinkedIn archives.
- For example, in the “submit an edit” study, participants were asked, “What is the reverse translation of the Google result back to English?” Instead of pasting the result into the survey input box, one respondent answered, “Copy the text and change the language to English.”
- “Once 5 users that we trust say that it is good, then that submission can go into our short text translation system and sidestep the machine translation efforts and actually be served directly”.
- link here: https://teachyoubackwards.com/qualitative-analysis/#synopsis
We look at these problems from the perspective of an Adaptive Pattern Matching model that relies upon human constructed templates made up of units and units are made up of types.. there’s more to it than that… also given the convesion and diversion aspect of languages and missing concepts it is also beneficial to use a link-text language when required. Our ‘pattern matching’ system would involve the input of a redundancy factors…. this process can be hastened by using classification tools. Becase of the human guided factor and knowledge base this assists in the active development of language culture and… Read more »
[…] Google Translate supports translation of 109 languages, but not all language pairs are of equal quality or reliability. Studies have shown that the accuracy in Google Translate heavily favors European languages, such as German, Dutch, and Italian. When human translators reviewed certain other languages like Bengali, Urdu, and Punjabi, for instance, they ranked the translations completely inaccurate between 80-100% of the time. […]