References: Bibliography, Acronyms, and Technical Terms

Acronyms and Technical Terms
While most of the acronyms and terminology in this list are in common usage, some of the terms below are being introduced to the world for the first time in Teach You Backwards. Follow the links to reader-friendly sites that have more information about the technical topics. If there is a term in the book that is missing or poorly defined in the list below, please contact me so I can add it.
AI: Artificial Intelligence, the ability of computers to do clever things without specific programming instructions from humans. When a computer does something better than a human because it can process data really quickly, such as searching parallel texts to find all the words that seem to be translations of each other, that is not AI. When the computer makes extrapolations based on that information – for a made-up example, using a sentence that translates as “The jogger ran on the beach” as a model to produce “The sunbather san on the beach” (run/ran, so sun/san) – that is artificial intelligence.
Bard: This is the Teach You Backwards assessment of whether a translation has the natural elegance of a native speaker. A high Bard rating indicates translation that our native evaluators thought was similar to something they might produce themselves.
BEDS: Better than English Derangement Syndrome. Although people are fully aware that computers make numerous mistakes with English, the main language of the tech industry, many tacitly assume that the models for other languages are fully robust.
BLEU: bilingual evaluation understudy, an algorithm for evaluating the similarity between a computer translation and a reference human translation.
CAT: Computer assisted translation. CAT is a different animal than MT. In CAT, the computer places suggestions in front of a human translator, who is free to accept the suggestions, modify them, or take a completely different path, based on their understanding of the two languages. In MT, on the other hand, the user is presented with output as a more-or-less take-it-or-leave-it result.
Corpus (plural = corpora or corpuses): A collection of texts that can be used to extract linguistic data. A monolingual corpus can include billions of words in a single language, collected from books, newspapers, public records, blogs, tweets, and anything else that has been digitized and is publicly available. A parallel corpus matches two or more languages based on translated documents. Europarl is the most extensive parallel corpus, extracted from the proceedings of the European Parliament and professionally translated into all of the European Union’s official languages. Monolingual corpora for non-market languages are rare, and parallel corpora linking such languages with each other or with lucrative languages are almost non-existent. NLP and lexicography are quite often based on data from corpora, inherently excluding the supermajority of the world’s languages.
Disambiguation: A word like “pool” is ambiguous – out of context, you don’t know whether it refers to a place for swimming, a game played with balls on a table, a small group of people with a shared purpose, or a communal combination of funds. Disambiguation is the task of recognizing the ambiguity and figuring out which version is correct for the context.
FAAMG: Facebook, Amazon, Apple, Microsoft, and Google. You probably don’t need hyperlinks to find the relevant sites.
GT: Google Translate
HLT: Human Language Technology. Any software where processing human expressions lies at the core. Microsoft Word is not HLT, but the spell-checker within it is. The GoPro camera is not HLT, but the software that enables it to respond to voice commands is.
ICT: Information and Communications Technology
Kamusi: “Kamusi” is the Swahili word for “dictionary”. The word derives from Arabic, and similar words are used in many other languages across Africa, the Middle East, and the Indian Ocean. The Kamusi Project is a non-profit work-in-progress to build a dictionary and data center that will eventually provide nuanced connections among “every word in every language”, for people to use for their own language mastery and to deploy in their machines. Kamusi Here is the free mobile app that puts all that knowledge directly at your fingertips – for Android (http://kamu.si/android-here) and IOs (http://kamu.si/ios-here)
KOTTU: The bulk of the research for Teach You Backwards occurred in 2018 and 2019, when Google Translate reached into 103 languages. GT added 5 more languages in February 2020: Kinyarwanda, Odia (also called Oriya), Tatar, Turkmen, and Uyghur – herein abbreviated as KOTTU. These languages were immediately tested. Most of the results in TYB were updated to reflect the larger dataset. However, some of the numbers and charts remain in the pre-KOTTU state, because a lot of effort would be needed to recalculate what would be, in the end, quite small differences from the original test data.
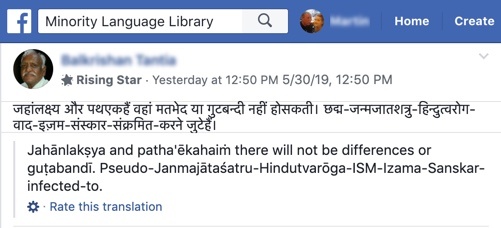
An example from Facebook of a translation that is replete with Lei Lies, where MT produces fake words such as “gutabandi” that do not exist in the target language. Of the 18 Hindi words in the original post, at least 8 are rendered with Lei Lies in English. The Google translation of the same text has more words that exist in English, but is also a MUSA koan: “Where there are targets and paths, there can not be differences or factions. Pseudo-congenital-Hindutva-rogas-ezam-rites-in-transmitted-are engaged in”
Lei lie: The invention of a word in the target language that does not exist in the parallel training vocabulary (as illustrated in Picture 5.2 and discussed in the associated Point 10 in the Introduction).
ML: Machine Learning, a process through which computers use previous results to improve their next round of outcomes.
MT: Machine Translation, the use of computation to convert text from one language to another.
MTyJ: Me Tarzan, you Jane. This indicates a rough translation, where the basic idea is conveyed from one language to the other, but the grammar and syntax are choppy.
MUSA: The Make Up Stuff Algorithm, the imperative for MT to produce some sort of output regardless of whether it has a basis in actual data. “Musa” is the equivalent name for the prophet Moses in many languages.
MWE: Multiword Expression. This is an extremely important concept in NLP. At Kamusi, we are doing a lot of work to identify, define, and translate MWEs across languages. For that work, we need the help of non-specialists who might find “MWE” to be a user-hostile acronym. We instead use the expression “party term”, coined at a meeting of EU experts, and urge other people working in linguistics and language technology to migrate with us.
NLP: Natural Language Processing, the task that joins computers and linguists in figuring out how the words we say can be made into data that machines can work with. The main academic field for this task is called Computational Linguistics.
NMT: Neural Machine Translation is the act of matching data from one language against data from another language, finding things that seem to correspond, and using that information to make translations in similar situations.
Party term: Two or more words that dance together, where you cannot understand the meaning by looking them up separately. For example, an African fish eagle, a type of bird that lives in Africa and eats fish, is neither an African nor a fish, so the expression does not make any sense unless the three words are understood together as a unit. Here is an example from the show “A Series of Unfortunate Events“, where the dramatic flow is paused for the narrator to interject this soliloquy about the party term he invokes:
It is now necessary for me to use the rather hackneyed phrase “meanwhile, back at the ranch.” “Meanwhile, back at the ranch” is a phrase used to link what is going on in one part of the story to what is going on in another part of the story, and it has nothing to do with cows or with horses or with any people who work in rural areas where ranches are, or even with ranch dressing, which is creamy and put on salads. – Lemony Snicket
Source language: In translation, this is the language you are starting from.
SMT: Statistical Machine Translation is the act of making informed guesses about which words in the target language are likely to correspond to ambiguous words in the source language, largely based on corpus frequency estimates.
 Smurf: spelling/meaning unit reference. Treating words as collections of letters creates intractable problems for MT, since something like l-i-g-h-t can refer to many things that are spelled the same way but have different meanings. A spelling/meaning unit is a unique combination of letters and the idea they signify, such as light that is not dark, or light that is not heavy. Spelling/meaning units can be single words, or they can be party terms. In Kamusi, each spelling/meaning unit is assigned what data scientists call a “unique identifier” so that we can pinpoint the term. We call these reference numbers “smurfs” so people will visualize the data as friendly blue cartoon characters instead of eye-glazing digits.
Smurf: spelling/meaning unit reference. Treating words as collections of letters creates intractable problems for MT, since something like l-i-g-h-t can refer to many things that are spelled the same way but have different meanings. A spelling/meaning unit is a unique combination of letters and the idea they signify, such as light that is not dark, or light that is not heavy. Spelling/meaning units can be single words, or they can be party terms. In Kamusi, each spelling/meaning unit is assigned what data scientists call a “unique identifier” so that we can pinpoint the term. We call these reference numbers “smurfs” so people will visualize the data as friendly blue cartoon characters instead of eye-glazing digits.
Target language: In translation, this is the language you need to use brain power or machine power to obtain.
Tarzan: This is the Teach You Backwards assessment of whether the gist of a translation can be understood by a native speaker, regardless of how inelegantly it might be expressed.
Trumplation: Reality-adjacent MT output that shifts from moment to moment. Different words might be placed on screen as a user types, or changes punctuation (such as whether or not the input string ends with a period). Output might also vary in different locations, on different browsers, or, like airline fares, at different times of day.
TYB: Teach You Backwards, the title of the Web Book you are reading right now.
Zero-shot translation: Attempts have been made to find areas where the translation space between Language A and English in one dataset and the space between Language B and English in another dataset overlap, and use those to make direct connections between Language A and Language B. It does not render viable translations, but it sounds super cool.

Zero-shot translation builds a bridge between two languages based on their connections through English, then removes the underlying English support. Image modified from The Stronghold Rebuilt.
References
[zotpress collection=”L68MPL5N” sortby=”author”]
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()