Molecular Lexicography

Molecular Lexicography: A Lexical Data Model for Human Language Technology
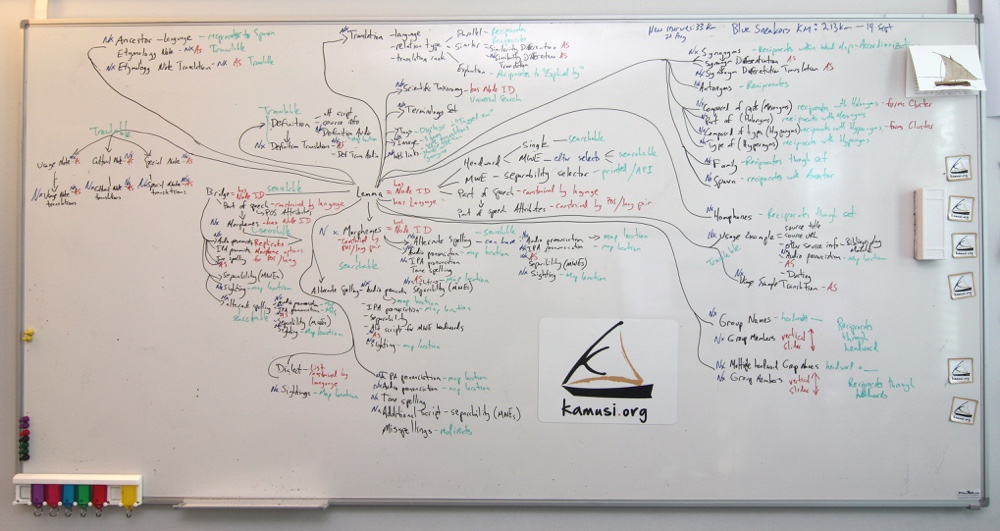 Introduction: The Kamusi Project began as a bilingual online dictionary between Swahili 1 and English; «kamusi» is the Swahili word for «dictionary». In the effort to expand the project to additional African languages, it became evident that a multilingual dictionary would need a new data model to account for the difficulties of aligning concepts among languages. In turn, development of that model revealed new potentials for organizing monolingual data. We call the data model for fine-grained monolingual data linked multilingually at the concept level “molecular lexicography”. This method of organizing linguistic data will port to significant future applications for human language technologies, especially for the African languages on which Kamusi focuses many of its data development efforts. This paper explicates the data model, with the intent of making evident how our output can be exploited by other HLT projects.
Introduction: The Kamusi Project began as a bilingual online dictionary between Swahili 1 and English; «kamusi» is the Swahili word for «dictionary». In the effort to expand the project to additional African languages, it became evident that a multilingual dictionary would need a new data model to account for the difficulties of aligning concepts among languages. In turn, development of that model revealed new potentials for organizing monolingual data. We call the data model for fine-grained monolingual data linked multilingually at the concept level “molecular lexicography”. This method of organizing linguistic data will port to significant future applications for human language technologies, especially for the African languages on which Kamusi focuses many of its data development efforts. This paper explicates the data model, with the intent of making evident how our output can be exploited by other HLT projects.
Note: The description below is a few years old. Some of the specifics have evolved since the molecular model was first developed. At the moment, we are working to implement the newest model, after which the description on this page will be updated.
The basic premises of the molecular model are:
- Each term 2 stands as a separate entity
- Terms are containers for a variety of discrete data elements
- Entities and their elements are joined in a matrix of relations
Aligning Concepts Across Languages: The starting point is the necessity of linking data multilingually at the level of the concept. Homonymy makes the “word” too large a unit for multilingual comparison; a word like «run» can have dozens of completely unrelated meanings. For example, knowing that Swahili «taa» translates to English «light» does not give enough information to extrapolate equivalents in other languages by matching to the English spelling cluster l-i-g-h-t. Only when we know that «taa» is an illuminating device can we confidently make a multilingual chain through known relationships; if we know that Rundi «itara», Hehe «tala», Gusii «oborabu», Tswana «tshuba», and Songhay «lanpa» are all translations of the English concept «light» as in a lamp, then we can posit that they are all translations of each other and of «taa».
taa = light = itara = tala = oborabu = -tshuba = lanpa
We can make a similar chain for the same languages surrounding the idea of «light» as low in weight:
-eupe = light = kitazize = -elu = see = tshetlha = haagante
By using a concept/spelling entity as our basic unit of analysis, we can build precise chains among any number of languages for any number of ideas, without getting tangled in happenstances of word shape.
Were languages to consist of neat binary equivalents between every idea, this would be the end of the story. However, languages do not map neatly, necessitating the first expansion of our data model (Benjamin 2014). Terms between languages can be linked in one of three ways: they are either parallel, similar, or an explanation in Language B of a concept that is unique to Language A. “Parallel” terms are easy; «rain» is likely to be water falling from the sky, the world around. “Similar” terms are more complicated; English «hand» and English «arm» are both “similar” to a single Swahili translation, «mkono», which is the part of the body from the shoulder to the fingertips. The “explanation” option is necessary because every language has culturally specific terms that need to be elucidated in a bilingual lexicon, such as the Swahili «kanga» fabric wrap worn by women for which no equivalent exists in European languages. For explanations, one language is marked as the explainer and one as the explainee, with the artificial term hidden from search in its own language.
Marking entries as “similar” is in itself too uninformative, so the data model now includes a “differentiation” field for explaining the difference between any two similar terms, e.g. “«Mkono» refers to the complete upper limb whereas «arm» is limited to the part from the shoulder to the wrist”. Even this is too restrictive, however; we also provide a field to produce the equivalent explanation in the opposite language, and fields for translating the differentiation into any other language.
With equivalency data in place, we are able to form more informative chains than indicated above. First, we have established a word map that shows the degrees of separation between entities; if a Hehe term is linked to one in Swahili, which is linked to one in English, which is linked to French, which is in turn linked to Songhay, then the Hehe is shown as a 4th degree relation to the Songhay. Equivalency adds the possibility of showing where the concept chain may break down, since similarity and explanations interrupt transitivity. With the word map showing degrees of separation and equivalence, it becomes possible to manually confirm or blacklist links that have been predicted by algorithm. Over time, this system will help sort instances such as the Bantu languages that share in parallel the Swahili concept beneath «mkono», and other languages that distinguish between «arm» and «hand», with such data being able to alert machine applications to zones of cohesion and zones of danger.
Basic Elements of Meaning and Function: Of course, to link a concept to other languages, we also need to know some essential details about the term. Our data model began simply, with “part of speech” (“POS”) and “definition”. However, “POS” reveals the need to account for elements such as plural forms and noun classes, while “definition” introduces the question of the language in which to write the definition. For the latter, we decree that “definition” is an explanation of a term in its own language; if the term is in Tswana, the “definition” field must be Tswana text. However, “definition translation” elements can be added for any language, so a Songhay “definition translation” could be added to the entry for a Tswana term. A field is also available to credit open sources from which definitions may have been borrowed. Further, multiple audio versions of the definition can be uploaded, a feature designed with predominantly oral languages in mind (Benjamin and Radetsky 2014); the audio will soon be able to be geo-tagged, and definition translations will also be able to have multiple and geo-tagged audio.
“Part of speech”, the basic indicator of how a term functions in a language, became the first point of monolingual expansion of the molecular model. Many parts of speech can have attributes, such as whether a verb is transitive or intransitive, or the class of a Bantu noun. These attributes vary based on POS and language. It is simple to set up attributes when configuring a language for the system, as long as someone can provide the information, by listing elements that can then be multiselected. However, word forms are much more complicated. For example, English verbs can have five variations that function differently (e.g., see, sees, saw, seeing, seen), Romance verbs can have dozens, and Bantu verbs can have hundreds of millions. Though linguists will rightly quibble, we label these variations “morphemes”. When the amount of morphemes is reasonable, they can be configured during language set-up, such as producing four input boxes for French nouns for the possible masculine/feminine, singular/plural forms. Bantu classes for adjective forms, sometimes with more than 20 morpheme slots, push the outer edge of reasonableness for this system; Romance verb conjugations will need a separate table structure that we have not yet implemented, and Bantu verbs can only be treated by parsing algorithms that are scripted for each language (with a parser already written for Swahili, though offline at the current writing). Terms can share a spelling set, so that repetitive data, such as conjugations for the French verb «faire» that has numerous senses, does not need to be input repeatedly; however, certain senses of a term might not share certain morphemes, so editors can adjust spelling correspondences manually.
Crucially, morphemes are treated as their own nodes, or sub-entities. This means that morphemes can be searched (eliminating problems in previous dictionaries about the location of word forms (Frawley, Hill and Munro 2002, pp. 3-5)), and linked to and from any other entity. A search for «saw» will reveal every sense of the verb «see» as well as «saw», a tool for cutting wood. The appropriate senses of «bows» and «boughs» can be linked in sound sets, discussed below. With machine translation in mind, a specific sense of French feminine plural «invitées» can be linked to a specific sense of Spanish feminine plural «invitadas». These are the sorts of links that begin to shape the metaphor of molecular bonding. Importantly, morphemes can be assigned the elements of alternate spelling, audio and IPA pronunciation, tone spelling, alternate scripts, and separability that are discussed below.
Bridges Between Methods of Expression: The data model also needs to account for instances where a concept in one language maps to a different method of expression in another language. For example, the German verb «achtgeben» translates to English «be careful» and French «faire attention» – but neither of the latter are proper entries in their own language. Rather, monolingual dictionaries typically list English adjective «careful» and French noun «attention», and bilingual dictionaries somehow fudge the relationship 3. The Kamusi model introduces “bridges”, which are custom nodes that editors can establish when necessary, such as creating a bridge to «be careful» as an element of the entry for the appropriate sense of the adjective «careful». Bridges have POS, which means they can take POS attributes and morphemes of their own. They can also take audio and IPA pronunciations, tone spellings, alternate scripts, alternate spellings, separability, and geographic sightings. Bridges and their morphemes are searchable and linkable.
Ways of Writing: As mentioned, both lemmatic and variant forms of a term can have elements that enhance our knowledge of their sound, shape, or range. For the canonical form and morphemes and bridges, our data model allows for multiple spellings, which are searchable and can further contain audio and IPA pronunciations, tone spellings, alternate scripts, separability, and sightings. Tone spellings and alternate script options should only appear for languages that are configured to contain them. Alternate scripts are fields that must be provided throughout the data model, since a language with two or more writing systems will use those to write information in every part of the dictionary.
Ways of Saying: Pronunciation has been handled poorly by every dictionary ever (Bronstein 1986, Landau 2001 pp. 118-127). Our model intends to change that. There are three problems. First, for any but the smallest languages, pronunciations vary across its geographic range. For example, English has different accents not just between Australia and South Africa, but even between different parts of London. Second, pronunciations are typically given for canonical forms, but not for morphemes, although the pronunciation of «teach» gives no clue to the pronunciation of «taught». Third, systems to capture pronunciation in writing depend on an agreed understanding of the sounds the various symbols represent. IPA, the international phonetic alphabet, is an excellent academic standard that can be interpreted by machine applications, but is not known by most dictionary users. Kamusi has fields for multiple IPA pronunciations in association with each other field where a spelling is input, which will be able to be pinned to a map. More importantly, each spelling field can also be associated with multiple audio clips that users can upload. With forthcoming programming, participants will register the geographic location where they spent the bulk of their childhood, and their audio contributions will be pinned to that place. 4 Such pronunciation data will be especially useful in future speech recognition and speech synthesis technologies.
Mapping Dialects: “Dialect” has also been poorly handled by previous dictionaries (Crystal 1986, Landau 2001, pp. 119-226). The essential problem is that nobody can say exactly what a dialect is – at what point are groups speaking different dialects versus pronouncing words differently and having some vocabulary variation, and at what point are two ways of speaking so different that they constitute different languages instead of different dialects? In our data model, a term can be labeled as belonging to one or more dialects if the larger language has been configured with a list of options. We plan what we propose will be a more relevant feature, however, “sightings”. Users will be able to pin locations where they know a given term to have been used, whether from their research or life experience. In this way, the nebulous category “dialect” can give way to data that shows the actual geographic range of each term.
Multiword expressions: MWEs have given lexicographers and human language technologists conniption fits since time immemorial (Sag, Baldwin and Bond 2001, Atkins and Rundell 2008, Rayson, et. al 2010). The Kamusi model introduces two new approaches to MWEs. First, when a lemma is composed of more than one word, an editor can select multiple headword options, e.g. «African fish eagle» can be listed under “eagle” and “fish eagle” as well as the full term, but not “African”, “fish”, or “African fish”. Second, MWEs can be marked as to whether and where they can be separated by other text, such as «drive | up the wall» where “drive” and “up” can be interposed with any number of other words. In the future, separability data can be run with corpus analysis to build sets of likely terms that could occur within a particular MWE. In the nearer term, machine translation can use the information to detect separated MWEs and recover their meaning, a feat that is not possible with today’s state of the art technology. Separability is an option for lemmas, morphemes, bridges, and alternate spellings.
Time and Language Evolution: Our model introduces several new features to the temporal information that can be associated with a term (Landau 2001, pp. 127-134). To begin with, a term can be linked to its “ancestor”, whether in its own language or a different or earlier language. In principle, historical languages can be treated within Kamusi exactly the same way as living languages, so links can be established to, for example, a specific concept/spelling in Old English. Second, a reciprocal relationship is established between an ancestor and its “spawn”, so maps can be built that show how terms are related historically. Third, we are planning “dating” fields that can indicate first and last known use in association with usage examples, though this will involve headaches adding bibliographic citation fields, so is currently back-burnered. Finally, our open text field for “etymology note” has the option to add translation fields for any language, such as a Wolof “etymology note translation” for the origins of a Pulaar term.
Precision Usage: Terms may belong to specialized vocabularies, such as the computer term «cache» temporary electronic storage; for the moment, users can select from a prepared list of possible terminologies, with future programming needed to allow users to propose new terminology labels. Domain information can improve technical writing and translations, for example prioritizing «rock» the stone substance over «rock» the music in the context of geology. For additional information about precise usage situations, we also have open text fields for “usage note”, “cultural note”, and “special note”. Each of these fields has options to be produced and be revised over time in any language, but only one note of one kind per language.
Reciprocal Bonds: Several kinds of reciprocating data exhibit different manners of molecular bonding. While the list is exhausting, it is not exhaustive, with more fields, such as holonym type, to be added in the future.
- Synonyms. 5 This is a critically important category, which has several special aspects (Benjamin 2014). First, people have a tendency to confuse synonyms and definitions. In Kamusi, a definition is an explanation, whereas a single word equivalent is listed as a synonym and linked to a specific concept/spelling entity. These synonyms become part of the word map of a concept, with degrees of separation to other terms in the same language and others; e.g., if «light» is linked to Swahili «taa», and «taa» is linked to «lamp», then «light» and «lamp» are shown as 2nd degree relationships until they are manually joined. Additionally, synonyms share a “differentiation” open text element that can be used to explain, for example, the difference between «boat» and «ship», and that field can be translated to any language.
- Antonyms. If «give» is the opposite of «take», then «take» is the opposite of «give». Here one can see the importance of linking between specific concept/spelling entities, lest «give» to emit a sound (give a shout) be paired against «take» to endure (take the pain).
- Meronyms and holonyms, a.k.a. parts and wholes. If «wing», «feather», and «beak» are parts of «bird», then «bird» is composed of the parts «wing», «feather», and «beak».
- Hyponyms and hypernyms, a.k.a. types and categories. If «eagle», «osprey», and «sparrow» are types of «bird», then the category «bird» is composed of types «eagle», «osprey», and «sparrow». Charting these sorts of ontological relationships is important for various text analysis technologies.
- Ancestors and Spawn. These fields show where a term came from, and what terms have descended from it. Therefore, the fields have language selectors, so we can follow the trail of Swahili «hidrojeni» back to English «hydrogen» back to French «hydrogène» back to its Greek roots.
- Family, such as «operator», «operationalizable», and «operating table». One or more entity with the same spelling can belong to a “family” set.
- Tags. This field enables participants to connect concepts that might not have evident linguistic or semantic relationships, such as joining «arson» with «wildfire» or «insurance». The relationship between tagger and taggee is not reciprocal – «wildfire» should not show «arson» by default. However, the tag from «arson» should appear on the «wildfire» display page as “tagged in”, and the link should be deleteable from the taggee entry.
- Scientific taxonomy. Flora and fauna can be classified with one or more universal taxonomic designation, such as «tomato» Solanum lycopersicum. These taxonomies can be used to discern when different languages are talking about the same natural entity, when one language has several names for the same thing, and when things are seen to be the same or different (e.g., if different mushrooms have different terms in a language, or are all considered as one). Taxonomy terms are language-independent, and all terms that share a taxonomy can be linked on the word map.
- Homophones. Our model makes it possible to show which terms in a language sound alike despite different spellings, or sound different despite being spelled the same. Terms such as «wind» (wrap around), «wined», and «whined» (the latter two being morphemes that can linked) can be joined, while «wind» (blowing air) can be kept out of the pronunciation set. Future programming will refine the system geographically, e.g. «line» and «lion» are homophones in certain parts of the American south. Homophone data will have implications for speech recognition and speech synthesis technologies, including voice-to-voice translation.
Examples and Illustrations: Usage examples are one of the most potent ways of understanding the nuances of a term, including its meaning and how it functions grammatically. The Kamusi model builds on best practices (Landau 2001, pp. 207-211), and also introduces several improvements of “examples”. First, an unlimited number of examples can be included. Second, examples are strictly segregated for each concept/spelling entity. Third, those examples can each be credited to their source, with work planned to expand bibliographic citation options. Fourth, we will soon add a field to date the occurrence, allowing insight into when a term has gone in and out of use. Fifth, audio can be added, to the aid of the visually impaired and for languages that are predominantly oral. Sixth, usage examples can be translated to any language, providing learners with a path into complex sentences and producing real world sense-disambiguated parallel text for future translation technologies. Finally, because Kamusi is “living”, users can add examples from their daily reading; a forthcoming mobile app feature will make it simple to add examples one encounters with a few clicks on a mobile device.
Multiple web links can be included that point toward other sources of information about the designated concept. Web links will be shared with synonyms, but not translations. Multiple images (Landau 2001, pp. 143-47, Frawley, Hill and Munro, pp. 10-11) can also be uploaded to an entry. Future programming will share images across a translation/ synonym set, enable linking to images elsewhere on the web, enable geo-tagging of photographs, and make it simple to upload illustrative photos directly from our mobile app.
Putting Words in Order: Finally, the data must be organized, so that headword searches display all spelling matches in some logical order. Unlike many dictionaries that group together all the verb senses of a word, then all the nouns, etc., the Kamusi model arranges words based on concept relations. Therefore, one group of «light» includes the verb senses for lighting a fire and lighting a cigarette, as well as the nouns for matches and cigarette lighters, while another group includes lamps, streetlights, and the action of illuminating a room. These groups must be separated with a simple label, such as {light: fire} or {light: illumination}. All members of a group can be ranked, so that, for instance, the sense of match appears above that of cigarette lighter. Groups can themselves be ranked, so that lamps appear above fire. Furthermore, translations can be ranked; if one sense of Swahili «tembea» translates to both «stroll» and «walk», the latter can be ranked as higher priority. At this writing, previously functioning programming for grouping and ranking has not completed the transition from the monolingual model to the more complex multilingual system.
Conclusion: The model described in this paper is intended to enable the production of the full matrix of human linguistic expression across time and space. This is an insanely tall order, for which complete data will never be available. However, the structure is designed with the goal in mind. The framework makes it possible to describe and interrelate each concept in each language, connected as atoms within a molecule at the levels of grammatical function, meaning, place, shape, sound, time, and translation, as shown in the table below. Different elements can bond in different ways within and between languages – what we conceive of as molecules interacting – allowing for intricate data representations that would not otherwise be possible. The method of organizing and retrieving the data can have substantial uses for language learning, documentation, preservation, and revitalization, as well as for future technological developments in natural language processing. Much of the programming has already been implemented, with other elements on the task list. It is likely, of course, that the model is not as complete as it could be, so we welcome comments about what we have missed.
References:
Atkins, B.T, & Rundell M., The Oxford Guide to Practical Lexicography, Oxford, 2008.
Benjamin., M. Elephant Beer and Shinto Gates: Managing Similar Concepts in a Multilingual Database. 7th International Global WordNet Conference, Tartu, Estonia, 2014.
Bronstein, A, The History of Pronunciation in English Language Dictionaries, in The History of Lexicography, Reinhard Hartman, ed., John Benjamins, Philadelphia, pp 23-33, 1986.
Benjamin, M. and Radetzky, P. Small Languages, Big Data: Multilingual Computational Tools and Techniques for the Lexicography of Endangered Languages. 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, Maryland, USA, 2014.
Crystal, D. 1986, The ideal dictionary, lexicographer and user. In R. Ilson (ed), Lexicography: an emerging international profession, Manchester University Press, 72-81.
Frawley, W., Hill, K., and Munro, P., Making Dictionaries: Preserving Indigenous Languages of the Americas. University of California Press, Berkeley, 2002.
Rayson, P., Piao, S., Sharoff, S., Evert, S. and Moirón, B., Multiword expressions: hard going or plain sailing? Language Resources and Evaluation, 44:1–5, 2010.
Sag, I., Baldwin, T., Bond, F., Copestake, A., & Dan, F., Multiword expressions: A pain in the neck for NLP. LinGO Working Paper No. 2001-03, Stanford University, CA, 2001.
| Data Field | Function | Meaning | Place | Shape | Sound | Time | Translation |
| Additional script spelling | √ | ||||||
| Alternate spelling | √ | √ | |||||
| Ancestor | √ | √ | |||||
| Antonyms | √ | ||||||
| Bridge | √ | √ | |||||
| Composed of parts (Meronyms) | √ | ||||||
| Composed of types (Hyponyms) | √ | ||||||
| Cultural Note | √ | √ | |||||
| Cultural Note translation | √ | √ | √ | ||||
| Dating | √ | ||||||
| Definition | √ | ||||||
| Definition translation | √ | √ | |||||
| Dialect | √ | ||||||
| Etymology and Historical Notes | √ | ||||||
| Etymology Note translation | √ | √ | |||||
| Example Sentence | √ | √ | √ | ||||
| Example sentence translation | √ | √ | √ | ||||
| Family | √ | ||||||
| Group Name | √ | √ | |||||
| Group Rank | √ | ||||||
| Headword | √ | ||||||
| Homophones | √ | ||||||
| Image | √ | √ | |||||
| Is a part of (Holonyms) | √ | ||||||
| Is a type of (Hypernyms) | √ | ||||||
| Lemma | √ | ||||||
| Morpheme | √ | √ | |||||
| Part of Speech | √ | ||||||
| Part of Speech Attributes | √ | ||||||
| Pronuciation (audio) | √ | ||||||
| Pronunciation (IPA) | √ | ||||||
| Scientific taxonomy | √ | √ | |||||
| Separability | √ | √ | |||||
| Sighting | √ | ||||||
| Similarity Differentiation | √ | √ | |||||
| Similarity Differentiation translation | √ | √ | |||||
| Spawn | √ | ||||||
| Special Note | √ | ||||||
| Special Note translation | √ | √ | |||||
| Synonym differentiation | √ | ||||||
| Synonym differention translation | √ | √ | |||||
| Synonyms | √ | ||||||
| Tags | √ | ||||||
| Term language | √ | ||||||
| Terminology | √ | ||||||
| Tone spelling | √ | ||||||
| Translation | √ | ||||||
| Translation rank | √ | ||||||
| Usage Note | √ | ||||||
| Usage Note translation | √ | √ | |||||
| Web links | √ |
1 All language names are stated in their English exonym form, not as autonyms.
2 A “term” in this context is one or more words with a particular meaning, to be distinguished from a “word”, which we use in the data model description to refer to a cluster of letters that may have multiple meanings.
4 The Forvo web service works similarly to our vision for user uploads, though without links to other lexicographic information, without concept/spelling granularity, and without geographic distinctions for IPA. For example, it is not possible with Forvo to know when or where to pronounce «bow» as baʊ or as bəʊ.
5 Work is in the planning stages to tease apart WordNet synsets within this system, so that the widely used PWN English and GWN multilingual datasets can leap beyond spelling relations.
![]()