Disruptive Approaches for Next Generation Machine Translation

The previous parts of this web-book have discussed what Google Translate (GT) does and does not accomplish, with special attention to things that it cannot accomplish because of features inherent to machine translation as we know it. In this part, I briefly introduce some new paradigms. Many of these have already been piloted successfully at Kamusi, some are under active development, and some cannot be tried until more groundwork is laid or until funds can be found. To make use of the ongoing efforts the author directs to build precision dictionary and translation tools among myriad languages, and to play games that help grow the data for your language, please visit the KamusiGOLD (Global Online Living Dictionary) website and download the free and ad-free KamusiHere! mobile app for ios (http://kamu.si/ios-here) and Android (http://kamu.si/android-here). How much did you learn from Teach You Backwards? Your appreciation is appreciated!:
Some of the ideas in this chapter are not controversial, but others are antithetical to precepts within the machine translation (MT) community. Among computer scientists, it is a matter of faith that improved machine processes are the chief path to improved translation. I do not dispute that improved computation will continue to push MT incrementally forward. However, most such improvements are only possible in cases where rich corpora are available and attention is paid to models of the languages involved. Where data is sparse or inexistent, MT is impossible. Even where substantial data is available, though, this chapter argues that the most promising pathway toward imbuing translations with meaning lies in collating data from the speakers of each language based on what they know, more than in inferring connections based on computed textual patterns. Computation can be used to extract the questions that need to be asked of human interlocutors in order to gather data, and computation can be used to parlay the knowledge humans provide into programs that remix the data in ways that people never could – envision connecting a Guarani-speaking student in Paraguay with her Mansi-speaking contemporary in Siberia to work on a school project together, using an MT intermediary in their chat service that builds on (currently unavailable) data and models for those languages. However, until neuroscientists can put USB ports in our skulls and download the linguistic data housed in our crania, the only way to get 99.96% of that data is to ask the people in whose brains it lives: deep learning directly from the people who speak a language. This approach cuts against the grain of most current work in MT. Many will say it is pie in the sky, that clever computing is the path toward universal translation. I say, read this chapter to the end. If you find flaws, raise them in the comments section, so the plan can grow from your insights. And then join in – play the games developed for your language, use the products that emerge, hack, donate, tell your friends – and let’s disrupt the translation industry with translation that really translates.
I would like to share with you the ideas we are developing at Kamusi Labs in direct response to the question, “If Google is not capable of translating among 7000 languages, how can that goal ever be reached?” Below, I lay out a strategy that I assert can lead to much better translations than GT and its competitors, among many more languages. Dozens of institutions around the world have signed letters of collaborative intent to join forces on a Human Languages Project, using what is outlined in this chapter to build a matrix of human expression across time and space to the greatest extent possible, if we can find funding to support the work involved. Perhaps I am delusional and what I propose is technically impossible, though no debilitating linguistic or computational flaws have been identified to date by peer reviewers (who sometimes object to elements as utopian, unproven, or overly ambitious, and often suggest overlooked elements that end up improving the model). Perhaps I am selling my own brand of snake oil, though, given the minuscule Kamusi budget, I am clearly not a good salesman. Or perhaps it is time to disrupt the MT industry, and what is described herein really is the next step on the journey to universal translation.
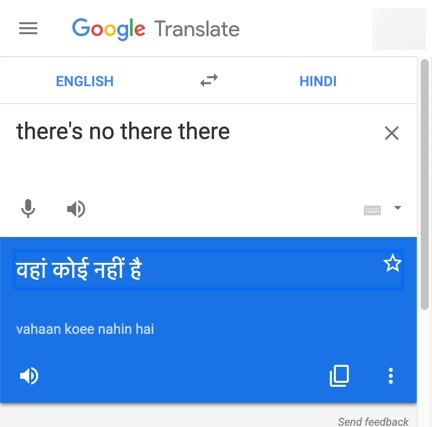
Picture 51.1. The Hindi translation of the common English expression “there’s no there there“, वहां कोई नहीं है, translates in GT with words meaning “no one is there”, and the French meaning is “it is not there”. Google Search reveals over a quarter million pages with the English quote.
I will begin with the assertion that we actually can attain human-quality translations for expressions like “there’s no there there“, and even for each of the sentences shown as “Absurdities” below, and millions more, into, out of, and among all 108 GT languages and on towards 7000. This statement reeks of hubris, and I do not expect to accomplish universal translation before retirement, but it is helpful to define the 🌈 goal. In fact, I will extend the ambition a little farther. The systems we are developing will enable translation of sentences like these into any language:
Absurdity 1.
- Light light light light light light light light light light.
- (1) Light (2) light (3) light (4) light (5) light (6) light (7) light (8) light (9) light (10) light.
- (1) Light-weight (2) non-heavy people (3) who ignite (4) bright (5) visible energy (6) illuminate (7) non-serious (8) light-weight (9) non-heavy people (10) lightly.
Absurdity 2.
- Best worst worst worst worst worst best best best best best worst worst best best best.
- (1) Best (2) worst (3) worst (4) worst (5) worst (6) worst (7) best (8) best (9) best (10) best (11) best (12) worst (13) worst (14) best (15) best (16) best.
- (1) The top (2) of the bottom (3) who defeat (4) the absolute (5) bottom people (6) most poorly (7) ought to (8) beat (9) most ably (10) the top (11) of the top (12) who destroy (13) the least (14) good (15) finest clothing (16) most ably.
Absurdity 3.
- Pick up pick up picked picked up picked up pick up pick up up.
- (1) Pick up (2) pick up (3a) picked (4) picked up (5) picked up (6) pick up (7) pick up (3b) up.
- (1) The truck driver’s (2) casual date (3a) collected (4) the reenergized (5) lifted (6) hitchhiker (7) stimulant (3b) [connect to 3a]
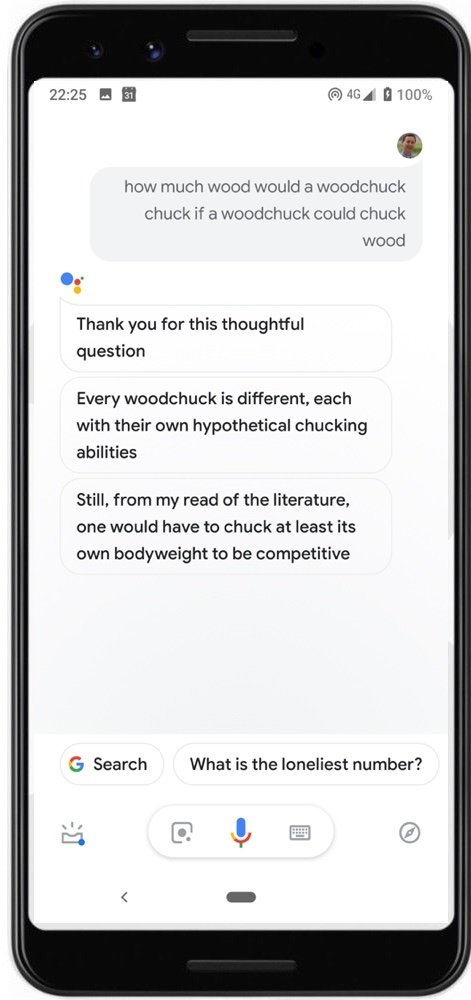
These absurd yet technically grammatical sentences were crafted to demonstrate ambiguity at its extremes, to highlight the impossibility of a computer divining the meanings needed to translate ambiguous items in many situations. Whereas GT translates the first absurdity into Maori as “Rama marama marama marama marama marama marama” (Lamp brightness brightness brightness brightness brightness brightness), and provides similar results for its other languages, I argue that a well-thought-out collaboration between people and our machines can enable MTyJ (Me Tarzan you Jane) or better translations across the board, even for preposterous sentences such as those above. Google has accomplished such an NLP feat with certain English phrases in its Assistant application, hiring a team to prepare humorous canned responses to voice input such as “how much wood would a woodchuck chuck if a woodchuck could chuck wood?” (Picture 51.2). Yet – try it yourself – the same sentence in GT generates wild stabs in every language, scampering to the computational drawing board instead of building on human insight. Although the people at Google Assistant recognize it as an iconic English artifact, the “woodchuck” absurdity does not exist in any parallel corpora so it cannot be gleaned through NMT. That does not mean such absurdities, or the infinite other linguistic combinations that cannot be fathomed through automatic comparisons, cannot be translated. Let’s enumerate what is needed.
- A set of definitions for each term in a language (often known as a dictionary), separated so that each individual sense of a polysemous term can be treated as its own entity. This will make it possible to distinguish that the “light” in position 2 of Absurdity 1 has one particular meaning, and the “light” in position 6 has a different meaning.
- A set of translations from the concept-designated terms in the source language to terms with equivalent meaning in the target language. This makes it possible for the machine to propose a word that corresponds to the idea of “non-heavy people” for the noun in position 2 of the first absurdity, and a word that corresponds to the idea of “illuminate” for the verb in position 6.
- A means of identifying inflected forms of a word and mapping them back to the lemmatic form, for example recognizing that “bought” is really a form of “buy”. This makes it possible to produce the correct vocabulary for non-canonical forms on the target side, along with the knowledge of elements such as tense that can be used to produce the correct morphology.
- A means of identifying elements of the sentence according to part of speech, gender, register, or other relevant aspects. This will make it possible to seek and position equivalent elements on the target side.
- Language models for each language that identify features such as the order of nouns and adjectives. This makes it possible to arrange vocabulary pieces according to syntactic patterns, pushing translations from Tarzan toward Bard.
- A method to identify the parts of a party term so they are treated as a lexical unit, rather than as individual words. This makes it possible to correctly treat elements such as “up” in position 3b of Absurdity 3.
- Methods to identify terms or concepts that are not in the database, and to gather them from digitized or human resources. This makes it possible to expand translation beyond the present set of digitized data.
Taken individually, none of these components is extraordinary. Pause: an invited reviewer reacts, “I would go ahead and say that all of these components are extraordinary. They all pretty much face insurmountable bottlenecks given the current state-of-the-art, so stringing them together is not likely to end well.” Response: One hundred years ago, nobody imagined that a network of highways, tunnels, and bridges would make it possible to drive comfortably from Tromsø above the Arctic Circle to Ankara in Turkey, although roadways and bridges go back at least to Roman times, long tunnels came in with the railroads, and the Ford Model T had already been in production for a decade. Although the only route across the Strait of Gibraltar today is via ferry, you would not be the least surprised to ride in an autonomous vehicle across a bridge connecting Europe and Africa sometime before you die – after all, 44 bridges on the planet already span a longer distance. Today’s transport networks were built one element at a time, using known technologies when they worked and improving on those ideas when they didn’t; while the fact we can now ride in a train across the English Channel is an amazing feat of engineering, serious engineering proposals for the dream began as far back as 1802, and exploratory tunnels more than a mile long were dug on both the French and English sides in 1881, before any but a couple of handfuls of people who lived to see it completed 113 years later had been born. I am not saying that the vision laid forth here for translation is easy. I am saying that it is comprised of elements that already have established templates in languages spoken by the wealthy, and for which the extension to any other language is therefore more a question of will than technology [zotpressInText item=”{AVTZA3CH}”]. Just as the transport network was built with one traffic circle in Aberdeen and one stop light in Athens, the entire field of NLP is devoted to building bits and pieces that could collectively enable MT across whatever languages society deems valuable. However, billions of dollars using the methods GT has deployed to date cannot get us to truly effective translation across large numbers of languages because the data does not now exist in a form technology could ever act on, and what data can be collected cannot be deployed without a great deal of human input to carefully steer the efficiencies offered by computation. Regarding the 7 points above, then:
(1) Dictionaries per se are a venerable technology, and opuses such as the Oxford English Dictionary prove that they can thoroughly document most expressions in a chosen language. Digitizing lexical data is relatively new, but e-lexicography is now an established pursuit. Separating out senses in ways that can be repurposed in other data applications is uncommon (for example, it cannot be done from any online dictionary other than Kamusi, for English or any other language), but has been given a hearty first pass for English in a way that can be parsed by the data savvy with the Princeton WordNet [zotpressInText item=”{CFL9WFRU}”].
(2) Matching those English senses to equivalent terms in other individual languages has been done with varying success by several dozen international wordnet teams, and aligned in differing ways by the Open Multilingual Wordnet and by Kamusi.
(3) Morphological identification has been handled in various ways by toolkits that researchers have developed for the languages that matter to funders, such as FreeLing that is available for demo in 13 languages.
(4) Successful grammatical models have been built for many languages, though not all are available open source. Researching and implementing a model is often an appropriate Master’s level thesis project. Some portion of the world’s repertoire of languages could be doled out to interested students every year, with the goal of interoperable models for thousands of languages over the course of a decade. The obstacle is funding.1
(5) MT-focused syntactic models also exist for many languages. For languages where models exist, it should be possible to generate somewhat grammatical text between any Language A and Language B by wiring together the known elements such as vocabulary, subject, object, tense, and gender. All five of these components have been done for privileged languages such as Norwegian. What can be done for Norwegian can be done for Northern Nuni (spoken by about 45,000 people in Burkina Faso), if people choose to do so. The technology is the same and the process is the same. If the will of the people who fund language technology resources is drastically different, that is a social and financial decision by the nation of Norway (Norad and the Ministry of Education and Research) that Norwegian children are more worthy of investment than are Burkinabe , not one of technical viability.
(6) As discussed in the chapter on translation mathematics, party terms are an ongoing Achilles’ heel for MT. Kamusi is developing a method for identifying and translating party terms, described below, that should work out of the box for any language, regardless of the distance by which words are separated within the expression.
(7) Gathering terms and meanings is the established field of lexicography. Unfortunately, the time, money, and effort to pursue extensive lexicons of most languages are prohibitive, with few people imagining that OED equivalents for languages like Kinyindu (spoken by about 10,000 people in eastern Congo) could really come to be. Kamusi Labs has developed technology, now available in the Kamusi Here app’s participatory features described below, that can lead to the rapid production of rich monolingual dictionaries for each language, linked as MT-ready data between languages – and we will be field-testing the system with our Kinyindu partner organization when we can fund their efforts. Further, our “SlowBrew” system for disambiguation of terms and the identification of party terms on the source side, in advanced construction, will be capable of bringing vocabulary errors close to zero. The unsolved constraints to collecting the words of most languages are financial, because potential funders either believe that it is not worth doing, or that Google has already done it.
The semantics of translation2

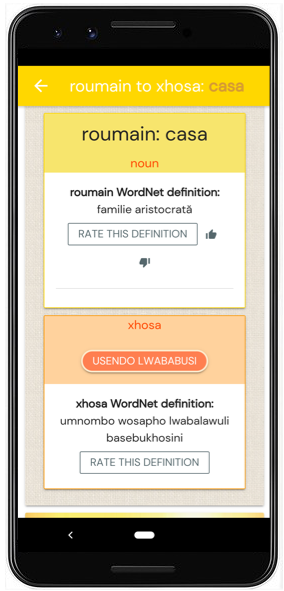
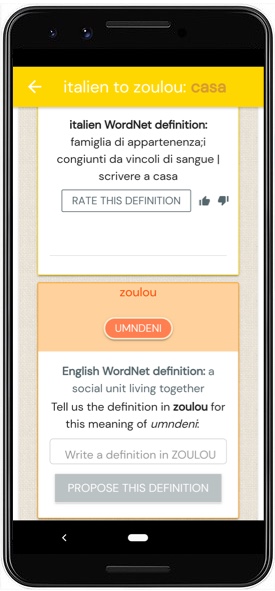
Picture 52: A head to head comparison of results from Kamusi (left) and results from GT for the same search.
Many examples of MT failure throughout this paper have hinged on ambiguity, particularly the problem of polysemy. Kamusi has largely solved this problem. Our system aligns terms across languages based on the underlying concept, rather than a crude approach centered around the happenstance of English spelling. Our initial implementation is a relatively simplistic interlinking of data from the Global Wordnet across 44 languages and counting; as time goes on, we will expand the concept set far beyond those covered by Wordnet, account for morphology and semantic drift, and extend to hundreds or thousands of non-market languages. To demonstrate the difference in accuracy between GT’s best-guess term translations and Kamusi’s semantic-equivalency approach, I have prepared a head-to-head comparison between the two. These are screenshots from the live versions of the KamusiHere! and Google Translate mobile apps, for the same set of searches. The images show how the Kamusi model provides much more precise vocabulary than Google is capable of. Although the Kamusi data is still young, you can already see how much more confident you can be in its results. The first matchup shows results between English and another language, in this case Chinese. In this scenario, Kamusi shows each sense, with enough information for a user to decide which term matches their intended meaning. GT, on the other hand, shows some options, but not enough context to make a determination. The remaining screenshots show matchups between non-English pairs, using Greek, Romanian, and Italian as the sample cases. GT provides one guess per pair, whereas Kamusi gives a valid match for each polysemous concept for which data has been collected to date.
To achieve the level of specificity needed for precise translation, we deal internally, ironically, with numbers instead of words, as illustrated in Picture 52.1. Each sense of each word is a “spelling/meaning unit”, so each one gets its own “smurf”, or “spelling/meaning unit reference”. This is Data Science 101: a nebulous tag causes problems, and a unique identifier solves them. For example, in 2001, about 9000 Floridians were erroneously scrubbed from the voter roles because they had the same name as a dead person or convicted felon [zotpressInText item=”{75447N4A}”]. Consequently, the National Research Council [zotpressInText item=”{5V3QFZDY}” format=”(%d%)”] recommended that voter registration databases across the 50 American states work toward coordination through clear numerical indicators such as Social Security number, so as not to disenfranchise one Willie Whiting (SSN 640-34-8769) because of the crimes of another Willie Whiting (SSN 251-02-0883). At Kamusi, we invoke unique identification of a spelling/meaning unit as a fundamental precept. That is, “dry” (not wet) is assigned a unique ID, “dry” (boring) has a completely different number, Italian “secco” (not wet) has a different number, and “secco” (very skinny) has yet another. Let us say (using mini-smurfs to ease the visualization):
-
- dry (not wet): smurf = k-1112
- dry (boring): smurf = k-2346
- secco (not wet): smurf = k-8745
- secco (very skinny): smurf = k-5540
- noioso (boring [Italian]): smurf = k-6413
- 마른 (not wet [Korean]): smurf = k-3033
- 지루한 (boring [Korean]): smurf = k-9796
With the spelling/meaning units converted to numbers, it is then a cakewalk to store k-1112 = k-8745. We can also store k-1112 = k-3033. Following the rules of transitivity, k-8745 = k-3033. Thus, we have high confidence that secco = 마른. Furthermore, k-6413 = k-2346 = k-9796, so noioso = 지루한.
Using this method, we can easily see that there is no relationship between either k-8745 or k-5540 and k-9796: secco ≠ 지루한. Contrast the GT method – if secco matches to d-r-y in the English-Italian dataset, and 지루한 matches to d-r-y in the English-Korean data, then standard MT posits secco = dry = 지루한 – a very skinny Italian comedian has a good chance of being known in Seoul as a boring person of indeterminate weight. Using the smurfs, meanings never cross. Using statistical or neural methods, though, such crossing is inherent to the procedure.
In many cases, a term in one language will only be approximately equivalent to the term given as its translation in another language, the problem of semantic drift. That is, perhaps k-6413≅ k-2346, and k-2346 ≅ k-9796. For the moment, we address the issue by displaying all the information that we have about the term in Language A, (k-6413) the term in Language C (k-9796) , and the English term that established the bridge (k-2346); that is at least a starting point for the user to evaluate whether they are really looking at the same concept on both sides. Unfortunately, in many cases our data did not arrive with proper definitions of the local terms; instead local teams relied on the Wordnet definition of the English equivalent, which often misses the strike zone [zotpressInText item=”{PXAAPPJ6}”]. We are implementing processes to elicit local definitions from users. In the future, users will mark cases that have only partial semantic equivalence – terms are considered “parallel” if they are generally the same idea, “similar” if they have partial conceptual overlap, and “explanatory” if we are producing a stock phrase to fill a lexical gap. This will enable us to establish a confidence index, so we can give an honest alert about the more dubious automated matches.
Picture 52.1: Translation relationships among terms in different languages in the Kamusi database. Terms and features (such as part of speech and inflections) are expressed as numbers. Those numbers can be joined in various ways for translation and other natural language processing tasks. Information about relations for how various senses of “dry” relate to their equivalents in dozens of other languages is embedded in those numbers. The computer never tries to guess which sense of “dry” matches across languages, as occurs in present-day MT systems such as Google. Do not spend too much time trying to decipher the data in this snapshot – it can only be understood in the context of many other tables that use numbers to portray intricate aspects of millions of terms.
As a note to specialists, smurfs add an order of precision beyond what is achieved with Wordnet. Wordnet has identification numbers for “synsets”, which are clusters of terms that share a general meaning. The Wordnet 3.1 synset 02958343-n, for example, contains “car”, “auto”, “automobile”, “motorcar”, and “machine”. Other meanings of “car” belong to other synsets, as do other meanings of “auto” and “machine”. It is possible to zero in on a precise spelling/meaning unit, essentially by combining spelling and meaning in a formula (car-02958343-n, more or less), but this becomes extremely inefficient when you start to make complicated calculations across languages. At Kamusi, we maintain the Wordnet synset to show one level of relationship, and to facilitate coordination with the many external projects that use the Wordnet system. However, we are transitioning to the smurf level to more precisely differentiate nuance that is lost within a Wordnet synset such as, for example, “hit”, “strike”, “impinge on”, “run into”, and “collide with”. The goal is not, as some reviewers mistakenly assume, to build a bigger Wordnet, but rather to use Wordnet as a starting point for a more complex, three-dimensional matrix.
If you have an hour, you can watch this invited lecture, “The Particles of Language: “The Dictionary” as elemental data for 7000 languages across time and space“, that I gave at CERN in 2015 that dives further into what I call “molecular lexicography”: https://cds.cern.ch/record/2054123. (The room is less empty than it looks, but most of the audience sat out of camera range in the back rows by the entrance.) There are lots of pretty pictures and no math, I promise.
A monumental difference between Kamusi and GT is that, if Kamusi does not have data for a particular concept, we will tell you that we do not know, and ask for your help in obtaining the missing information. GT, on the other hand, invokes MUSA to always print some sort of output, regardless of whether it has the slightest basis for doing so, and never indicates when their content is certifiably fecal. We do not subscribe to the MUSA “make stuff up” theory of machine translation that is, as documented in this research, Google’s fallback position.
SlowBrew disambiguation3
Services like GT have inculcated the expectation of magic wand translation, which was exposed as a myth in the chapter on qualitative analysis. A system in advanced development at Kamusi Labs introduces a human review phase prior to passing a source document to a translation engine. Instead of undrinkable instant coffee, the results of SlowBrew will satisfy the palate, with the potential (as the underlying data improves) to produce precise vocabulary matches every time. I acknowledge that uptake will involve a change in consumer expectations, which I believe will occur (a) as users experience a vast increase in output quality versus magic wand translation, and (b) users come on board from languages with little or no current engagement with MT. SlowBrew takes advantage of Kamusi’s semantic mappings to prepare a document for translation. In brief, the system analyzes a sentence using available NLP tools for features such as lemmatization and part of speech tagging. The user is then presented a list of senses for each polysemous term. If the text contains “dry”, for example, the user is given a list to choose from:
- dry (not wet)
- dry (boring)
- dry (not sweet)
- dry (not permitting alcohol)
The user selects the sense that applies; future work will float machine estimates of the most likely sense to the top of the stack of concepts on offer, such that a sentence containing 🐄 will elevate « dry (not producing milk) ». If a sense or term is not present, the user is given options to contribute it for review as an addition to the dictionary. Once the user has marked their intended senses, we are no longer wrestling with the word “dry”, but instead with a smurf, a number like k-2346 that is associated with a meaning across languages. Because the meaning is known at this point, no fancy computation is necessary to guess the matching vocabulary based on the happenstance of letter sequences. We have eliminated the problem of choosing from among all possible terms on the target side that match to any possible sense on the source side. In the case of the Absurdities above, the user will have identified the concepts (along with their parts of speech, inherently), so the computer will never be asked to guess at all the lights and bests and worsts and picks – the computer only sees the vocabulary as smurfs. For the machine, the task for the Absurdities is the same as all other SlowBrew translations, creating a seating arrangement (determining the logical syntax patterns) for the smurfs on the target side who are married to the smurfs on the source side across the aisle, and dressing them in appropriate clothing (producing the right inflections).
Future programming will allow users to tag their source documents with even greater refinement. No amount of data or learning will enable statistical or neural predictions of what is meant by “some” in “save some for me”, or “they” in “they were hot” in many situations – the female cheerleaders? the male roosters? the pizzas? – but a manual endophora identification tool is on the task list for SlowBrew. When a model to recognize them as such is in place for a language, users can be prompted to link ambiguous pronouns with the first mention of the thing they refer to, thereby also attaching knowable attributes such as gender or noun class.
Similarly, users can be asked to clarify known problem elements in a language, such as declaring a gender for a subject, or the gender or relative status of the person to whom they wish to communicate. The program will need to adapt to the special ways that source languages mismatch with their targets, for example asking English speakers to clarify who is meant by “you”, or asking Japanese speakers to pinpoint a subject for a verb when none is provided. SlowBrew 2.0 will not introduce complicated new technical challenges, but it will require tailoring in consultation with a lot of different language experts. Some will argue that users will resist taking the time to tag their documents prior to MT, remaining content with systems like GT that arbitrarily make grammatical decisions on their behalf that are guaranteed to be wrong much of the time. I suggest that they will flock to a system where women are female, friends are addressed informally while business associates are addressed with respect, all the words mean what they think they mean, and all the pronouns perform their grammatical duties correctly. If we have already gathered an equivalent term in the target language within our database, it can be passed to the target side for MTyJ translation, and further processed for syntax and morphology if and when a model is developed for that language.
When two or more equivalents exist in the target language, the future goal is for the machine to make predictions and offer options to the user, DeepL style. When a term is not in the system, whereas GT just makes something up (inventing fake words such as, for Swahili, “hapatical” as a translation for “heretical”, or fake mappings such as producing the real Swahili word “tatizo” for the non-existent English “heret”, as shown in Myth 4), in SlowBrew the user is honestly alerted that the data is not yet available, and the term is flagged and placed within the collection workflow.
Party terms4 are a bête noire for MT because they are difficult to identify, and if they are not identified then the MT engine will nonsensically translate them word for word. SlowBrew is geared to identify party terms, in order to correctly translate their underlying meaning. Party terms are lexicalized in Kamusi – that is, when a combination of two or more words has a meaning other than what would be understood by looking at those words in isolation, the expression is turned into its very own dictionary item, given its own definition, and, crucially, associated with its own smurf. Examine these party terms from three languages:
- over the moon (English meaning: filled with joy. Translated word-for-word by GT to Spanish as “sobre la Luna” and to French as “sur la lune”). smurf = k-5538
- tocando el cielo con la punta de los dedos (Spanish meaning: filled with joy. Translated word-for-word by GT as “touching the sky with the tips of your fingers”). smurf = k-3094
- aux anges (French meaning: filled with joy. Translated word-for-word by GT as “to angels”). smurf = k-9471
All three of those party terms mean exactly the same thing, but direct word-for-word translation fails at 100%, with the meaning evaporated in all six possible translation scenarios. Using the Kamusi smurfs, though, neither the moon nor the sky nor angels are part of the translation equation. Instead, our database will match k-5538 = k-3094, and k-9471 = k-5538, and make the high-confidence association that k-3094 = k-9471. When asked to translate from French to Spanish, even if we do not have a human-confirmed link between the two party terms, we can look to the numbers, and voilà, posit that “aux anges” translates as “tocando el cielo con la punta de los dedos”.
SlowBrew identifies party terms in two ways:
- If the expression has already been lexicalized in the Kamusi database, SlowBrew is triggered by the lead word to search for the other party-goers farther in the sentence. The database will have, for example, numerous expressions beginning with “drive”: “drive up the wall”, “drive home the point”, “drive to distraction”, etc. My testing confirms that GT also does such an analysis on the source side in limited cases for English phrasal verbs and other party terms in its database; for example, the vocabulary choice for “pick” will change (with variable success) with the addition of “up” for the phrases “He picked his son and daughter [up] at school” and “He picked his hot new girlfriend [up] at the bar” (rendered in Turkish as “He lifted his enflamed new girlfriend at the bar”), and “drive” will change for “The new product will drive everyone who tries it crazy” but does not change for “The new product will drive everyone who tries it up the wall”. It is not so difficult to spin through dozens or hundreds of identified party terms, and offer the user any candidates that appear in the text, e.g. the sentence “she drove everyone in the room up the wall” would resolve to “she” + “drive-up-the-wall” + “everyone” + “in” + “the” + “room” if the user so agreed. When there are multiple possibilities within a sentence, such as the multiple “up”s in Absurdity 3 above, the user can choose the one that applies.
- If an expression has not already been lexicalized, the SlowBrew interface enables users to mark any individual words in a sentence as members of a party term and submit that term to the dictionary, organically growing the supply of knowledge for cultivation by future users. That GT sometimes uses leading words to identify separated party terms hints that the underlying idea is not so crazy; the Kamusi notion that the terms also can be identified, disambiguated, submitted to the database by users, and associated with confirmed vocabulary in other languages might also not be so far off the wall.
Learning ideas from users5
When users grant permission, their sense tagging can be used to learn the human associations between words and meanings in context – creating, over time, an annotated monolingual corpus that connects directly to confirmed vocabulary across languages. That is, SlowBrew is currently capable of offering the user multiple choices for “drive”, regarding cars, golf balls, bargains, etc. After repeated sightings in phrases like “drive to New Jersey” and “drive to school”, AI analysis of the data could spot that users generally choose the automotive sense for the pattern “drive to [location]”, with an exception for the golf sense if the phrase is “drive to the green”. Such experiential learning is out of realm in the GT process, where the source text is at best fodder for building a context-free corpus. This method of learning benefits from users’ vested interests in generating superior translations for their own needs. Machine learning compares a million pictures, for example, and comes to recognize features that generally suggest “fish” (but could be “dolphin” in murky water). That generalization is then applied to the million-and-first image, so that Google Assistant can confidently tell you whether the purple flowers you photograph are lilacs or wisteria. A system based on SlowBrew tagging will have precise information to determine not only that an item is a fish, but her name is Wanda. With the vocabulary weak points largely solved, MT technologists can focus on the rote processes at which computers excel, such as morphology and syntax – interested collaborators should please get in touch.
The basic procedure is not complex, though lot of complex coding is needed to make it operational. After millions of people have used SlowBrew to instruct the system on their intended meanings, we will have data to see that in a sentence such as “I kept dry during the storm by staying inside”, users chose item k-1112, whereas in a sentence such as “The lecture was so dry that I couldn’t keep my eyes open” the choice was k-2346. Building on the techniques currently used by NMT, we can examine the words that are embedded nearby. Where current MT slides on thin ice to make some sort of predictive calculation about appropriate vocabulary, though, SlowBrew snowshoes on solid ground: “keep dry” and “storm” and “stay inside” were usually tagged by users as k-1112, while “lecture” and “keep [one’s] eyes open” were most often associated with k-2346. Moreover, we will know that the “keep” (remain in the same condition) in the first sentence was k-7718, while the “keep” (force to stay) in the second sentence was k-3625. When it comes time to translate to another language, we can then transmit the smurfs (k-1112 + k-7718) in the first instance and (k-2346 + k-3625) in the second, and the right vocabulary for ambiguous terms will be generated on the target side, no matter whether the desired language is Latvian, Luo, or Laotian.
Crucially, whereas GT vacillates among sense predictions from one target language to the next (e.g., whether the “spring” in her step maps to springtime or a water source might change from Azerbaijani to Uzbek), because SlowBrew is tagged on the source side, the information adheres to the author’s language. There is no need to relearn or recalculate senses depending the target language. We learn for English based on documents written in English, regardless of whether the original translation target is Luxembourgish or Malagasy, and we learn for Luxembourgish based on documents written in Luxembourgish, regardless of whether the translation target is English, Frisian, or Esperanto. This is opposite to the way GT claims to learn from users, who are somehow supposed to be able to identify whether translations are good on the target side. My confirmation of a translation to Kurdish, say, of “the cow escaped from the pen” is utterly useless as future data because random user Martin Benjamin does not know a word of Kurdish, whereas my confirmation that my meaning for “pen” was k-4545 is bankable information. Tagged corpora will accrue over time for each language users translate out of, helping to discover not only word associations but also information about other linguistic features. This hypothetical system remains unfunded, but when a brave sponsor arrives, it will fundamentally alter the landscape of MT.
Hofstadter [zotpressInText item=”{DLK6QG2B}” format=”(%d%)”] writes:
Machine translation has never focused on understanding language. Instead, the field has always tried to “decode”—to get away without worrying about what understanding and meaning are… It’s familiar solely with strings composed of words composed of letters. It’s all about ultrarapid processing of pieces of text, not about thinking or imagining or remembering or understanding… All sorts of statistical facts about the huge databases are embodied in the neural nets, but these statistics merely relate words to other words, not to ideas. There’s no attempt to create internal structures that could be thought of as ideas, images, memories, or experiences. Such mental etherea are still far too elusive to deal with computationally, and so, as a substitute, fast and sophisticated statistical word-clustering algorithms are used. But the results of such techniques are no match for actually having ideas involved as one reads, understands, creates, modifies, and judges a piece of writing.
Where Hofstadter could be wrong, though, is when he says, “Having ever more “big data” won’t bring you any closer to understanding, since understanding involves having ideas, and lack of ideas is the root of all the problems for machine translation today. So I would venture that bigger databases—even vastly bigger ones—won’t turn the trick”. What Kamusi proposes is not just the growth of data for all languages, but a transformation of the type of data collected. Instead of figuring out how to convert words from Language A to Language B, having users clarify their meanings on the source side will in fact attach ideas to the way they are phrased. The machine task, then, is not for computers to figure out what people are saying, but for people to figure out what people are saying, and for computers to retain that normally ephemeral information and reconstitute it when others want to say something similar down the road. Perfect translation will never be possible, but learning the ideas underlying texts from speakers of their own languages, and aligning those ideas with translation terms validated by bilinguals in target languages, has the potential to ratchet the believability of the output to a level not attainable with current automated inferences.
Efficiency6
Processing speed is not my department, but I suggest that our methods could lead to notable improvements for MT
| Picture 52.2: I coined the term “trumplation” sometime in the spring of 2019. Soon thereafter, I developed the sham map in Picture 33 to further illuminate points about fake data. Amazingly, the US Child-abductor-in-Chief personally combined these two threads in September 2019. He made factually false claims that the trajectory of Hurricane Dorian would bring it to Alabama (the state labelled “AL” in the image). When the National Weather Service issued an immediate rebuttal, the criminal mastermind doubled down on his falsehood. Instead of admitting he had been mistaken, he produced the fake map in this image, a possible trajectory issued much earlier in the storm’s journey across the Atlantic, with an extra loop hand drawn with a black Sharpie marker to show the fantasy movement of the storm into Alabama airspace. Life imitates art – and it turns out fake weather forecasts are illegal. Photo Credit: via GIPHY |
| Picture 52.3: In this video, Japanese YouTuber “An Odd World of Mine / ぼくのオッドワールド” discovers trumplation. Watch to see English evolve before your eyes. |
MT involves a lot of processing power, much of which is wasted. This waste occurs in three areas
1. The magic wand. An enormous amount of energy is sunk into recalculating output with every keystroke a user types. GT uses tremendous processing power on trumplations, blasting out guesses for words that have nothing to do with what the user is writing (eg, it will attempt “us”, “use” and “user” while the user is en route to “users”), and guesses part way through unfinished thoughts (eg, translating “user” when the user is en route to “user interface”). Type this sentence that has exactly a hundred characters excluding spaces into GT at a moderate speed to see it in action. Google made 100 calculations for the 100 letters you just typed, of which 99 were of no value to you. (Typing quickly will reduce the number of calculations, but making and correcting typos will increase the number.) Though estimates for the energy burned in the round trip between your device and the MT server farm are unreliable, there actually is a notable ecological cost in trillions of wasted computations. At the very least, energy could be saved by increasing latency, anathema as that might sound to some ears. Greater efficiency would be gained by calculating whole words after a space has been keyed, and still greater by waiting for a punctuation mark. There is not really a point in calculating anything, though, until the user has input their entire text, then either waited a few seconds or proactively pressed a button. Everything prior is showmanship, not service, producing the illusion that the 99 wasted computations build cumulatively toward a highly refined ultimate output. Turning off the magic wand would have no effect on the final result, allowing resources to be focused on actual demand.
2. Calculating vocabulary. For polysemous terms, GT makes estimations about what vocabulary to use in the target language based on associations it finds across corpora. As my research shows across 108 languages in the empirical evaluation , chances of GT choosing the wrong sense are quite high, even for the best languages, and most especially for the preponderance of party terms that have not been lexicalized together. The cost of such errors is either befuddling translations shipped as are, or lengthy time post-editing “a jumble made of [language] ingredients” [zotpressInText item=”{DLK6QG2B}”]. By having users confirm their sense before translation (or, in the future, by directing the computer to known translations when the context is evident), the load of guessing and correcting vocabulary errors can be substantially reduced. The argument here is not the efficiency of the immediate process within the machine, but the overall efficiency of achieving a dependable outcome.
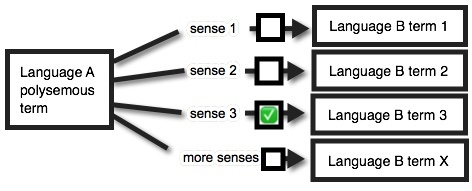
Figure 6: Polysemy resolved by source side disambiguation, where the user selects the specific sense that pertains.
Figure 4 showed that the likelihood of vocabulary failure in MT increases as a function of polysemy, with the top 100 words in English having an average of over 15 senses. Figure 6 shows that interjecting a human eye at the critical juncture will pull the error rate from (x-1)/x toward zero. In Language A to Language C scenarios with English as the pivot, the GT error rate can be expressed as ((EA1+EA2+… EAx-1)/(EA1+EA2+… EAx)) (with caveats that not all senses have equal weight, and multiple senses might be translated with a single expression), while in Kamusi that little green checkbox in Figure 6 leads directly to the concept set that houses the confirmed semantic link between terms A and C. Most errors that arise from computational inference are thereby eliminated. All else being equal, if each of 3 senses in Language A map to English terms that also have 3 senses apiece, GT will have an error rate in Language C of 89%, and if there are 15 senses per term, with a 1/225 chance that the ball falls through the pinball machine into the right hole, the error rate will climb to 99.55%. If we assume (without hard numbers7) that users always select the correct sense using SlowBrew, then, because terms are semantically aligned across languages, the error rate will approach zero.8
3. Multilingual simultaneous translation. Currently, when one document is translated into several languages, translators for each language need to make independent judgements about what was intended on the source side. The disambiguation that occurs within SlowBrew can be performed once, and then applied to any number of languages. In principle, a newspaper could pre-translate its articles once, and publish a marked up version that could be siphoned through an MT membrane for any language. Professional post-editing would obviously be preferable, but the clarification of a knowledgeable reader of the source language would eliminate a significant proportion of errors and provide the base vocabulary needed for at least MTyJ translation. A single click of the green checkbox in Figure 6 leads to the correct vocabulary not only in Language B, but also in languages C, D, and onward. The more languages for which the translation is needed, the greater the economy of scale. This is especially beneficial when the source language is not English, and human translators and machine models are rare among the desired pairs.
4. Source-side rules. In my analysis, it is clear that GT conducts some amount of rule-based NLP on the source side prior to passing text to SMT or NMT. Going from English, GT recognizes features such as part of speech and tense, and tends to map those features identically to sample target languages. The deficiency here is that high-quality NLP is restricted to top tier languages. Within GT, analysis of languages like Swahili is execrable. Yet, NLP is just as important to getting it right for non-lucrative languages as it is for those that have benefited from substantial investment. For example, one would not create a table with every possible form (around 18,576,000 per9) for every known Swahili verb except “to be”, “to have”, and “to rain”, because one would need to store and access billions of terms, many with 10 characters or more, and all their mappings. Instead, I have written a set of a few hundred rules that can parse any Swahili verb into its component parts, isolating the concept, the tense, the subject, the objects, whether it is positive or negative, the noun class that affects other aspects of the sentence, and extended constructions such as passivity and a grammatical question mark. Kinyarwanda, which has extra features and more noun classes, has nearly 900,000,000 forms per verb. Encoded rules reduce the storage and search requirements from trillions to thousands of forms, while increasing accuracy by pinpointing grammatical elements that can be reconstructed across translation languages. Bantu languages with a similar agglutinative structure to Swahili and Kinyarwanda constitute more than 5% of the world’s total, so this one example among many of untreated rules is non-trivial. A specialist in translation technology for under-resourced languages urged that I emphasize the positive advantages rules offer over NMT, which he also notes cannot possibly be engaged for 99% of languages, writing in his review of this article, “What we need is a lexicon and a grammar of the language. No written text [corpus] is necessarily needed, but helpful. Rule-based approaches offer alternatives, which work on any language. One should start to use brains again.” The problem here is financial, not technical, because the work is straightforward but needs the time of experts who would expect compensation for their efforts. With just weeks of work per language to delimit and encode the essential rules, any language can have an efficient model for NLP on the source side (Ranta 2011). Does any funder choose to develop the rules necessary for NLP for languages spoken by people that, to date, have not been considered important?
Learning terms from users10
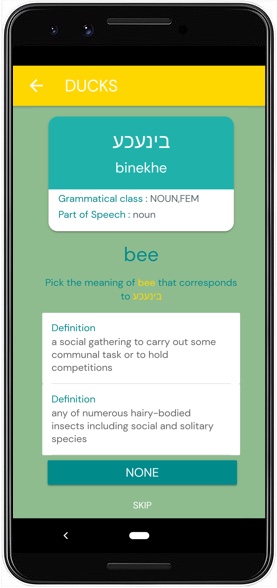
The primordial element needed to launch MT for a language is the set of terms in that language, and how those terms map to other languages. While this article is not the place to discuss the details (Yakutsk was a better venue), it is important to mention that 2019 marks the launch of systems within Kamusi to intake data from users for any of the roughly 7000 languages identified with ISO 639-3 code designations. Users contribute equivalent expressions for their language from concepts associated with specific English definitions, from Wordnet, Wiktionary, and a variety of other sources. The relationships between words are encoded numerically; we prompt the user with a linguistic representation of the term, e.g. dry (not wet) or dry (not boring), but underneath we are asking them for equivalents for k-1112 or k-2346, and converting their response for each spelling/meaning unit in Piedmontese or Potawatomi to its own unique smurf. Answers are validated through a consensus model. Each validated term becomes part of a Data Unified Concept Knowledge Set (DUCKS) that is linked as numerical data across languages, so a term that is contributed in reference to English is automatically aligned to the expression of that same idea in all other languages.
At the time of release of Teach You Backwards, Kamusi has five active tools, with more under development, for acquiring and validating terms and additional lexical data from the public for any of the roughly 7000 languages with ISO 639-3 codes [if you are reading this bracketed text, the tools are available on Android and iPhone, but have not yet been implemented on the Web]:
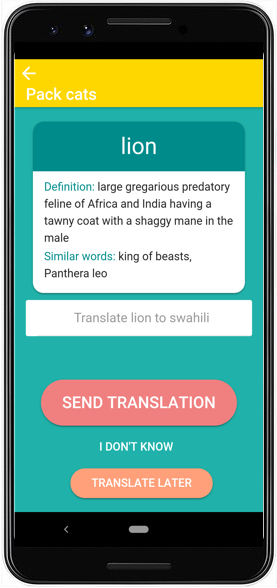
- GOLDbox (Pictures 53.3 and 53.4). When a dictionary user encounters a concept that we have in the language they are searching from but is missing in the language they are searching to, they can suggest an equivalent for the target language. Similarly, they can suggest own-language definitions for any term that does not yet have one [though our validation system for definitions has not yet been finalized if you are reading this text].
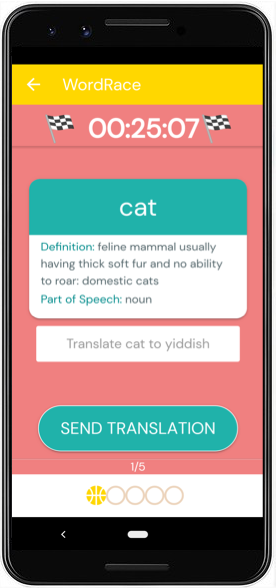
- WordRace (Picture 53.5). Game players are presented with an English term and its definition, and asked to type the best equivalent in their language. A stopwatch shows them their elapsed time. After the same term has been proposed by a number of players, those players are awarded points based on who produced the answer in the least time.
- IdeaPacks (Pictures 53.7, 53.8, and 53.9). Users select sets of words that are organized based on topic, such as body parts, restaurant menus, or soccer terms. They provide equivalents for the terms they know, and are awarded points when their answers achieve consensus.
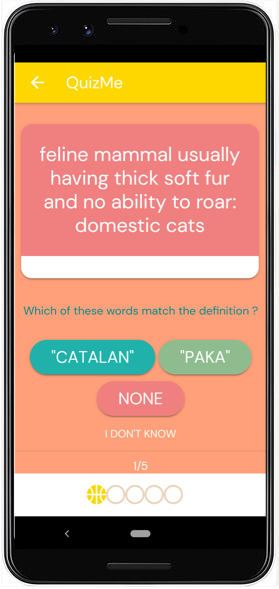
- QuizMe (Picture 53.6). In this game, we present a term that has been proposed through one of the intake systems, alongside another word chosen randomly from the target language, and the English definition. Players are asked which term, if any, matches the definition they see. In this way, we can speed through validation, reaching consensus quickly even for terms that have only been suggested once. This game is especially important for validating synonyms and rejecting bad data. For example, we might see “lunettes” many times in WordRace as the French equivalent for “sunglasses”, but only see “jumelles” once. Since “jumelles” is a valid but less frequent term for the concept, QuizMe lets us put it before enough French eyes that we can confirm that it is also a legitimate expression. On the other hand, if someone were to propose “pamplemousse” as a French equivalent, QuizMe players will quickly vote it off the island, and people seen to be playing in bad faith are blocked and their contributions removed.
- DUCKS (Picture 53.10): An additional system is designed to extract lexical data from diverse datasets for thousands of languages, especially from the 10,000 sources digitized at PanLex, and engages users in matching those items to Kamusi DUCKS (presented in [zotpressInText item=”{CAJAM6YB}”], with the slides and audio below). In short, an available dataset might say that “ɓeeɓinde” in Fula translates as “dry” in English. Instead of guessing, we show players the possible senses of “dry”, and people get points when they choose the same answer as other speakers of their language. When consensus is achieved, “ɓeeɓinde” with that meaning receives its own smurf, and Fula enters the set of languages that can mutually translate the given sense of “dry”.



Asking people for the equivalents of English terms does not solve the problem of capturing terms that are indigenous to languages other than English, but should get us a substantial way toward developing base vocabularies for languages without adequate corpora, and augmenting the vocabularies for languages that already have substantial data. Aligning existing external datasets with DUCKS can uncover some indigenous terms, such as “muukumaaka” in the Fula dictionary that means “chewing or eating in an exaggerated manner”. The lack of a potential English match in Kamusi flags it for consideration as a new concept for the universal knowledge set, with an explanatory English equivalent like “dramatic chewing” (which my inner anthropologist guesses is performed to show appreciation for good food, like slurping noodles in Japan) produced so that non-Fula speakers can have an angle into the concept. Otherwise, unfortunately, for the many languages without corpora to mine, indigenous concepts can only become evident to the system if a speaker of the language notices the omission and takes the time to submit it.
Importantly, no user contribution is considered the last word – the option always exists to add additional senses for an expression, or to edit faulty information, and terms are shown with source information to establish provenance, and caveats to alert users that items in their results box are less omniscient than they appear. Each piece of knowledge that we can learn from users is banked, made available for use in applications such as SlowBrew, and often used as the kernel to gather more information such as inflections and own-language definitions.
An additional aspect of linguistic expression that can be treated through knowledge capture is one that Google embraces for English, but eschews for translation. Each language has an inventory of stock phrases, things that are said repeatedly in the same way. Similar to party terms, stock phrases can be translated from the outset by people who understand the source context and the nuance necessary to convey the essence in the target language, and those stock translations can be used (with grammatical modifications provided by NLP) when a user inputs the phrase. Google has an entire bureau that identifies stock phrases for Google Assistant, their competitor to Amazon’s Alexa, that is intended to provide an intelligent response to any question or command you might voice. Take an example from their own homepage: when a user says, “Hey Google, dim the bedroom lights”, their machines do not perform deep processing to figure out the components of the sentence and how they relate to each other and how that relates to the required response. Rather, some person has isolated the phrase and specified a chain of events that the phrase should activate – in this case, issuing a command to the user’s “smart home” system.
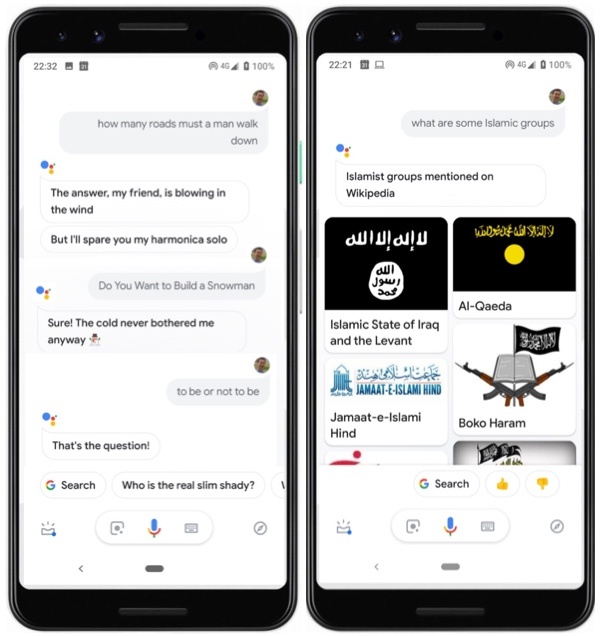
Picture 53.11: On the left, examples of stock phrases for which Google Assistant is manually trained with responses. On the right, an example of a fiasco when Google Assistant seeks a response algorithmically rather than based on human review.
In Picture 53.11, we can see a number of cases where the Assistant team had some fun writing their canned responses. They obviously identified popular queries: “How many roads must a man walk down” from the Bob Dylan song “Blowin’ in the Wind”, “Do you want to build a snowman” from an obscure arthouse movie called Frozen, “To be or not to be” from Hamlet. On the other hand, the right side of Picture 53.11 shows that queries that have not been reviewed by people are sent to the machine for some sort of relevance prediction, with results that can miss the mark catastrophically. If “dim the bedroom lights” and “to be or not to be” can be identified as stock phrases for people to assign actions to, they can also be identified as candidates for stock translations. A system to acquire validated stock translations from users will be introduced in the next generation of Kamusi Here, beginning with phrases to localize the app’s own user experience. The video below shows a number of instances where stock phrases are butchered by GT, and where enthusiastic members of the public could be enticed to provide well-considered stock translations:
To the greatest extent possible, MT should not be based on intuition, because no amount of data is sufficient to verify that intuition. MT should be based as much as possible on facts. Messy dictionary data to underlie translation that is captured from existing digital sources should be verified by people, not groped at by algorithms. Language communities should have the tools to grow their own data, rather than wait for the day when a corporation will take interest in their needs. MT should declare when it does not have the data to perform a translation, instead of supplying fake filler text. Humans should have the option to verify the senses they have in mind for the texts they produce on the source side, rather than have machines make haphazard guesses. Performance should be judged by the way that MT transmits meaning across languages, not the speed with which it places words on the screen, which is performance art. Computers should learn meanings from the declarations of a language’s speakers, rather than word associations based on shallow inferences (ironically labelled “deep learning”) across corpora. Currently, the ability of the user to select English to 67 of the languages in the GT system fails to produce a transmission of meaning more than half the time, and my tests indicate that only about 1% of 5151 non-English pairs will yield MTyJ scores of 50 or greater. We language technologists can do better, and we at Kamusi Labs are developing the systems described above with that goal in mind.
Picture 54: Kamusi users can contribute for any language with an ISO 639-3 code, by selecting any local language name compiled from all 50,642 spellings and scripts collected by CLDR
References
Items cited on this page are listed below. You can also view a complete list of references cited in Teach You Backwards, compiled using Zotero, on the Bibliography, Acronyms, and Technical Terms page. [zotpressInTextBib style=”apa” sortby=”author” order=”asc”]
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- We are finalizing a work plan with the technology ministry of one African country, to be named when the contract is signed, that will include such a resource for its three main languages. I hope this will serve as a model for how to divide 7000 languages into more manageable national chunks.
- link here: http://kamu.si/tyb-semantics
- link here: http://kamu.si/tyb-slowbrew
- link here: http://kamu.si/tyb-party-terms-disruption
- link here: http://kamu.si/tyb-learning-ideas
- link here: http://kamu.si/tyb-efficiency
- I have not yet done rigorous mathematical testing of Kamusi accuracy. In my experience, Language A to Language C translations rarely miss (unless one of the translations to English was wrongly interpreted by a language’s Wordnet team, which our processes are designed to find and correct over time). A fun parlor game is having two people who speak different non-English languages that are in both Kamusi and GT fire up the apps for the two services, and then try translating words or party terms from one to the other. For concepts that have already made it into our dataset for both languages, but are not the most frequent sense for the polysemous term, Kamusi always wins; for example, the concept of tree trunk, which is 干 (Mandarin) versus κορμός (Greek) – see our head-to-head comparison testing. When we have funding resources, we will put our claims through empirical testing. Until then, you may view my claims of >95% accuracy as unsubstantiated braggadocio.
- Our system does not answer the question about how to select among synonyms on the target side. For example, the concept of “glasses” in English has three translations in Spanish, “gafas”, “lentes”, or “anteojos”, with different regional preferences. The Kamusi system gives a precise pathway from eyeglasses on the source side, rather than drinking glasses, but does not yet have an elegant solution to choosing among the three synonyms on the target that is better than anyone else’s. The pragmatic temporary solution will be to present all of the synonyms as a bracketed set. If support is available down the road, we will build a system for recipients to open translations directly within SlowBrew, so target-side users can mark their preferred vocabulary results and those results can be logged for future machine predictions.
- Verbs can have grammatical markers in as many as six slots. For cases where a relative pronoun marker can appear internally, the possibilities are combinations of 50 subject prefixes x 16 object infixes x 11 relative infixes x 27 tense markers x 20 extensions including plural command variations x 3 suffixes = 14,256,000 forms. Where the relative marker appears at the end of the verb, the possibilities are 50 subject prefixes x 16 object infixes x 27 tense markers x 20 extensions including plural command variations x 10 suffixes = 4,320,000 forms. This calculation does not include static, contactive, and inceptive suffixes that do not apply to all verbs, but will increase the total possibilities. On the other hand, I may have overlooked a few scenarios where the occurrence of X in one position obviates the occurrence of Y in another, which could slightly overstate the possibilities. Also, some things are possible linguistically but not in practice, e.g. a person cannot be split and a board cannot cry, so the associated forms cannot be constructed in people’s mental models. I welcome any Swahili linguist to help polish this calculation.
- link here: http://kamu.si/tyb-learning-terms