The Astounding Mathematics of Machine Translation

The finite limits to how well GT can ever translate

Picture 47: Attaining victory over a human in the constrained space of a Go board is considered one of the greatest feats achieved by computer science. A similar board for languages would have 7000 lines, cut along the diagonal, forming 25 million intersections for every concept, assuming one expression per concept per language. Image credit: Google Deep Mind
To make use of the ongoing efforts the author directs to build precision dictionary and translation tools among myriad languages, and to play games that help grow the data for your language, please visit the KamusiGOLD (Global Online Living Dictionary) website and download the free and ad-free KamusiHere! mobile app for ios (http://kamu.si/ios-here) and Android (http://kamu.si/android-here). How much did you learn from Teach You Backwards? Your appreciation is appreciated!:
The proudest moment that AI researchers have ever experienced was the defeat of a human master in the game of Go, shown in the 2017 documentary film AlphaGo.1 The board has 19 vertical lines and 19 horizontal lines, one color of stone for each player, and one thing to do per turn: put a stone on one of the intersections (see Picture 47). The first play has 361 options. As stones are played, the number of possible plays per turn usually decreases, although the removal of captured stones from the board will increase the available plays. Two rules, one against self capture and one against recursive capture, further reduce the possibilities for play later in the game. In short, the maximum number of choices per move is 361, and that number is much less later in the game. Nevertheless, there are more possible Go games than all the atoms in the known universe.2 Crunching the numbers to determine where to play for the best outcome of any given move is beyond the mathematical power of any person or machine – intuition of some sort is essential. Beating a human with AI was an incredible computational achievement. Yet Go is simple in comparison to language.
Without diminishing the magnitude of the accomplishment, language is much more complicated. There are no limits to the number of thoughts a person might try to express, and any number of ways to express any given thought. Looking back a few sentences, instead of leading with “Crunching the numbers”, I could have said “To crunch the numbers”, or “Number crunching”, or “Performing calculations”, or “Calculations”, or “Raw computation”, or many other linguistic paths to the same sentiment. I could have approached the sentence from a different direction: “It is beyond the mathematical power…”, or “No person or machine could crunch…”. We could certainly list 361 different fully comprehensible ways to express the content of that one sentence in English (but let’s not). Native speakers could equally find 361 formulations of the ideas in the sentence in Hawaiian, 361 in Gurani, 361 in Kinyindu. Scrolling through the most recent 361 tweets on Twitter with “crunch the numbers” barely gets you back to last weekend.
Picture 47.1: A walrus doing crunches via GIPHY. GT translates "crunch the numbers" to Dutch as "crunch de cijfers", deploying a term used in Dutch for abdominal exercises. Either GT found that equivalence in some parallel data or, alternatively, put forward "crunch" as a lei lie that happens to correspond to a Dutch anglicism of a concept unrelated to number crunching.
And yet, when GT is faced with three words used by every engineer in Mountain View, “crunch the numbers”, it variously produces equivalents in French, Italian, Swahili, Polish, Dutch, and German for bite, crack, hit, break, abdominal exercise, or grind numbers, with no sense of performing mathematical operations. (I did not try this phrase on all 102 GT languages, but zero for six indicates a clear pattern.) We have reduced the problem from 361 possibilities in 7000 languages to seek just one concept equivalent in 6 languages, and ended up “biting” digits. Translation tasks are computationally closer to forecasting the weather a month in advance than playing a static game of Go. This section looks at the underlying factors that make translation so difficult, and why current approaches to MT, as represented by Google Translate, face insurmountably finite limits. I introduce ways to surmount those limits in the next chapter about forthcoming disruptions to the translation industry.
The volume of untreated basic concepts3
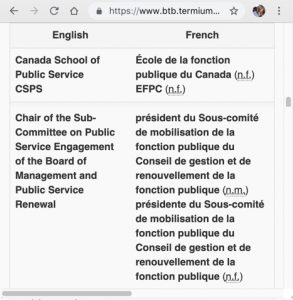
Picture 47.2. Three official Canadian translations of named entities. The first two items refer to the same entity by full name and acronym respectively in both languages, while the third English term was translated to French in both masculine and feminine forms. The Translation Bureau of Canada employs 1200 language professionals, mostly between English and French, creating the most thorough dataset for terminology for any language pair. Unfortunately, though the data is public, it is not available in a format that can be readily incorporated in MT or other NLP applications.
Let’s review some numbers. In a world where each word was represented by a single concept in one language, and each concept was represented by a unique word, and each language had an expression for that concept, translation would start with a simple mechanical task of matching vocabulary. That is, every language is going to have a word for 👄, and if that concept is represented by a single word such as “mouth”, and the word “mouth” only represents 👄 and not any other idea like “the end of a river”, then we just need the data and we’re good to go. As it is, we only have parallel data in digital form for some thousands of concepts in some dozens of languages, so our initial condition falls about 6950 terms short of the 7000 needed to translate the single concept of 👄 around the world, and 6950 terms short for each of the other thousands of concepts that have been aligned through the Global WordNet4 – hold this thought, because we will return to data shortfalls in the discussion of disruptive approaches to translation. The Princeton WordNet for English has almost 118,000 synsets (clusters of expressions with similar semantic values, like “joint”, “reefer”, and “spliff”), while Wiktionary has more than 948,000 definitions,5 so immediately we can identify many hundreds of thousands of concepts that have not been aligned multilingually in any useful way,6 with hundreds of thousands of unique expressions in English alone.
Looking at specialized vocabularies, such as scientific terminology, brings the number of concepts into the millions. Adding in “named entities” such as the names of people, places, or organizations (see Picture 47.2) that might appear in any newspaper article adds millions more base concepts in English alone. GT has some named entities in its database that it handles correctly, such as properly maintaining “Grand Rapids”, a city in Michigan, as “Grand Rapids” across many (but not all) languages – for example, transliterating it to Japanese as グランドラピッズ (Gurandorapizzu) – but there are many millions of place names that are outside of its catalogue. Sometimes GT handle uncatalogued names correctly through the clues of capitalization, and sometimes as a by-product of MUSA. Picture 60 shows a real-world example where the failure of MT to recognize a named entity, a town in Germany, could have resulted in serious loss. Many concepts can have multiple forms, such as the 112 English versions of the name of Libya’s dearly departed ruler that expand to 413 forms in a multilingual news corpus,7 or the conjugated forms of verbs (such as see, sees, seen, saw, and seeing).

Picture 47.3: My 9-year-old described a bottle like the one pictured above as “undecrushable”, using the rules of agglutination to compose a unique but valid English word. In some languages, such on-the-fly compositions are intrinsic to almost every sentence. (Undecrushable does not occur in Google search results as of this posting on 17 Sept. 2019.)
It would not be unreasonable to estimate that English has 10,000,000 discrete expressions that occur somewhere in print. German is more complicated, because it compounds nouns together such that “Autobahnmarkierungsentfernungskomitee” (a committee that is responsible for removing the road marks on German highways), or any other amalgamated concept, becomes a single word. Many other languages, particularly the 400 Bantu languages spread across central and southern Africa, have even more complicated agglutination patterns that can result in hundreds of millions of complete sentences smooshed inside a single word. In our starting point of a one-to-one-to-7000 world, the number of unique human expressions is immense beyond calculation.
Lexical gaps – concepts without direct translations8
Subtraction adds complication to translation. Not all languages have expressions for all concepts, but ways of expressing those concepts must still be produced when translating from the languages where the ideas arise. For example, most African languages do not have a term for “winter” because most of the continent does not experience that season as such, but any African might have occasion to read a newspaper article about winter occurring elsewhere. GT proposes “baridi” (cold) from English to Swahili; ripped from the headlines, the first Google News result for “winter” at the moment of writing is “Winter storm could make trip home from Thanksgiving hazardous for KC-area travelers” [zotpressInText item=”{NAL9K9WE}”], translated to Swahili as “Dhoruba ya baridi inaweza kufanya safari nyumbani kutoka kwa Hatari ya Shukrani kwa wasafiri wa eneo la KC”, with “dhoruba ya baridi”, literally “storm of cold” leading the incomprehensible word salad (trust me on this) that follows. Each language has its own trove of unique concepts, so “lexical gaps” occur throughout the translation matrix; e.g., the “kanga” printed fabric that a Swahili-speaking woman would wear to a wedding becomes a “knife” or a “cord” when GT is asked to provide a term in English or Spanish, and a “place” in French. Fewer words, or one-to-zero relationships, mean more work for MT. Either previous translation attempts to mind the gaps must be found from parallel corpora, or knowledgeable bilingual people must be asked to provide explanatory terms that can be called upon in the target language whenever the unfamiliar concept arises in the source text [zotpressInText item=”{ZD8I6QTL}”]. For languages that have parallel corpora, the chances of finding a consistent go-to translation are fleeting, as seen in Picture 24. When the corpora fail for GT, the use a technique called MUSA to simply make stuff up: “baridi” as “winter” becomes a “fact” because, if they used NMT as stated, their processor found a word that appears frequently in the same vector space and, hey, who is going to tell Google they’re wrong? For the supermajority of language pairs between which parallel corpora will never exist, even fake data is not an option. The Kamusi solution is to collect and validate such data directly from linguistic communities.
Semantic drift – concepts that do not fully correspond9
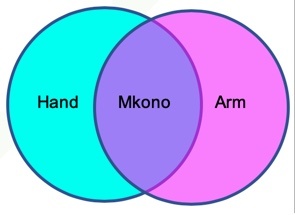
Fractions, known as “semantic drift”, also muddy the math. In many Bantu languages, 💪🏻 is a single upper limb, e.g. “mkono” in Swahili. However, in most European languages, 💪🏻 is two different things, a hand and an arm (unless you lose your arm, in which case the hand goes with it). In GT, “Mkono wake uliumwa karibu na bega” (literally “[His or her] upper limb hurt near the shoulder”; a human translator would intuit gender and “arm” from context) is converted to “His hand was bent around the shoulder” (BLEU = 14.54) – GT provides a guess in the guise of a fact, despite the clue “shoulder” that was intended to keep the translation from drifting over a waterfall. 🐏 (sheep) and 🐐 (goat) are different animals in both English and Swahili, but breeds of one animal 羊 in Chinese, leading to translation confusion during the Year of the 羊 [zotpressInText item=”{IXILJZTP}”]. GT renders 羊 as “sheep” in English, and consequently the equivalents of that term in Swahili, French, Romanian, and down the line. With about a billion domesticated goats herded around the planet, a mistranslation could have substantial economic ramifications (no pun regarding male sheep intended) for the international meat trade. Fractional overlaps between concepts, or one-to-(less-than-one), exist between all language pairs, for innumerable concepts, in unpredictable ways. As with lexical gaps, I propose that codification of human semantic knowledge is the route toward true facts that can be used in MT.
Polysemy – words with multiple meanings10
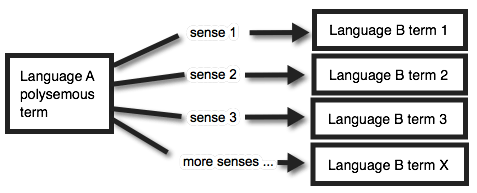
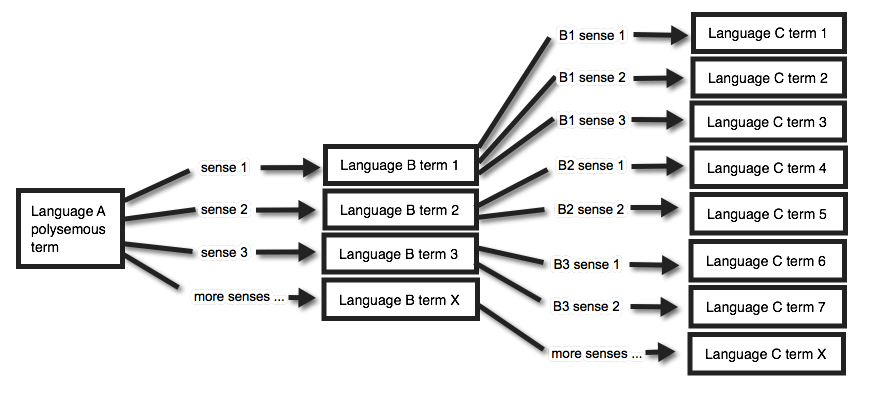
Multiplication begins with “polysemy”, the ability of one expression to have more than one meaning. Wiktionary has 38 senses for “out”, the forty-third most common English word, for example, and wordreference.com lists 42 primary senses and 1637 concepts composed with the word, from “act out” to “zoom out”. Daffodils that are “out” in English are “en fleur” in French, while an “out” homosexual is “ouvertemente gay”, expired time that is “out” is “terminé” or “fini”, a film that is “out” in the theaters is “sorti”, etc.11 Figure 4 shows how translation possibilities multiply, though the math gets messy if some senses happen to share an expression when translated, such as a worker being “out” for the day and a tennis ball being “out” of bounds both having equivalents in Spanish as “fuera”. Picture 48 shows an instance from Google where “shingle” is defined with 4 noun senses and 2 verb senses, questionably translated but not aligned to French with 3 noun terms and 3 verb terms, with items highlighted in green showing a term that is polysemous in French and the items in red showing an English sense with multiple French translations.
Were each polysemous sense of an expression in Language A to match to one and only one unique expression in Language B, then “out” in English would have on the order of 40 x 7000 translations (that is, 280,000, more than a quarter million translations for one three-letter English word) before considering 1600 x 7000 (=11,200,000) composed forms. In the absence of further information to influence statistical or neural choices, discounting party terms, and assuming that translation data was available for all senses, MT would have a 1/40 chance of matching “out” to the correct term in Language B. You can try prompting GT with senses that NMT should pick out due to obvious collocations, and you might get the right result – in French, for example, “The film came out in October” correctly uses “sorti”, but “The homosexual came out” and “The sun came out” also both erroneously use “sorti”. My tests of GT involved 20 expressions in which the sense of “out” should be evident from word embeddings or other context, in all of the 107 languages they translate toward from English.
An additional round of multiplication occurs when “translation” steps through a pivot language, as shown in Figure 5. GT passes through English in almost all of the 5151 language pairs they claim to support. All else being equal, an expression that has three senses in Language A with unique translations to English, with each of those 3 English words also being polysemous with three senses that each have unique translations to Language C, would result in a 1/9 chance of being translated correctly from A to C. For example, “galets” in French can correspond to the first sense of “shingle” in Picture 48 (pebbles on a beach), or refer to small objects in the shape of “discs” (round rice crackers are “galettes de riz“), or a car part called a “tensioner”, but, following a different thread through polysemous “shingle” in English, GT erroneously produces a term for “roofing tile” from French to German, Polish, Portuguese, and many more.
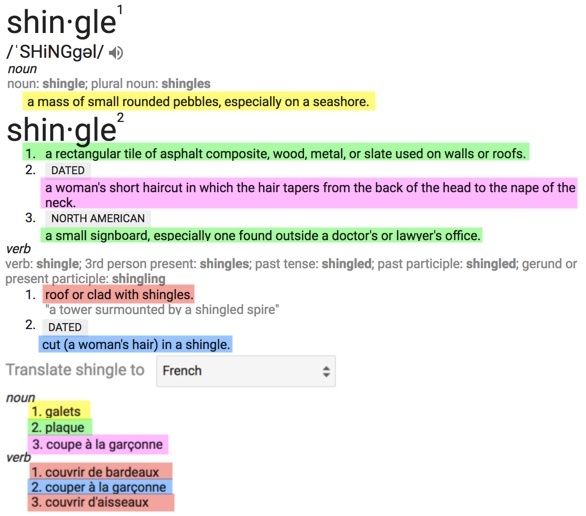
Picture 48: Google dictionary and French translations for “shingle”. Matching color overlay shows correspondences between English senses and proposed French terms.
According to my count, the top 100 words in the two billion word Oxford English Corpus, which make up about half of all written English,12 average more than 15 senses a piece in Wiktionary. One-to-many multiplication occurs much more often than not in direct translation, and two-step translations are fraught with one-to-many-to-(many-more) relationships. When faced with polysemy, GT makes a choice, with success rates shown in my empirical tests, and, despite failing 50% or more of the time in 2/3 of languages, presents the result as computed truth.
{kind=link}
Mandarin Chinese, the world’s most spoken language, has a special wrinkle: tones. With four main tones and one neutral one, the same word can be pronounced in five different ways, with five different meanings. The complexity of Chinese to English translation, among the highest pairs in demand, thus takes polysemy and multiplies by five. There is no telling which of these 35 Chinese translation fails might have come from GT, but polysemy is clearly to blame in some cases, so you should beware of missing foot, as well as poisonous and evil rubbish. And please don’t be edible.
Party terms (or multiword expressions) – words that play together13
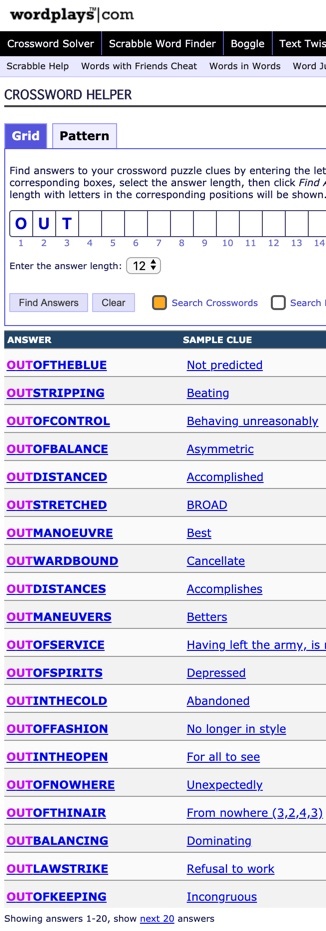
Picture 48.1: English party terms beginning with “out” and containing 9 additional letters, collected from millions of crossword clues. The wordplays.com corpus can be used to identify almost all party terms up to 21 characters beginning with, ending with, or containing a key word.
The math becomes exponentially more complicated by the preponderance of “party terms” (a.k.a “multiword expressions” or “MWEs”)14 throughout human languages. Party terms, which often do not appear in dictionaries, are expressions of two or more words that take on meanings when they dance together that cannot be derived from the sum of their parts. “Chicken sandwich” is not a party term because a person, and maybe MT, can easily discern what it is by looking at the definitions of “chicken” and “sandwich” independently. “Afternoon sandwich” is not even a thing, although the two words frequently appear together in the corpus. “Shit sandwich” and the named entity “South Sandwich Islands”, however, are party terms, because you could never figure them out by inspecting their component parts. Party terms can have two words, e.g. “run out”, or several, e.g. “run out the clock”. English exacerbates the problem with thousands of phrasal verbs, e.g. these distinct actions involving r-u-n that have nothing to do with moving forward quickly by foot: run about, run across, run after, run against, run along, run around, run away, run back, run by, run down, run for, run into, run low, run off, run on, run out of, run over, run past, run through, run up, run with. Much technical terminology consists of party terms, such as an airplane’s “service ceiling”. Idiomatic expressions, such as “feel under the weather”, are inherently party terms (and even technical terms can be idiomatic, such as “pie chart” or “server farm”). MT must evaluate whether to translate “service” and “ceiling” separately, or identify the words as a unit that should be treated together – a task that multiplies with each additional word in an expression, such as five characters in Chinese, 南书房行走, that refer to an intellectual assistant to emperors of the Qing Dynasty (akin to the contemporary party term “White House policy advisor”), invented by GT meaninglessly using MUSA as “South study walking” [zotpressInText item=”{DLK6QG2B}”].15
Party terms can also be polysemous, e.g. you can “run out” of milk and then “run out” to the store on your bike to get more. Furthermore, a concept can be expressed as a party term in one language but a single word in another language, such as “pie chart” in English being the differently idiomatic “camembert” in French (several-to-one or one-to-several without polysemy, several-to-many if the source term is polysemous), or using party terms in both languages (several-to-several), such as an Italian human translator’s rendition of “when pigs fly” as “il 31 febbraio” (the 31st of February, i.e. never).
Detecting party terms within each language’s uniquely nebulous corpus is a major ongoing endeavor among NLP researchers [zotpressInText item=”{A779CZZB}”]. Automated corpus scraping can deliver candidate terms for human eyeballs to evaluate. Picture 48.1 shows that a manageable amount of labor could identify nearly every English party term containing “out”, ascribe definitions to each sense of those terms, and offer the terms to bilinguals to provide certifiable translation equivalents in other languages. Computers can help discover party terms, but only human-centric natural intelligence methods , which GT nods toward but bungles badly, can actually seal the deal – AI cannot tell a categorical difference between an afternoon sandwich and a shit sandwich, much less determine a translation for the latter term in even a single language. Such mining techniques are outright impossible for the 6900 languages without corpora.

Picture 49: A literal interpretation of the party term “drive up the wall”. Credit
The mathematics of party terms causes stack overflow errors when the components move away from each other on the dance floor, what computer scientists call “discontiguity” or “discontinuity” and linguists call “separability”. A party term such as “drive up the wall” actually requires a split: she drives [someone] up the wall. It is difficult for MT to connect “drive” with “up the wall” if the item in the middle is “me”, and doubly difficult if the item is two words, e.g. “my sister” or “many people”, and the difficulty gets greater as the distance expands; “she drove [almost everyone she worked closely with in her last really good job at the old aircraft assembly factory up the block by the river] up the wall” has a separation of 24 words. Traditional MT does not even attempt to bridge distances of more than a chosen “discontinuity parameter” of a few words [zotpressInText item=”{DN4GV6QI}”], with precision deteriorating drastically beyond a separation of three words [zotpressInText item=”{XRCS554D}”]. NMT, which looks for words that float around each other, is theoretically better geared toward discovering separated party terms by compressing all the necessary information in a source sentence into a fixed length vector [zotpressInText item=”{I8NY6UEI}”], though Klyueva et al [zotpressInText item=”{ID983Q8M}” format=”(%d%)”] report that a separation of one unit resulted in failure for Romanian, and Gharbieh et al [zotpressInText item=”{3AQP9H7R}” format=”(%d%)”] does not report success in bridging gaps. To wit, “she drove me up the wall” in GT brings translations pertaining to motoring on vertical surfaces, as depicted in Picture 49. Finding sensible translations for party terms separated over a short distance, sev-(three-at-most)-veral-to-something, is a hard nut that MT has mostly not learned to crack, while dividing a party term by longer distances, sev-(four-words-or-more)-veral- to-something has the same general effect as dividing by zero. For some party terms that GT has identified as such in English, it takes the same approach as Kamusi proposes and uses the first word as a trigger to look downstream in a sentence for the term’s resolution before driving toward a translation. However, in the preponderance of cases, GT takes party terms literally. A piece of cake is a portion of baked confectionery, no matter the context.
Morphology – words that shift shape16
Inflections have repercussions for MT that go well beyond the proliferation of word forms. A translation program must recognize that “sees”, “saw”, “seen”, and “seeing” could all be tied to the canonical form “see”. A sentence such as “I see your point” already requires determining that “see” refers to understanding instead of vision. With inflections, the same determination must be made for “I saw your point”, “She sees your point”, “Your point was seen by all”, and “I’m not seeing your point”. English is a relative piece of cake in this regard. Arabic nouns can have six inflected forms, French verbs hover around 96, and while Bantu adjectives have a polite dozen forms or so, their verbs can reach close to a billion. Inflected forms, many of which are unseen or too sparse for inferences in the training data on either or both sides, must be decomposed from the source language and composed afresh in any target language, resulting in a “combinatorial explosion” [zotpressInText item=”{5248838:5XT8H2VG}”].
Inferring meaning for each different inflected form would compound the difficulty of the problem – that is, discovering that “see” can mean “understand”, and then discovering that “saw” can mean “understand”, and then discovering the same fact nugget for “seen” and “seeing”. It is simpler to discover the morphological variations that map to “see,” and then discover the meanings that map to that lemma, and use that combination to find equivalent terms and their matching inflections in the target language. In fact, this appears to be the approach that GT takes. Changing the subject, tense and object in simple sentences does not usually change the surrounding vocabulary. Though not tested exhaustively, sentences like “I see the film” and “She saw the film” conjugated correctly in sample languages (although selected the wrong “see” in all cases), indicating that GT is applying linguistic rules rather than brute force searches of the corpus.
In some cases, inflected forms can add to the polysemy challenge: consider “I saw the wood”, which can involve present tense carpentry or past tense vision, or “seeing” as a noun (“Travel is more than the seeing of sights”) or adjective (“seeing eye dog”). Furthermore, many party terms can be inflected, and many of those can be separated: drive/ drove/ drives/ driven/ driving [somebody] up the wall. GT finds the correct vocabulary for “drive me crazy” in some sample languages, and conjugates it correctly in those test cases when it does. However, while the program correctly conjugates the motoring sense of “drive” in sample languages, its use in “drive up the wall” is nonsensical. On the basis of observation, not measurement, it seems that GT has separated the mapping of inflections to their canonical forms from mapping meanings across languages. That is, converting “drove” to “drive” is a different process in GT than determining whether “drive” refers to steering a car, leading an organization, or hitting a golf ball.
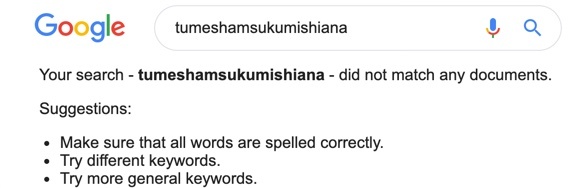
Picture 49.1: Inflected Swahili verb that does not appear in any documents. This example is somewhat absurd, but was constructed to demonstrate one of the many millions of forms of any verb that could roll off the tongue of a speaker of a Bantu language. The root verb is “sukuma”, meaning “to push”, and the inflected elements are tu+me+sha+m+sukum+ish+ia+na, translatable to English as “we have already been made to push each other on his/her behalf”.
For roughly 400 Bantu languages, an entire sentence can occur within the morphological manipulations of a single verb. For Bantu languages, the principle of agglutination that lets German compound any set of nouns willy nilly is utilized for bonding together many different grammatical elements, such as subject, tense, object, negativity, passivity, reciprocity, and much more. Picture 49.1 shows Bantu inflection in action. More detail that would boggle the brains of non-speakers is available in Kiswahili Grammar Notes, but the strict set of rules governing how people inflect verbs is internally consistent, describable, and perfectly suited for computer code – in fact, my team has built a parser for Swahili that can tear apart any verb into its component parts. Each verb in Kinyarwanda (spoken by more than 10 million people) has about 900,000,000 legitimate forms that could appear in print – were Kinyarwanda limited to 1100 verbs, the language would already have one trillion combinatorial possibilities. Correct morphological reconstruction of who drove what and when in GT’s target languages involves 108 different models that I did not evaluate per se. Nor did I evaluate conversions of inflected forms from other languages to the often simpler morphology of English. While I do not have a basis to comment empirically on the success rate of rendering inflections across languages, I can note that languages with higher Bard scores in my tests are probably doing it better.
Categories – gender, class, register, and other ways people frame their world17
Languages often add mental categories that inject further multipliers.
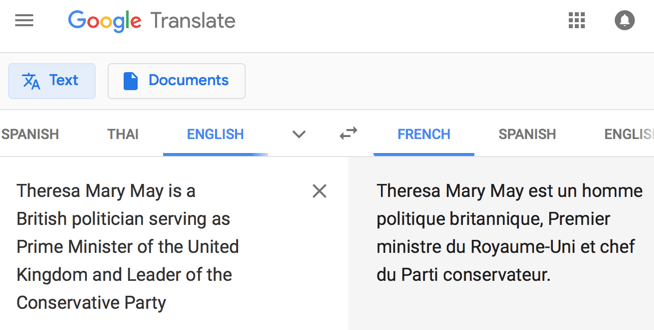
Picture 50: GT translation to French in 2018 of the first sentence of the first Google Search result, from Wikipedia, for the female Prime Minister of the UK, using entirely male vocabulary and agreements. As of 2023, this sentence now translates with the correct gender. We have no way to know whether the correction is the result of new training data, new coding to recognize gender assumptions, or manual intervention by Google, perhaps as a result of this exposure in TYB.
Gender is a non-issue in Swahili (other than a few things where the man is voiced as active and the woman as passive, like “marry” and “be married”, and the act of sex itself) and a relatively minor concern in English (with distinctions mostly regarding third person singular pronouns and some nouns such as waiter/ waitress). However, gender can carry linguistic loads far beyond sex designation in many languages, determining things like verb and adjective forms to agree with any noun. GT tends to default toward masculine constructions, except for instances such as “nurse” where the training data maps toward feminine correspondences [zotpressInText item=”{MEFLPNYW},{EEK9X7T7}”] – as of February 2022, using GT to translate “un infirmier” (a male nurse, unambiguously) from French begets “una enfermera” (a female nurse, unambiguously) in Spanish, and the same phenomenon occurs for Portuguese, Italian, and … you get the point. Wellner and Rothman [zotpressInText item=”{5248838:82UH654B}” format=”(%d%)”] raise the question of whether bias lies in the training data (e.g., all 46 US presidents have been male, so linguistic data about US presidents in the past and present tense will always attach to male pronouns) or in AI algorithms that jump to gendered assumptions based on patterns the machine teaches itself (e.g., firefighters appear in the training data as both strong and male, so a dentist who is described as strong is by association identified by AI as male). Certain cases have either been resolved by a mass of training data or by rules or by manual intervention; for example, news from the UK in 2018 was sometimes translated to French with the correct gender of the then-current Prime Minister, but she is rendered as “el primer ministro” (masculine) in Spanish, and the female Prime Minister of Barbados is given gender reassignment surgery in French as well.
Noun classes in Bantu languages have similar multiplication effects. In Swahili, for example, the markers attached to verbs to indicate subject, direct object, indirect object, and relative object, will change based on the class of each of those. (The verb morphology also changes based on time, conditionality, negativity, subjunctivity, passivity, causativity, and a few other factors [zotpressInText item=”{HEWY2F6V}”].) So various bits will change depending on whether the noun in question is me, us, singular you, plural you, class 1 (eg a pilot), class 2 (pilots), class 3 (a tree), class 4 (trees), class 5 (a car), class 6 (cars), class 7 (a knife), class 8 (knives), class 9 (an airplane), class 10 (airplanes), class 11/14 (beauty), class 16 (at a specific location), class 17 (in a general location), or class 18 (inside something else). To summarize extensive testing that a Swahili speaker could quickly replicate and would drive a non-speaker up the wall, GT handles noun classes terribly. Other languages around the world have their own multipliers that are similarly outside the capacities of GT.
A final multiplier that spans many languages is register, or level of formality. The distinction could be as basic as Spanish “tú” for people you are friendly with versus “usted” for your superiors or people you do not know well.
To sum: A human would have used “usted” in 9 cases, while GT chose that register for three of those, or 67% failure. The 4 cases that should have been “tú” were 100% correct. 2 of the 4 cases (50%) that should unambiguously have had the formal plural “ustedes” instead received “tú”. 2 of the 3 cases that should have had the informal plural “vosotros” in Spain and the sole usual plural “ustedes” in Mexico used “tu”, while the other used “ustedes”, for a failure of 67% or 100% depending on region. The overall success was 45% for Spain and 50% for Mexico.
All of the failures were for sentences where the formal register was expected, but the familiar register was delivered – that is, GT leans to the informal register for Spanish, making it extremely risky for translating any document where formality is required, such as business communication or a letter to a government agency. On the same test set from English to French, GT got all 4 “tu” constructions correct, and 6 of the 9 “vous” formal singulars; the test was not configured for French, though, because that language elides informal and formal plural people into “vous”. Nevertheless, one is cautioned against using GT to arrest someone or call them a dirty name in French, because the service will reverse the tone of the message.content here.
Japanese, on the other hand, has a system of honorifics that has earned it a 5300 word Wikipedia article,20 with an elaborate set of prefixes and suffixes performing much of the work. Something that uses proper vocabulary and syntax, but is translated in the wrong register, will generally be understood, but perhaps not appreciated. For example, legal documents must be in a formal register, while informality is often expected within chat rooms. I attempted an experiment that asked native Japanese speakers to evaluate 10 sentences translated from English for whether they were wrong, understandable, or perfect in registers suitable for a friend, a colleague, or an authority. Unfortunately, despite my getting myself banned briefly on Facebook as a spammer for trying, not enough people responded for the findings to have sufficient statistical merit for detailed analysis. The test confirms that some translations hit closer to the mark in one register or another, and the results trend toward showing that the translations skew to the less formal. Of the 10 sentences, the most neutral, “It’s raining today”, was judged as equally appropriate in all three registers. Most worked better in the least formal and/or mid register than in the most formal, even if that was not the register anticipated. For example, the evidently formal “Teacher, I have something to ask you” and “Can you write a letter of recommendation for me” were judged more appropriate in the informal, as were the less obvious “I am sorry to have kept you waiting” and “Please have a seat”. The responses seem to show that GT results would be riskier to deploy in professional situations, though this conclusion is purely tentative. What is clear is that, in the event that a GT output in Japanese is understandable, it is likely to be more correct when said to one category of person than to another.
The problem with pronouns21
Pronouns are little elements that take the place of specifically naming certain items in a sentence. They are Voldemort – he who must not be named – and they are as evil in MT as they are in Harry Potter. “This is a famous book. I read it last year. It was written by Melville. My grandmother22 studied him. She wrote critically about it [zotpressInText item=”{5248838:CS8HWFVT}”]” In a world without pronouns, we might phrase those thoughts thusly: “Moby Dick in Martin’s hands is a famous book. Martin read Moby Dick last year. Moby Dick was written by Melville. Martin’s grandmother studied Melville. Adler wrote critically about Moby Dick (ibid.).” We use pronouns because we know the context about which we form our expressions. If you say “Show him”, you and your listener both know there is one guy in focus, else in a room with several males to choose from, you would say, for example, “Show the boy in the tiger shirt”. Pronouns can point to a variety of information in the conceptual space, including gender, time (“see you then”), location (“see you there”), possession (“it’s hers”), quantity (“I’d like some”), and noun class. Or not – Japanese, for example, tends to leave them out when the subject is assumed, expressing “Took the train” instead of “I took the train”.
Because pronouns refer to things that are not directly named, they come to MT partially wrapped in an invisibility cloak. First is the issue of endophora, associating the pronoun with the named item it refers to elsewhere in the text, if at all. That knowledge may be needed to perform tasks such as giving the correct gender form of an adjective in the target language. Second is ambiguity where different languages have different pronoun systems. “You” in English could be “tú”, “usted”, “vosotros”, or “ustedes” in Spanish. When GT’s algorithms cannot determine mapping, the system makes a guess that it presents as truth. “That is a bottle. I saw it in the store” in English becomes “Eso es una botella. Lo vi en la tienda” in Spanish – GT twice chooses the wrong gender pronoun in a simple, unambiguous situation with the service’s third-best Bard rating from my testing (57.5/100). With more complex sentences, languages that have less developed models versus English, or language pairs that do not involve English, the errors mount geometrically. Kamusi Labs has a more effective potential solution, using a widget within SlowBrew translation to enable users to choose how their pronouns should map.
The finite limits of corpora23
An additional mathematical constraint for MT is the size of the corpora available for training. A corpus is a body of digitized text that serves as a reference for how language has been used. NLP researchers have learned to exploit corpora for many exciting tasks, such as identification of words, morphology, part of speech, party terms, disambiguation, and the construction of syntactic models. Corpora usually consist of relatively formal documents from the public domain, including older books and more recent public records such as parliamentary proceedings. Efforts are often made to transcribe speech from audio recordings, but the work is expensive and time consuming, generally yielding smaller datasets than corpora obtained from written literature. Most corpora are monolingual, because most texts are produced for a single language audience, and the small percentage of texts that are translated do not usually land in open datasets.
Parallel corpora between languages enable MT by providing numerous instances of directly-translated sentences, which can either be replicated exactly or used to extrapolate patterns and associations. Parallel corpora consist of texts that have been professionally translated and are publicly available, which primarily means official documents produced by bodies such as the EU, in the official languages of interest to the sponsoring governments. The translations of modern texts such as “Harry Potter” are under lock and key, as is the work product of translation agencies the world over. While out-of-copyright books like “Alice in Wonderland” and “Heidi” have been translated to dozens of languages, those translations are not necessarily open source, and nobody has yet taken up the project of aligning such works across languages. Not even the Bible, which has been translated to hundreds of languages and has a verse numbering system that is ideal for alignment, has been prepared as an open parallel corpus resource. The bigger the corpus, the more useful; for example, a corpus based solely on the concerns of the Bible’s ancient cultures, where people drew swords, drew water, and drew out leviathans with a hook, but did not draw pictures,24 would not on its own be a powerful source to translate documents of contemporary concern.
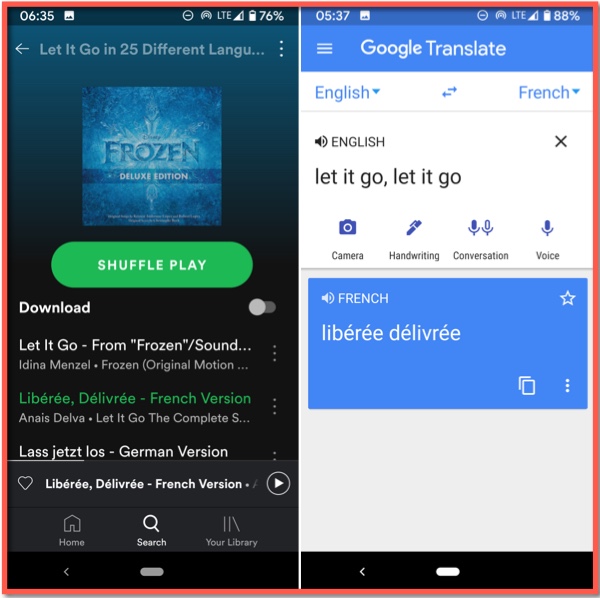
Picture 50.1: GT translates “let it go, let it go” to French based on the parallel lines in a popular song, probably learning the association from multiple websites. It is a logical guess, but it is wrong.
New corpora are often gleaned by robots that crawl the web to find texts in recognizable languages, and match languages that seem to have parallel texts. This method yields a lot of data, but much of that data is messy, often with corrupt data from innumerable sites that have been produced using GT. Computers cannot separate the wheat from the chaff without human oversight, especially when inferring translation parallels. Picture 50.1 shows an instance where GT probably imputed a translation from crawling the web. Disney professionally translated and recorded the hit song “Let It Go” from its blockbuster movie “Frozen” into 41 languages (none from Africa or India, nor any major indigenous languages of the Americas, and with an authoritarian version of Arabic that no child speaks [zotpressInText item=”{5248838:GJ8C3E4Z}”]). Examining the reverse translations of the titles shows that there was no mandate for the translators to adhere faithfully to the command “Let it go” – for example, the Romanian version reverse translates as “It happened”, Arabic as “Release Your Secret”, and Polish goes with the inspirational “I have this power”. The French version is “Libérée, délivrée”, which is well-rendered in English as “Freed, released”. Google’s neural networks, however, have apparently identified the frequent association in the corpora between “let it go, let it go” and “”libérée, délivrée”, on sites that publish subtitles and/or lyrics on the web, and GT thus erroneously declares the latter to be the proper translation of the former.
Many European lexicographers and computational linguists I meet, who do great things with corpora, do not fully appreciate that such work is not possible in the 99.96% of languages for which corpora are not a thing. For the more than 120 languages spoken in Tanzania, for example, only Swahili has three corpora, two of which are restricted (Helsinki and Sketch Engine), one of which is very small (ACALAN), and none of which is parallel to another language. Some corpora for the many European languages represented in Sketch Engine have several billion tokens.25
Africa’s 2000 languages, on the other hand, are limited to (in round numbers), Afrikaans (750,000), Amharic (20,000,000), Igbo (400,000), N’ko/ Manding (4,600,000), Oromo (5,000,000), Somali (80,000,000), Swahili (21,400,000), Tigrinya (2,500,000), Tswana (13,500,000), and Yoruba (3,500,000) – not quite 150 million tokens for the entirety of languages spoken by over a billion people. Amharic, Oromo, Somali, and Tigrinya were the output of a project26 supported by the Norwegian and Czech governments. Sketch Engine produced the Igbo, Swahili, Tswana, and Yoruba corpora through web crawls on their own initiative; importantly, because crawling algorithms will identify documents that have (e.g.) Yoruba words as Yoruba texts regardless of their provenance, corpora based on web crawls of languages in GT are now deeply corrupted because the well has been poisoned by machine-generated data. Afrikaans is the only African language included in an open parallel corpus27 of 40 languages funded by Finland. N’ko28 is a unique story, the relevant aspect in this discussion being the demonstration that any language with written records could have a useful corpus, where financial support and community passions converge. Some other African corpora exist, but the big picture is that the sum total of the digitized African corpus is roughly a tenth the size of what is available for wealthy Estonian, which has roughly a thousandth the number of speakers as African languages. Estonian had a 55% failure in my tests of GT, despite having over 2 billion tokens in readily available corpora. The languages enumerated above with the relatively toy corpora have little hope of entering into usable MT through the pathways established by languages with money. The remainder, and more than 6800 similarly-positioned languages throughout Asia, Australia, the Americas, and even minority languages in Europe, have none.29
Syntax – the difference between Tarzan and the Bard30

Picture 51: Though GT renders Stockholm’s delightful Röda Båten hotel in Romanian as roșu barcă instead of barca roșie, a Romanian will understand at a Tarzan level that it is a boat red, despite the syntax and morphology errors. http://theredboat.com
Until now, I have been talking mostly about the challenge of finding the words to populate text on the source side. If the words on the target side have the same dictionary meaning as was intended by the writer of the source text, you have what could be called “Me Tarzan, you Jane” (MTyJ) translation – Tarzan points at his 👄 and says “gură”,31 Jane says “mouth”, and communication ensues. The Tarzan scores in my tests reflect the centrality of getting the right vocabulary as the basis for understanding, as can be seen in Sentence 5 of Table 1. In order to produce elegant, Bard-like text, those words must be put in the right shapes and assembled in an order that makes sense to a native of the target language. To some extent, this is a mechanical task: verbs come at the end of the sentence in German and Japanese, so an algorithm should know to put them in that slot in those languages. GT clearly pays attention to the rules of syntax, as can be seen by testing the phrase “red boat” and seeing the translation terms exchange places depending on the noun-adjective word order of the test language. I did not perform this test systematically, and did find some failures (e.g. Romanian, see Picture 5132 ), but overall the GT success rate for noun-adjective order is much higher than random chance. Morphology can also be constructed to some extent with a good language model, for example if the source verb is determined to be conditional past tense with a human subject, then the machine can be instructed or taught to produce the form of the target verb that matches those parameters.
Beyond rules, which many in the MT world are allergic to based on failures in the pre-SMT era, there is great scope for applying AI on the target side by attempting to mimic good native text from the corpus, for those languages where corpora exist. Good algorithms can move MT a substantial way from Tarzan to Bard, though true human-like output can only be achieved through human post-editing. Comparing the Tarzan and Bard scores in my tests shows the degree to which GT has moved from finding workable vocabulary for a language, to putting it in a shape that seems natural to the language’s readers. The highest Bard ranking, Afrikaans, is 67.5, indicating that the best current MT resources can automate at most 2/3 of the translation load (like auto-pilot keeping an aircraft on course for the routine cruise portion of a flight), with the difficult 1/3 of producing artful prose left for human intervention. The next section introduces a few new concepts that could help many more languages get to that 2/3 level, and could also raise the service ceiling through the current 1/3 remaining.
References
Items cited on this page are listed below. You can also view a complete list of references cited in Teach You Backwards, compiled using Zotero, on the Bibliography, Acronyms, and Technical Terms page. [zotpressInTextBib style=”apa” sortby=”author” order=”asc”]
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- “These ideas that are driving AlphaGo are going to drive our future”: watch the compelling trailer at Alpha Go, https://www.alphagomovie.com/
- Number of Possible Go Games, https://senseis.xmp.net/?NumberOfPossibleGoGames
- link here: http://kamu.si/tyb-volume
- Wordnets for some languages have only a few thousand terms, while a few have roughly 100,000. There is no systematicity, so only some of the 6,517 terms in the Zulu wordnet will correspond to some of the 18,168 terms in the Persian wordnet, though the terms in both are matched to concepts among the 117,659 in the Princeton WordNet for English. For example, the Zulu wordnet has noun equivalents for “canoe” (🛶) and “candy” (🍬) but not “giraffe” (🦒), the Persian wordnet has “canoe” and “giraffe but not “candy”, and neither has “goat” (🐐). Persian: https://kamusi.org/info/fas. Zulu: https://kamusi.org/info/zul
- Wiktionary does not cluster near equivalents, so a definition for “reefer” counts for one and the same sense under “joint” counts as a different one.
- The method that Wiktionary devised for showing translation equivalents from English to other languages does not align suggested translations to an equivalent term in the target language in any way that can be extracted as useable parallel data. Khalil Mrini and I have a forthcoming paper on this topic – this post will be updated when we have the reference information
- Charles Gibson, “How many different ways can you spell ‘Gaddafi'”, ABC News, September 22, 2009. http://kamu.si/gaddafi-abc; JRC-Names, https://ec.europa.eu/jrc/en/language-technologies/jrc-names
- link here: http://kamu.si/tyb-lexical-gaps
- link here: http://kamu.si/tyb-semantic-drift
- link here: http://kamu.si/tyb-polysemy
- http://www.wordreference.com/enfr/out
- Most common words in English, Wikipedia, https://en.wikipedia.org/wiki/Most_common_words_in_English
- link here: http://kamu.si/tyb-party-terms
- The designation “party term” arose at the PARSEME/ENeL Workshop on MWE e-lexicons in Macedonia in 2016. During a discussion of using crowdsourcing to identify MWEs, it was observed that “MWE” itself is jargon that is unknown by and hostile to the crowd. “Party term” was coined on the spot, with the hope that NLP practitioners transition to its use. This article uses the new label because it is intended to be open to a general audience, despite the objections of some senior researchers.
- The full context of the original Chinese, Hofstadter’s translation, and GT’s attempt, is reprinted here.
- link here: http://kamu.si/tyb-morphology
- link here: http://kamu.si/tyb-categories
- link here: http://kamu.si/tyb-gender
- link here: https://teachyoubackwards.com/mt-mathematics/#register-experiment
- Honorific speech in Japanese, Wikipedia. https://en.wikipedia.org/wiki/Honorific_speech_in_Japanese#Grammatical_overview
- link here: http://kamu.si/tyb-pronouns
- https://en.wikipedia.org/wiki/Joyce_Sparer_Adler
- link here: http://kamu.si/tyb-corpora
- The King’s Bible, Bible Concordance. http://www.thekingsbible.com/BibleConcordance.aspx?dw=draw#
- Generally, a token is an item between spaces or punctuation. “Sally and her dad and you and the post-secondary teacher” is ten tokens, because “and” counts three times while “post-secondary” is just one token. However, determining tokens can be much more complicated than just finding breaks between words. For example, tokenization for Chinese is laborious because the written language does not separate words with spaces.
- HaBiT – Harvesting big text data for under-resourced languages. http://habit-project.eu/
- OPUS … the open parallel corpus. http://opus.nlpl.eu/
- N’ko corpus by the World Organization for the Development of N’ko. https://www.sketchengine.eu/nko-corpus/
- Corpora can be used to delve into tasks such as anaphoric disambiguation, associating the “none” before the footnote marker that brought you here with “hope” in the previous sentence, which could control for features such as gender or noun class in MT.
- link here: http://kamu.si/tyb-syntax
- Johnny Weissmuller, who played Tarzan in the 1932 movie “Tarzan the Ape Man”, was originally Romanian.
- Picture 51 has been edited to merge two images. The actual sign in front of the hotel is “The Red Boat” in English, whereas the masthead on their website is in Swedish. In order to illustrate the task of translating from Swedish to Romanian, I shopped the logo from the website over the real sign.