Why Wikipedia Cannot Solve NMT

Wikipedia is an excellent resource for many things, but not as a source for learning for multilingual translation. Wikipedia currently claims 301 language versions, each intended as independent entities. You can look at the type of page you will get from random searches of Galician or Occitan or Tagalog or the 1.2 million “articles” in Vietnamese1 to witness that the results are mostly lists and stubs and formal descriptions of things like “Catocala likiangenis” (not an actual Vietnamese term),2 but not any quantity of normal language that you can learn from – and nothing that could legitimately be the basis for neural network translation inferences beyond article titles and a controlled meta-vocabulary for localization and categorization. The best languages’ Wikipedias are of a quality consistent with the English Wikipedia, but that rigor drops quickly. Furthermore, neither the content nor the structure are comparable across languages. Despite its drawbacks, however, computer scientists often attempt to use it for cross-lingual comparisons, making unsupportable associations between quantity and quality. Using Wikipedia as an MT resource among most languages, without a great deal of human intervention, is poor science that can only give poor results. Nevertheless, the media parrots assertions from Google Research that AI systems predicated on Wikipedia are “already trained in 102 languages” [zotpressInText item=”{CQCEJ6R4}”]. Such notions are false and will remain false under current conditions. Unfortunately, the largest source of multilingual data on the planet cannot be used as fodder for translation. Here are 7 reasons why:
- Wikipedia articles are usually not direct translations of each other, by intent. For example, the English article about Tokyo has some of the same information as the Japanese article about the same city. For the most part, though, they are different entities, with different contributing editors, evolving over time on their own trajectories. In fact, it turns out that human translations of the Tokyo pages in Wikipedia is the subject of an article in the journal “Target”, [zotpressInText item=”{5248838:CBTDEW2P}”], that delves deeply into the philosophical issue of heterotopia within Translation Studies – a level of analysis that adds a great deal of complexity to the subject of how closely computers can hue to the nuance of human thought. Table 11 shows the opening of the “Economy” section. Using GT in its proper capacity to get a broad sense of the original Japanese (rather than trying to use the translation from Japanese to learn important facts about Tokyo), we can see that the two articles have nothing to do with each other. The English side quotes different sources than the Japanese side, mentions different statistics from different years, compares Tokyo to different cities, and discusses different topics. Counting crudely, the English article has about 7,800 words, while the Japanese article is nearly double that, with about 15,000 words in the GT translation. These five words, meanwhile, are the sum total of linguistic content in the Wolof Wikipedia article about Tokyo: “Tokyo mooy péyu réewum Sapoŋ”.3
2. As the Wolof “article” about Tokyo shows, a great many supposed articles in diverse language Wikipedias are actually “stubs”, basically placeholders that state the existence of something in the hope that someone will someday write a more complete article in that language. Many of these stubs are created by robots, perhaps with the intent of inflating the numbers of articles in a given Wikipedia. For example, as shown in Picture 62, thousands of articles in the Yoruba Wikipedia, which boasts 31,766 articles as of 27 November 2018, are merely automatic creations that give the name of an asteroid, and state that it is an asteroid. The Swahili Wikipedia, which has some very good content among its 47,423 articles, also has thousands of stub articles naming rivers, towns in France, random years (e.g., the article “22” only states that “This article is about the year 22 BC (Before Christ)”4), and the like. The Swahili article about Tokyo is 14 sentences with 173 words edited over nearly 12 years by several volunteers, plus more than 100 bot edits supplying interwiki links and other automated data. Though articles for Tokyo have been started for 225 languages, spot checks of the interwiki links show that most of those are shells, devoid of useful linguistic content. Such vacuity is true of a very high proportion of articles throughout the Wikipedia ecosystem.
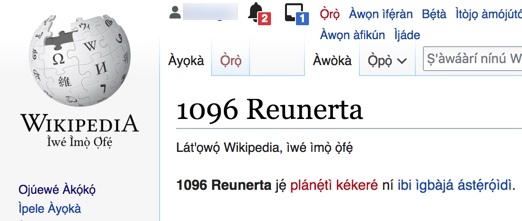
Picture 62: Common page naming an asteroid in the Yoruba Wikipedia. 1096 Reunerta: Wikipedia (Yoruba).
3. Wikipedia is a project that anyone can edit, which works very well for languages that have a large number of eager volunteers. However, many languages have very few contributors, and therefore very few people monitoring the content. The effect is that articles slip into many Wikipedias regarding the agendas of particular people (for example, religious screeds), with no control over linguistic quality. That is, some of the content resembles the murkier parts of the internet you might be familiar with in a language like English, which a linguist would never look to as a clear source for natural language.
4. Wikipedia is a superb way to find out how certain things are translated in real life. For example, Hollywood movies are often renamed in other languages, and following the interwiki links to those languages will reveal their local titles. Automating inferences about what term in one language corresponds to an equivalent term in another language, though, is often impossible. Even at the level of the main subject, a human must read closely to determine how two languages relate. For example, the article for “field goal” in English is about American football, while separate articles appear for “Field goal (rugby)” and “Field goal (basketball)”, and the rugby page notes, “For the modern Australian rugby league sense, see Drop goal”5. The English page about Tokyo makes mention of innumerable terms that may or may not appear in another language’s version, such as “kanji homograph” or “incendiary bombs” or “urban growth”. Because all of those terms appear free-form in a sea of thousands of other words, there is no way, no matter the persistent hype about the miracles emerging from neural networks, to even begin guessing points of comparison among languages.
5. In the best cases, Wikipedia articles are written in very good formal language. The writing style is well-suited for encyclopedic content, and would be good training material for technical translations if it were possible to align sentences across languages. The writing style is not how people normally speak or write, however, which means that one would be hard pressed to use the text as computational fodder for learning linguistic patterns from other languages. Imagine trying to discern English grammar from a sentence like “Tokyo is often referred to as a city but is officially known and governed as a “metropolitan prefecture”, which differs from and combines elements of a city and a prefecture, a characteristic unique to Tokyo”. That is one of the less complex sentences in the English article about Tokyo. An editor for the Waray language of the Philippines took the strategy of translating that sentence directly, “An Tokyo bisan agsob tinutodlok komo usa ka syudad, in opisyal nga kilala ngan pinamumunuan komo usa ka “prefektura metropolitana”, nga naiiba ngan gintampo an mga elemento han usa ka syudad ngan usa ka prefektura, usa ka gahom nga para gud la ha Tokyo”, but even knowing that the sentences align at the eyeball level does not give inferential insight into the structure of Waray for NLP applications.
6. Under the hood, every Wikipedia article is written in a mark-up language that wraps tags around content in complicated ways. It is possible to scrape the mark-up, but getting clean text is an effort that requires many iterations and a lot of human oversight. Picture 63 shows the type of mark-up that needs to be carefully excised in order to reveal actual linguistic content.

Picture 63: A snippet from the English Wikipedia article about Tokyo showing the item as it appears on the web page versus the source text in Wiki Markup as it is distributed to computers.
7. Wikipedia pages do not share a consistent structure from one language to the next, so it is nearly impossible to align even when it is intended to be equivalent. Finding data within Wikipedia articles is orders of magnitude more complicated than, for example, finding author names at the beginning of formal publications, as achieved with only partial success by Zotero (discussed in the qualitative analysis in relation to the Myth of Artificial Intelligence). Many Wikipedia articles incorporate Wikidata, a similar notion of codifying particular facts across resources, such as a city’s population or geographic coordinates. However, there is no consistency across languages. For example, the English article about Tokyo has numerous data points about the population, broken down by “Metropolis”, “Density”, “Metro”, “Metro density, and “23 Wards”. The German version, however, has the single data point “Einwohner” (inhabitants). Even though the languages share the same backbone, putting the same data into a side table in the same location on the page, using known points of comparison, an alignment program such as Zotero would still fail if it tried to match a simple, common correspondence such as population. Robotic extraction of parallel linguistic data across the panoply of inconsistent Wikipedia pages would quickly self-incinerate.
References
Items cited on this page are listed below. You can also view a complete list of references cited in Teach You Backwards, compiled using Zotero, on the Bibliography, Acronyms, and Technical Terms page.
[zotpressInTextBib style=”apa” sortby=”author” order=”asc”]
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- Click multiple times on these links to get a flavor of the extant data.
Random page on Galician Wikipedia.
Random page on Occitan Wikipedia.
Random page on Tagalog Wikipedia.
Random page on Vietnamese Wikipedia. - Catocala likiagenis, Vietnamese Wikipedia. This is the total actual content of the article: “Catocala likiangenis là một loài bướm đêm trong họ Erebidae”. https://vi.wikipedia.org/wiki/Catocala_likiangenis
- Tokyo: Wikipedia (Wolof). https://wo.wikipedia.org/wiki/Tokyo
- 22: Wikipedia (Swahili). https://sw.wikipedia.org/wiki/22
- Field goal (rugby): Wikipedia (English). https://en.wikipedia.org/wiki/Field_goal_(rugby)