Empirical Evaluation of Google Translate across 107 Languages

Google Translate (GT) is the world’s biggest multilingual translation service, both in terms of number of languages and number of users. I conducted a scientific evaluation of translations produced by Google, for all 107 languages vs. English in their roster. Such a study, using native speakers for every language, has never been done before. Evaluators everywhere from Samoa to Uzbekistan were recruited to examine Google translations in their language. This chapter reports their results.
Picture 10.1: Full data for the empirical evaluation of 107 languages versus English in Google Translate can be inspected, and copied as open data, by clicking on the picture or visiting http://kamu.si/gt-scores
To make use of the ongoing efforts the author directs to build precision dictionary and translation tools among myriad languages, and to play games that help grow the data for your language, please visit the KamusiGOLD (Global Online Living Dictionary) website and download the free and ad-free KamusiHere! mobile app for ios (http://kamu.si/ios-here) and Android (http://kamu.si/android-here). How much did you learn from Teach You Backwards? Your appreciation is appreciated!:
Description of Empirical Tests1
A. English to Language X2
I asked native speakers of each language to evaluate a fixed set of 20 items translated from English to their language. Respondents were asked to rate each translation on a scale of A (good), B (understandable), or C (wrong). For example, an evaluator might give the equivalent of “not good see” a B score for “out of focus”. From these reports, I determined two ratings. The “Tarzan” score reflects the percentage of time that GT gave a result that transmits roughly the original meaning, regardless of the quality. The “Bard”3 score is a measure of how often GT arrives at human-caliber translations, with A translations weighted double over B. “Tarzan” indicates the base level functionality of GT between English and a given language – the ability to communicate “Me Tarzan, you Jane”4 (MTyJ) in such a way that Jane and Tarzan know what each other are talking about. “Bard” indicates the extent to which GT produces translations from English that sound natural to a language’s speakers. The “Tarzan” designation is not meant to be pejorative – enabling rudimentary communication between people who could not otherwise converse is an extraordinary accomplishment, with an instance of effective Tarzan translation shown in Sentence 5 of Table 1 and a photo of a real-life Tarzan translation situation in Picture 16.1 – but it is intended to indicate where the language’s technical integration sits between stone axes and iPhones.
The goal of the test was to discover whether GT delivers understandable equivalents of meaningful formulations that occur regularly within common English. Translating outward from English is the most consistent use-case for GT. In addition, Google has developed extremely strong processing tools for English that it can apply whenever English is the source language, such as the ability to identify parts of speech (e.g. distinguishing the verb from the noun in “I will pack a lunch in my pack”), named entities (e.g. treating “Out of Africa” as a film title that should be left intact), and inflected forms (e.g. marking “I thought” as first person past tense of “think”). I therefore tested the task on which GT is most likely to show its strongest performance: from the vocabulary and training materials in its central language, vis-à-vis the languages that they have directly matched.
B. Language X to English5
I did not systematically test translations from other languages toward English, which would be a perniciously difficult study to implement. One could not ensure, for instance, that a random starting text for Basque was at the same complexity as a starting text for Maori. I have done one small experiment, however, that demonstrates how a true test from all languages to English could be accomplished.
The quote from Nelson Mandela that gave birth to the title of this study, “Lead from the back – and let others believe they are in front” – rendered by GT from its human Japanese translation back to English as “Teach you backwards – and make you believe that you are at the top are you guys” – is a typical instance of the sort of phrase that people regularly seek to translate using MT. The meaning of the complete phrase is unambiguous to any competent English speaker, but several of the words are ambiguous when taken individually. I sought human translations for the entire GT language set (though if this parenthetical comment is visible, at least one language at http://kamu.si/mandela-lead is still missing). This quote had already been translated into 14 GT languages plus Aymara6 by volunteer translators at Global Voices. I elicited many additional translations by tapping various social and professional networks. Assuming 10 minutes per language – to find a contact, send a note explaining the task, and then copy the reply, run it through GT, copy the GT result to the data file and a separate file for BLEU testing, perform and record the BLEU test, credit and thank the translator – completing this one phrase in 107 languages is a minimum investment of over 1000 minutes – and more if the first contact does not respond, or a treasure hunt is needed to find a native speaker.7
These human translations all express exactly the same idea. For the experiment, I fed each of these Language X identical phrases to GT, and share the output as open data at http://kamu.si/mandela-lead. You can see that the results vary, from perfect for Spanish and Afrikaans (using the word “behind” instead of “the back”, which is completely legitimate though would bring down the BLEU score) to collections of words that include some that appear in Mandela’s sentence, such as Malayalam (“Lead people back and forth – believe others are still ahead”), Yoruba (“Behind the back so that some people can not believe that they are in front”), and the Slovak clause “Drive away from the seclusion”. I ended up with five different German translations (including two that contacts found already existed on the web and two variations based on register from a single translator), none of which came back through GT with the full essence of Mandela’s sentiment.
No scientific inferences about the quality of translations from a given Language X to English are possible from this single data point for each language. However, the experiment does let a little light through the blinds.
- Machine translations will almost always include some words in English that are the same as those a human would choose. For example, though “Hi, don’t let others believe that they are before” (Zulu) fails to transmit the meaning in any way, it does contain the elements “let others believe” and “they are”.8 “Due to the buttocks, other mice should walk in the front” (Yiddish) contains “other” and “front”.
- Translations can be correct for one clause and wrong for others. For example, “Walk back” (Macedonian) and “Head as if you were behind your back” (Lithuanian) both botch the first half, but nail the second.
- There can be shades of grey about whether a translation conveys the original meaning. For example, “Rule from the back” (Polish) has more of an aspect of dictatorship than the benevolent guidance that Mandela had in mind, blurring but not erasing the overall intent of the quote.
- As with English to other languages, translations can vary for unpredictable reasons. For example, the end of one Georgian translation switched between “to go” and “to be better off” depending on whether the phrase ended with a period or a semicolon. This makes overall quality assessment difficult, because you do not know if a translation might be more or less accurate based on untestable variables.
- Different human versions within one language can meet differing success in English. For example, Korean had one translation that GT returned spot on, one that was close but no cigar, “Stand behind and lead – and believe that people lead themselves”, and one that was completely off the rails, “Head back, let others believe you’re leading him”. This points to why a large variety of such parallel translations from each language would be necessary for valid inferences.
- How closely GT came to reproducing the original Mandela quote may be related to how closely the translator could hew to the original English structure versus cracking some eggs to make the omelet. For example, “Judge in such a way that people feel they are responsible for making things work” is wrong, but it is wrong in a way that could reveal how the translator tried to make the sentiment come out right in Shona.
- High-investment languages do not necessarily have higher results. For example, “Head from behind” (French), “Run from behind” (German), and “Straight from the rear” (Italian) all fail to convey the original intent.
- Many human translators take their tasks quite seriously, fretting over minor nuances. Several submitted more than one translation of the same phrase. GT does offer a second translation possibility for power users who know where to click (do you?), but both translations are subject to the same computational limitations. The options for Somali, for example, are either “Follow the back of the lead and let others think they are already” or “Taking the lead from the back and let other people do not think of themselves that they have levels”.
- As seen in translations from English to Language X and from Language A to Language B elsewhere in this study (e.g. the phrase “I will be unavailable tomorrow” between English and 44 languages discussed in Myth 5 of the qualitative analysis, and the German translation of a French news article discussed in the analysis of Google’s pivot process), Language X to English translations have a non-trivial risk of forming human-sounding phrases that flip the meaning 180°. For example, “Convince others that you are ahead of them and manage them” (Azerbaijani).
A thorough study of all GT languages toward English would repeat this exercise of getting human translations for a substantial number of test sentences and reverse-translating them to English with GT, and would then use multiple native English-speaking human evaluators to rate how well each reverse translation came toward capturing the original English meaning. The methodology is not complex, but it would take tremendous time and effort, and was well outside the scope of the present unfunded research.
C. Language A to Language B9
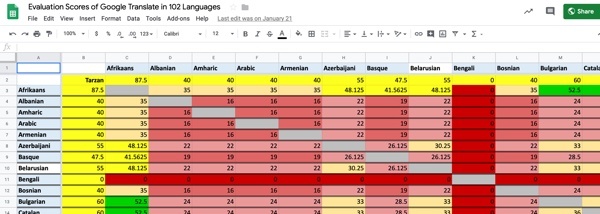
Picture 10.2: Predictive scores of translation among all language pairs within GT except pairs with KOTTU, based on Tarzan ratings to the English pivot. Full data is at http://kamu.si/gt_scores_cross_language_extrapolation

Picture 11: Almost all Language A to Language B translations in GT are two stage conversions through an English pivot.
I did not evaluate translations directly among languages other than English, because in almost all cases10 Google makes a two-stage conversion from Language A to English and then English to Language B. A technical lead at GT minimizes the centrality of the English pathway, saying, “Sometimes we bridge through other languages and lose a little bit of information along the way” (, 1:21:25), then inexplicably denies that English as the pivot is the predominant route; my research finds this denial to be untrue.
The English bridge is evident by testing translations even in cases where the linguistic, research, and market environments would suggest a direct path, such as Corsican to French or Italian (see Picture 12 for an instance where GT revealed the pivot language). Language A to Language B translations degrade at roughly11 a multiple of the score of each vis-à-vis English. For example, the Tarzan ratings are 55 for Serbian and 50 for Russian, so Serbian to Russian could be estimated at 50% of 55, for a Tarzan score of 27.5. However, I cannot be sure that the score we’ve obtained from English to Language A is the same as what would be obtained from Language A to English. In the present example, I assume that the Tarzan score for Serbian to English is 55, on the basis of the score from English to Serbian, but I do not have the hard evidence to make declarative statements based on this claim. We know a priori that two-stage translations inherently compound the errors each language experiences in relation to English, but I cannot give figures that have a confirmed scientific basis. Calculating the score of Language B as a percentage of the score of Language A produces an indicator of confidence between the two languages, but not a final measure.
By presenting their translation proposals from Language A to Language B without caveats, Google gives an implicit confidence measure of 100%. Google has never published quantitative analysis of the vast majority of their translation pairs in any scientific format. Their unqualified representation that they produce empirically valid translations is false between almost all non-English pairs.
The table in the tab “Language-to-Language Tarzan Extrapolations” in the TYB data release, http://kamu.si/gt_scores_cross_language_extrapolation, shows confidence estimates between each language pair, assuming English as a bridge; I repeat that these pairs have not been individually tested, so the numbers should be viewed only as indicative.
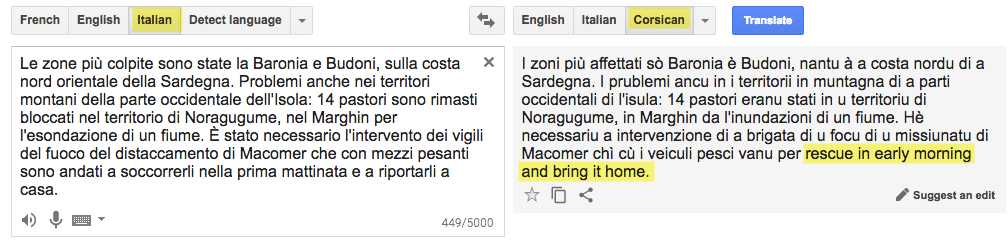
Picture 12: GT from Italian to Corsican revealing the English bridge in most translations from Language A to Language B. Italian and Corsican are closely related languages.
Methodology12
I tested clusters of two or more words that often occur together, and that have a meaning that is generally discernible when they do;13 for example, tweets with “out cold” almost always imply unconsciousness.
I did not test single words, which can be highly ambiguous (for example, right = correct, legal entitlement, politically conservative, the not left direction, etc.), and therefore too arbitrary in isolation, although a major challenge for MT from English is that the top 100 words (as tallied in the Oxford English Corpus), which constitute about 50% of all written English text, have on average 15.45 senses in Wiktionary.14 Although GT does not advertise itself as a dictionary, single-word lookups are a major proportion of real world uses of the service.
Nor did I test full sentences, which add a lot of complexity to scoring, since translations might include both correct and incorrect elements. For example, the sentence “’Out of Africa’ won the Academy Award for best picture in 1986” had mistakes in all ten of the languages I spot-tested it in (including high-performers like Afrikaans and German), but different languages made mistakes in different parts of the sentence, particularly how they rendered the title and whether “picture” was given as an illustration or a film. Moreover, humans can translate the same sentence many ways, making it impossible to determine a gold standard for full sentences, especially across dozens of languages – an example can be seen in the German translations submitted for the Mandela quotation that kicks off this web-book. It should be noted that GT alters its vocabulary choice on the fly, so the words chosen to translate a short phrase may not be those selected in a longer sentence, or even at a different moment; for example, “run of the mill” is represented in French by “courir du moulin” in isolation, and “course de l’usine” when translating a longer tweet (both wrongly referring to foot races), and other instances might produce other results.15
Neither did I test full documents, where Läubli, Sennrich, and Volk show that raters show a markedly stronger preference for human translations as compared to an evaluation of single, isolated sentences; such a study would be extremely expensive across more than 100 languages.
All of the clusters contained the word “out”. This word is ubiquitous, ranking as the 43rd most common word in the Oxford English Corpus.16 It is extremely ambiguous in isolation, with 38 senses in Wiktionary, but often occurs in clusters with unmistakable meanings. WordReference.com gives definitions and French equivalents for nearly 1700 composed expressions that include “out”, from “a fish out of water” to “zoom out”.17 Additionally, a dataset with compositional information for 560 phrasal verbs ending in out is available as open data . While “out” is an outlier in terms of its scope, it is a known entity within English lexicography and NLP. I chose 20 formulations that are lexicalized in WordReference as composed forms such as “out of style”, or that, as queried on Twitter, usually reduce to defined meanings when matched with other particular words, such as “out of milk”.
All of these items have been translated in electronic bilingual dictionaries, so are thus similarly viable as units for machine translation. The expressions were not chosen to be especially simple or difficult, nor based on corpus frequency. Rather, they were chosen because they had clear meanings,18 and are broadly representative of the types of phrase that ordinary users are likely to seek to translate – for example, an American expatriate in Budapest related that he tried several times to use the Hungarian conversion of “like a bat out of hell” until he learned that GT got the words all right and the meaning all wrong.
I explicitly did not test ambiguous expressions in GT, because these are already known weak points in MT. An ambiguous expression from English is likely to be translated correctly in one or more contexts, but not in all. For example, ascertaining the failure rate of the sentences in Table 2, expected to be 75% to 87.5% (assuming that GT has one or two translations of the candidate term in its repertoire that have to land somewhere), will only reveal the general truism that GT has difficulty with common English phrasal verbs, rather than showing how this difficulty manifests across languages. You are encouraged to test that premise on the following tweets with a language you know well:
| 1. I wonder the emotions of Joseph when he held up [= raised] the baby Jesus, knowing his image wouldn’t be reflected in the face of that child.19 |
| 2. Got held up [= mugged] at gunpoint on Wednesday walking to work in broad daylight by 2 men. They took my phone, wallet, glasses, keys, headphones, everything.20 |
| 3. Our journey home from a hilltop restaurant was held up [= stopped] for 10 minutes. Why? Ask the porcupine that decided to try & outrun the bus.21 |
| 4. My great grandmother had some epic #style. These @ray_ban sunglasses have held up [= endured] for more than 50 years 😎.22 |
| 5. The argument that belief in the internet is necessary for sending tweets has never held up [= survived] to scrutiny.23 |
| 6. Rain, rain, rain. But spirits held up [= buttressed] by the constantly surprising friendliness of the locals.24 |
| 7. “She’s being held up [= slowed] from behind by the real guilty party”.25 |
| 8. “The UK is held up [= glorified] as a liberal democracy”26 |
| Table 2: “Held up” is an example of an expression that was considered inherently likely to fail in all languages, and therefore too ambiguous to include in the study for gaining useful comparative information across languages. |
The selection of phrases for this study (see Table 3) is therefore not rigidly scientific, and the reader can decide whether the items provide a fair test of MT capability.27 The least-recognized phrase, “out cold” had a 90% fail rate, with just 3 “A” ratings (Hausa, Hindi, and Malaysian) and understandable to some extent 10 times, while the phrase “out of the office” produced 49 “A” ratings and an understandable result 83.6% of the time.
| Original English Phrase | English Paraphrase | A | AB | AC | B | BC | C | Bard | Tarzan | Fail | |
| 1 | fly out of London | take an airplane from London | 33 | 10 | 0 | 43 | 1 | 23 | 34.5% | 79.1% | 20.9% |
| 2 | like a bat out of hell | escaping as quickly as possible | 2 | 1 | 0 | 17 | 6 | 84 | 2.3% | 23.6% | 76.4% |
| 3 | out cold | unconscious | 3 | 0 | 2 | 6 | 0 | 99 | 3.6% | 10.0% | 90.0% |
| 4 | out of bounds | unacceptable | 7 | 0 | 0 | 34 | 4 | 65 | 6.4% | 40.9% | 59.1% |
| 5 | out of breath | gasping for air (for example, after running) | 35 | 2 | 1 | 27 | 5 | 40 | 33.2% | 63.6% | 36.4% |
| 6 | out of curiosity | because a person is casually interested in something | 33 | 7 | 0 | 30 | 3 | 37 | 33.2% | 66.4% | 33.6% |
| 7 | out of focus | not clear to see (blurry) | 21 | 6 | 0 | 24 | 3 | 56 | 21.8% | 49.1% | 50.9% |
| 8 | out of his mind | crazy | 5 | 0 | 0 | 21 | 8 | 76 | 4.5% | 30.9% | 69.1% |
| 9 | out of milk | the supply of milk is finished | 4 | 0 | 1 | 12 | 4 | 89 | 4.1% | 19.1% | 80.9% |
| 10 | out of order | does not function (broken) | 32 | 3 | 0 | 18 | 1 | 54 | 30.9% | 50.9% | 49.1% |
| 11 | out of pocket | paid for something from personal money | 18 | 0 | 0 | 33 | 5 | 54 | 16.4% | 50.9% | 49.1% |
| 12 | out of steam | no more energy (exhausted) | 3 | 1 | 0 | 5 | 3 | 98 | 3.2% | 10.9% | 89.1% |
| 13 | out of style | unfashionable | 21 | 4 | 0 | 43 | 2 | 40 | 20.9% | 63.6% | 36.4% |
| 14 | out of the closet | openly homosexual | 9 | 2 | 0 | 13 | 3 | 83 | 9.1% | 24.5% | 75.5% |
| 15 | out of the game | no longer participating in a game | 34 | 3 | 1 | 34 | 5 | 35 | 30.9% | 68.2% | 31.8% |
| 16 | out of the office | away from the office | 49 | 5 | 1 | 35 | 2 | 18 | 47.3% | 83.6% | 16.4% |
| 17 | out of this world | excellent | 3 | 2 | 0 | 8 | 5 | 92 | 3.6% | 16.4% | 83.6% |
| 18 | out of time | a deadline has passed | 14 | 7 | 0 | 47 | 3 | 39 | 15.9% | 64.5% | 35.5% |
| 19 | out of wedlock | between partners who are not married | 30 | 6 | 1 | 29 | 1 | 43 | 30.5% | 60.9% | 39.1% |
| 20 | out on the town | having a fun time going shopping or to bars/ restaurants (carousing) | 4 | 0 | 1 | 15 | 4 | 86 | 4.1% | 21.8% | 78.2% |
| Table 3: Evaluation phrases and their scores. AB, AC, and BC signal inter-annotator disagreement. Updated with KOTTU, March 2020. Itemized scores and translations for all languages can be viewed at: http:// kamu.si/gtscores_itemized_and_translations | |||||||||||
Picture 12.1: Itemized translations and scores from English for all other 107 languages in GT. Full data is at http:// kamu.si/gtscores_itemized_and_translations
Scores are not absolute, for two reasons. First, the choice of expressions was arbitrary. A different selection of English expressions would generate different numerical results within each language; for example, scores would probably fall were a larger number of idioms such as the confounding “like a bat out of hell” to be included. Relative results would likely remain essentially the same, however; a language with high scores for my test set should perform highly with other phrases, while a language with low scores herein would have similarly low results with other input. Second, most language scores show the subjective opinion of a single reviewer. One could well argue that more reviewers per language would produce more reliable data. Several languages had multiple reviewers, and inter-annotator disagreements were usually minor, with a handful of entries per language being judged good versus marginal, or marginal versus wrong. A single entry being ranked by different evaluators as good versus marginal does not change the Tarzan score, and changes the Bard score by 2.5 points, and a disagreement between marginal and wrong changes both Tarzan and Bard by 2.5. I averaged the scores where annotators disagreed, and kept the disagreements visible in the public data release. Based on the inter-annotator disagreement values I discovered, the reader is advised to place mental error bars of ± 10 around the score that is reported.
For Portuguese, I report European, American, and Cape Verdean scores as independent results, and for Spanish I report separate scores for Europe and Latin America. On the other hand, I considered the “traditional” and “simplified” versions of Chinese (Mandarin) as one language, because the only difference is the writing system (similar to the equivalence of Serbian whether written in Latin or Cyrillic script), as verified by my tests. For cross-language comparisons, I used the highest-scoring member of the set.
Evaluators28

Picture 13: A typical MT task where readers cannot gauge accuracy if they are not already proficient in both the source and target languages would be to render this article from Armenian into another language. The non-Armenian reader has no way to judge whether the output conveys the original intent.
Translations were evaluated by native speakers of each language.29 Evaluators had a range of backgrounds, such as nurse, high school student, diplomat, musician, computer scientist, and language professional. Many of the evaluators were identified through the PI’s prior social and professional networks. When those fell short, extensive use of LinkedIn revealed many second or third degree contacts whose profiles stated they had native proficiency, and who agreed to participate. When LinkedIn fell short, members of Facebook language interest groups whose pages had posts in the required language were contacted. In a few cases, none of these methods were fruitful, and university librarians or public service organizations were contacted to help locate a willing native volunteer.
Evaluating translation results presents a paradox: the person reading the translation should be able to understand the intent of the original expression without having any knowledge of the original words, yet their understanding cannot be confirmed without recourse to the original. Therefore, some knowledge of English was essential to the evaluation task. First, the evaluator needed to understand the instructions as written in English. Second, the only way to test whether the original meaning had been understood in the target language was to share that meaning in English, using the same wording for each evaluator. The English testing environment inevitably alters the response. In an ideal test, the respondents would have no knowledge of the original intent, since a major goal of MT is to render documents for people who do not have a human-level communication bridge, such as reading a news article in an unfamiliar language (see Picture 13).
I found that evaluators who spoke English at a very high level tended to give higher scores than people with lesser proficiency. For example, the Bard rating for Indonesian from a speaker working at a European office of Google (not for GT) was ten points higher than from an evaluator who has always lived in Indonesia. In a few cases, respondents tried to reverse-engineer the survey, replacing the provided paraphrases with the original phrase and rating whether the translation rendered the actual words – for example, did “out of steam” translate “steam”, instead of the question of whether it translated the idea of exhaustion.
In some cases, the English connection points toward interesting questions for future linguistics research. Several of the languages co-exist geographically in places where English dominates the communications landscape, including Afrikaans, Hawaiian, Irish, Maori, Samoan, Scots Gaelic, Welsh, Xhosa, and Zulu. English is often at least a co-equal language in the lives of those language’s speakers. This milieu might predispose people to an English metaphorical framework that could shape their interpretation of translations of phrases such as “like a bat out of hell”.
The language that performed the best in this study is Afrikaans, which has close common ancestors with English, drifting from Dutch only within the past 300 years, during which it has interacted intensively with English in South Africa. The Afrikaner evaluators understood the figurative meanings of several phrases that were translated word for word, where such literal translations had no resonance for speakers of other languages. Conversely, some English metaphors have been adopted in other languages. For example, “the closet” as hidden sexual identity was understood in a few places where the local gay community imported that sense to their own word for closet, or, in Latin American Spanish, actually borrowed the English word. The present study opens more questions than it answers – for example, Xhosa and Zulu overlap in the same South African landscape with English and Afrikaans, but scored near the bottom, and this study is not equipped to resolve how much of this discrepancy is due to differential exposure to English by the evaluators, underlying similarity between Afrikaans and English that does not exist for the two indigenous African languages, or limitations to the translations proposed by GT for Xhosa and Zulu. It is clear, though, that the extent to which GT users already understand English has some effect on their ability to understand the translations between English and their language.
Empirical Results30
This section reports the numerical findings of the study. Qualitative interpretation of the results is intentionally excluded from this report, and presented in separate parts of this article. The intent is transparency. The study was motivated by the need to locate underserved translation situations, to build a case for work that might improve them. However, mixing together research findings and broader editorial concerns would open up considerations of bias in the numbers themselves. I have gone to great lengths to ensure that the numbers will withstand scientific scrutiny, including forthright discussion of their limitations in the Methodology section above. Consider the results reported below to be similar to the findings of climate scientists who believe that their measurements of rising temperatures support particular interventions that they propose; this part is akin to a report that lays out the bare temperature news in 107 locations around the world,31 while the other parts offer informed opinions about what the numbers mean32 and what should be done to change them.33
My results seem to resemble those newly reported by Google researchers . They state that their top 25 languages had an average BLEU score from English of 29.34, their middle 52 languages averaged 17.50, and their bottom 25 averaged 11.72, using an open-domain dataset containing over 25 billion sentences imputed to be parallel. They do not provide disaggregated per-language scores. Exact comparison is not possible without access to their specific data, but my findings seem to paint in pointillistic detail an image similar to what they present in watercolor.
A. Elegance from English34
| Bard Score | # of languages | % of languages |
| 50 or above | 12 | 11.2 % |
| 25 to 47.5 | 55 | 51.4% |
| below 25 | 40 | 37.4 % |
| Table 4: Bard Scores (A rating = 5, B = 2.5, C = 0) | ||
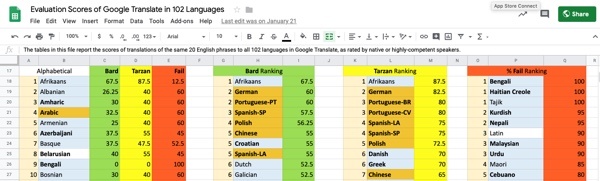
Table 4 shows how closely evaluators deemed a translation to arrive at human quality. Twelve languages achieved a Bard score of 50 or above, including separate evaluations by different regional speakers of Portuguese and Spanish, in this order: Afrikaans (67.5); German and Portuguese-PT (60); Spanish-SP (57.5); Polish (56.25); Chinese, Croatian, and Spanish-LA (55); Dutch, Galician, Greek, Portuguese-BR and Portuguese-CV (52.5), and Italian and Latvian (50). Fifty-five languages were rated between 25 and 47.5. Forty languages received a Bard rating below 25.
Aggregated across languages, one phrase achieved a human level in the range of 50%, about one-third reached this level about one-third of the time, and about one-third of candidates resembled human translations less than one time in twenty, as shown in Figure 1.
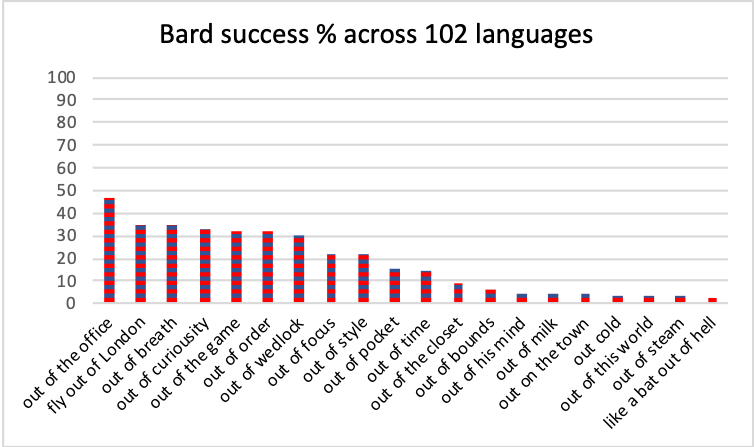
Figure 1: Percentage of languages for which each candidate translation was judged to resemble a human translation. Data for all 107 languages is in Table 3. This figure shows the 102 pre-KOTTU languages.
B. Gist from English35
| Tarzan Score | # of languages | % of languages |
| 75 or above | 4 | 3.7% |
| 50 to 72.5 | 39 | 36.4% |
| 25 to 47.5 | 48 | 44.9% |
| below 25 | 16 | 15.0 % |
| Table 5: Tarzan Scores (A rating = 5, B = 5, C = 0) | ||
Table 5 shows the frequency with which evaluators deemed a translation to convey the general intent of the original English phrase.36 43 languages received a Tarzan score of 50 or above, with 12 languages achieving understandable results approximately 2/3 or more of the time: Afrikaans (87.5); German (82.5); Portuguese (BR and CV) (80); Spanish (LA and SP) (75); Polish (72.5); Danish and Greek (70); and Chinese, Croatian, Dutch, Finnish, Hungarian, and Portuguese-PT (65).
One third of the languages failed at least two thirds of the time. Two thirds of the languages failed at least half the time.
Bengali, Haitian Creole, and Tajik failed 100% of the time, and these languages failed 80% or more: Cebuano, Georgian, Kinyarwanda, Kurdish, Latin, Malaysian, Maori, Nepali, Persian, Punjabi, Urdu, and Uzbek. Aggregated across languages as shown in Figure 2, two translation candidates were rated intelligible in about 80% of cases, and about one-third conveyed the meaning about two-thirds of the time. Three-fifths of candidate expressions had the gist rendered half the time or less, and more than a third were comprehensible in fewer than a quarter of the languages.
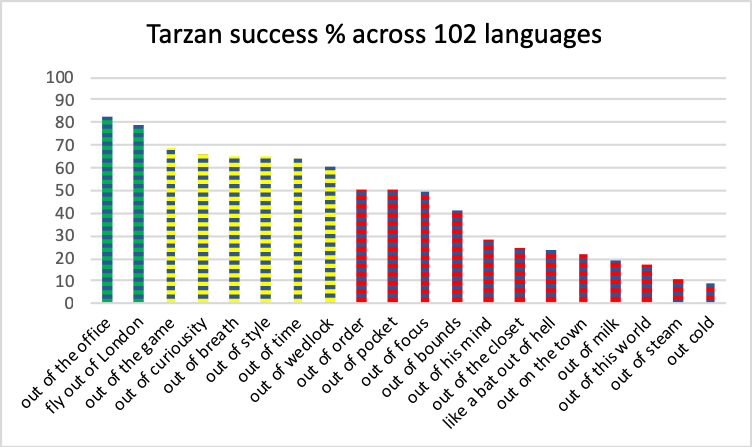
Figure 2: Percentage of languages for which each candidate translation was judged to convey at least the general sense of the expression. Green indicates greater than about two-thirds, yellow indicates between a half and two-thirds, and red shows scores in the range of half and below. Data for all 107 languages is in Table 3. This figure shows the 102 pre-KOTTU languages.
The video above shows native speakers trying to find the gist of Google translations of well-known English quotes, in four languages.
C. Non-English Pairs37
 |
 |
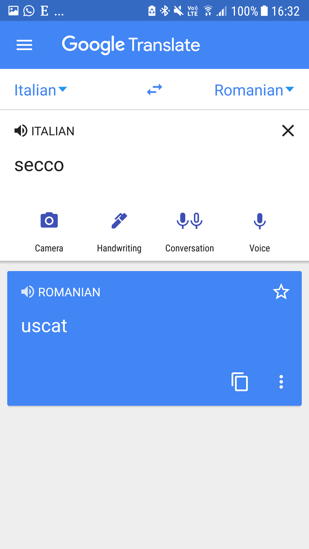 |
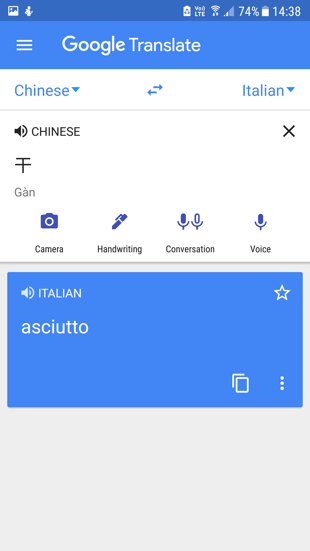
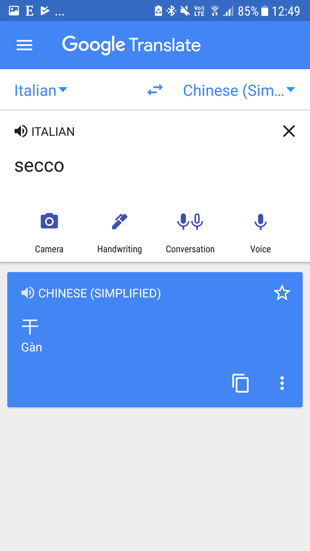
| Picture 14: Language A to Language B translations showing the single sense that GT has calculated through English | ||
Table 6 shows an estimation of how likely results are to have some intelligibility from one language to another, when English is neither source nor target. Full itemized scores can be viewed at http://kamu.si/gt_scores_cross_language_extrapolation. Translation from any language in the GT system to any other is a fundamental claim that has never faced systematic evaluation. For Language A to Language B comparisons, I extrapolated round scores based on Tarzan results between each language and English. For a very few pairs that do not pivot through English (such as Catalan-Spanish, which I predict at 45), the TYB score will be categorically wrong. For almost all other pairs, the score is broadly indicative. Picture 14 shows actual GT results for a term that has 37 English senses in the Merriam-Webster dictionary (though not necessarily 37 unique translations, e.g. Dutch uses “droog” for dry wine, dry humor, and dry laundry), where the service always funnels non-English translations through their estimate of the most likely English result for each polysemous term, with rampant errors introduced due to the inherent mathematics of polysemy ; a more precise measure would account for the number of times that any given term has a translation other than the one selected in each language, with some accounting for frequency of each sense.
Many terms like “out” and “run” are highly polysemous, so the expected percentage of correct second-generation translations through English would be a fraction of the first-generation Tarzan estimate from English. If an English term has 50 senses that have different translations in two languages being paired, all of equal likelihood (for example, https://en.wiktionary.org/wiki/run has 100 senses for “run”, such as standing for office or operating a machine; some of these senses might equate to the same word in a given target language), a good match could be expected 0.04% of the time. Meanwhile, a term such as “polysemous”, which has only one sense, should be translated correctly 100% of the time.

Picture 14.1: Translations of long texts in GT can flicker among words like the lights in this showerhead, as minor elements such as capitalization, punctuation, word order, or words unrelated to the context change. Photo by author.
In theory, longer translations with more context should increase the accuracy of the proposed translation equivalent; for example, “run a company” often returns the foot-racing sense of “run” on its own, but the management sense in a longer sentence. This is not necessarily the case in practice, however; for example, “delivery room” by itself was returned with the correct sense of birthing in several sample languages (though verified incorrectly for German as shown in Picture 46), but erroneously regarding packages or (inexplicably) calls in a longer sentence from a newspaper. The clause “while I swim my laps” might variously be translated to French by omitting the concept of laps entirely, using the correct swimming term “longueurs”, using the term for laps around a racetrack “tours”, or using the word “genoux” for “knees” (because French speakers put their children and their laptop computers on their knees, laps not being an anatomical concept for them), depending on whether the previous clause begins with “Please,” or “Please” (that is, comma or no comma) or various other changes that should have no effect on the clear association of “swim” and “laps”. Picture 14.1 is a visual metaphor for the way GT translations for longer texts can change arbitrarily due to factors that should be irrelevant to a machine’s ability to derive accuracy through context. Because there is no way to test for such factors as whether a comma changes a translation from swimming around a track to swimming your knees, trying to measure translations of long texts from Language A to Language B would also introduce a lot of noise, like trying to pin down the color on a spinning showerhead, that could not be filtered out.
I did not consider Bard scores, which will always be lower than Tarzan scores, because I have no information about the quality of translations to English that begin with other languages; sample tests with non-English bilinguals show that elegant translations do not emerge for languages pairs with no direct model. I acknowledge that Tarzan-to-Tarzan calculations are an imperfect measurement. However, with 5671 total non-English language pairs within GT,38 most of which have no living bilingual speakers, there is no conceivable method of independently testing each combination.
With the above caveats, Tarzan-to-Tarzan scores for the 5151 pre-KOTTU pairs indicate the following:
- 54 pairs, slightly more than 1% (pre-KOTTU; slightly less than 1% post-KOTTU), will produce translation results where a reader can get the gist of the original intent more than half the time. 26 of these are in pairs with Afrikaans, 12 more in pairs with German, 11 more in pairs with Portuguese, and the remaining 3 pairs among combinations with Spanish.
- 23.8% of pairs produce results where the gist can be understood between a quarter and a half of the time. This includes many major commercial pairs such as French-German and Spanish-Italian.
- 75.2% of pairs produce results where the gist can be understood less than a quarter of the time.
- Nearly 30% of pairs produce results where the gist can be understood 10% of the time or less.

Picture 15: Arbitrarily selected German text from Wikipedia. https://de.wikipedia.org/wiki/Der_Spiegel
Subjective tests for some language pairs suggest that relative results largely adhere to the rankings, but non-English translations in certain situations might be significantly more understandable than the numbers indicate. For example, an arbitrary selection of text from the German Wikipedia (Picture 15) was rendered in French that was much more than 49.5% readable, and more understandable in Swahili than suggested by a Tarzan-to-Tarzan score of 21. More dramatically, translation of a news article from Haitian Creole,39 a language that scored zero in my tests, would receive Tarzan scores above 50 in French, Spanish, and perhaps Swahili.40
Several factors may affect translation outcomes. First, the type of text is important, since GT is trained with certain types of parallel text. Well-structured documents that are written in formal language for a general audience, such as Wikipedia or news articles, are generally translated better than other types of writing, such as correspondence (all along the gamut from tweets to business letters), literature that makes use of figurative daily language, or domain-specific texts from restaurant menus to academic articles that rely on specialized vocabularies. Second, long segments and full sentences often translate better than short fragments, whether because the translation engine has more context to make an informed calculation about which sense of a word is appropriate,41 or because the reader has more context to overlook mistakes such as, in the Haitian case, a mistranslation of “last straw” as “final killers”. Third, the starting language is important; a language that has a high initial score to English (German ranks second overall) will retain more fidelity at the pivot point. In the case of the German -> English translation from the Wikipedia article in Picture 15, this full sentence, “In 1958, the debate on the emergency laws began in the mirror, from which later (1960, 1963, 1965) various draft laws of the Interior Minister Gerhard Schröder were” is clearly missing important elements,42, 43 but the reader’s eyes can pass over “in the mirror”, and the properly constituted parts give context for a B-level Tarzan understanding. The translations downstream to French and Swahili degrade further, but keep enough of the sense that the overall topic of the sentence can be gleaned. What the sentence in question illustrates is that:
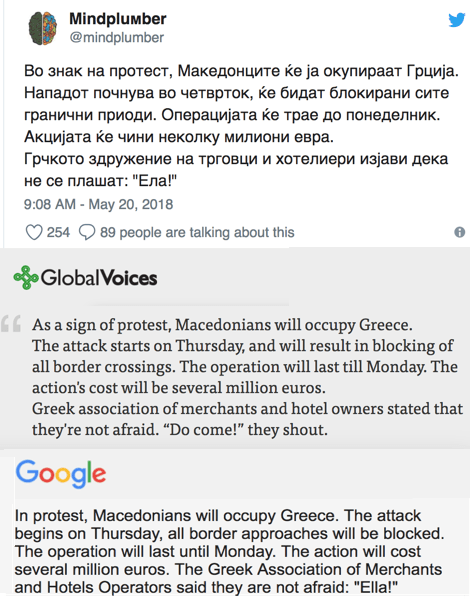
Picture 16: Human and GT translations of Macedonian tweet. GT misses only one word, for a Bard rating of 95.
a. errors from Language A to English do get amplified in the subsequent step from English to Language B
b. the amount of amplification should be roughly proportional to the Tarzan-to-Tarzan ratings I report (that is, pairs with high scores versus English will do better than pairs with low scores)
c. my data is not extensive enough to pin a scaled numerical value to full-sentence translations
d. Language A to English scores ideally should be measured independently for all 107 languages, as Table 1 does for Dutch, rather than imputed from the English to Language A performance.44 Picture 16 shows a near-perfect translation from Macedonian to English, as compared to a human,45 whereas Picture 1 shows a total failure from Japanese.46, and Macedonian also fared poorly on the same quotation from Mandela. If the score from Language A toward English is substantially different than its score away from English, then my cross-language calculation will be significantly in error.
Further testing would be necessary to make definitive statements about translations among any non-English pairs. It would be impossible to find native speakers from both directions to test all 5671 pairs. However, testing GT against human translations between each language and English, as performed in Picture 1 and Picture 16, could be done, at considerable time and expense. I propose the Tarzan-to-Tarzan scores as one metric for estimating the quality of results among languages in the GT system, but suggest that a more in-depth study would yield superior results.
Empirical Conclusions47
This empirical evaluation has presented the numerical findings of research about GT for 107 languages. I tested how well 20 short English phrases transmitted their meaning in each language. The highest-scoring language, Afrikaans, preserved the original meaning in 16 of the 20 test phrases, and used the same words that a human translator would have chosen in as many as 11 cases.48 On the other hand, Bengali (the world’s seventh most-spoken language), Haitian Creole, and Tajik did not convey the original meaning in any cases. For 71 languages (66.4%), the gist of the phrase was transmitted half the time or less.
All of the data from this research is openly available at http://kamu.si/gt-scores. This includes the 20 original English phrases, the 20 English paraphrases that were provided to evaluators, the 2,140 translations produced through GT, and the evaluator scores for each of those translations. The spreadsheet contains tables showing the scores for each language in terms of producing human quality translations, understandable results, or incomprehensible results. These tables are arranged alphabetically, by quality rank, by comprehensibility rank, by frequency of failure, and by number of speakers of each language. An additional table, on a separate tab, estimates interlanguage comprehensibility for all 5151 pre-KOTTU pairs.
In the empirical evaluation, the data was offered without further interpretive commentary. The next section is a qualitative analysis that delves into interpreting the results in the wider context of contemporary research regarding MT in general and GT in particular. The qualitative part contains opinions that may be considered as subjective. It is presented separately so the objective data above can stand on its own, as the first study to compare Google Translate across its entire range of languages.

Picture 16.1: At a fountain in Evian-les-Bains in France, a sign instructs tourists to come near in order to activate the water flow. A screenshot of the Tarzan-level GT translation from French to English from Google via Instant Camera is shown on the right. Reacting to this montage at 9.5 years old, my daughter, native in both languages, sums up what it means to “get the gist” in a nutshell: “It has the same general sense but it does not grammatically or orally mean anything. But it’s not too horrible.” A large proportion of visitors to Source Evian are non-English speakers, so will be attempting translations of the French (unbeknownst to them via English) to languages such as Japanese and Hindi.
References
Items cited on this page are listed below. You can also view a complete list of references cited in Teach You Backwards, compiled using Zotero, on the Bibliography, Acronyms, and Technical Terms page.
To notify TYB of a spelling, grammatical, or factual error, or something else that needs fixing, please select the problematic text and press Ctrl+Enter.
![]()
Footnotes
- link here: http://kamu.si/tyb-empirical-description
- link here: http://kamu.si/tyb-english-to-X
- A bard is a poet or teller of epic tales. “The Bard” is William Shakespeare. Bards are master wordsmiths of their language.
- “Me Tarzan, you Jane” was said by Johnny Weissmuller, who played Tarzan in the 1932 movie “Tarzan the Ape Man”: “I didn’t have to act in Tarzan, the Ape Man — just said, ‘Me Tarzan, you Jane’” (http://www.thisdayinquotes.com/2010/03/weissmuller-me-tarzan-you-jane.html). The movie scene did not contain that actual statement: http://kamu.si/tarzan-jane-video
- link here: http://kamu.si/tyb-X-to-english
- GT does not include any indigenous languages of South or North America,
- For many languages, finding a native speaker involved searching for a discussion group on Facebook, applying to join, waiting for acceptance, then posting on the group wall. For other languages, I was able to go back to the participants in the original study, but needed to sift through emails and chat messages on numerous platforms to re-establish contact with the right person. The task is made more difficult because both Facebook and LinkedIn block your communications if you send too many similar messages within a short timespan.
- I posit that GT came up with “Hi” because the first word in the Zulu phrase is “Hola”, so somehow the Spanish meaning of that spelling unit seeped into the neural network’s Zulu-English vector space.
- link here: http://kamu.si/tyb-a-to-b
- Japanese/Korean (mentioned by Johnson et al (2016)), Catalan/Spanish, and Czech/Slovak have direct channels, as confirmed in my tests. However, their “Language Support” page, https://cloud.google.com/translate/docs/languages, lists only English as a production language for their NMT model vis-à-vis their other languages. They say that their “PBMT model supports translations from any language in [their] list to any language in [their] list”, without defining the meaning of “supports”. My testing finds that most translations are evidently passing through an English stage. For example, I translated a newspaper article from French to English and then from English to German, and compared that to the direct GT translation from French to German. The results, shown here, are almost verbatim, and include an error introduced in the English translation that entirely reverses the sense of the original French (“nous savons mieux qu’il faut dire”, which should be “we know better that we should say” is translated as “we know better than to say”). You can see graphically that Belarusian/Russian pivots through English, despite indications in Johnson et al (2016) that they have tested a direct path. Tests of full paragraphs from Italian to Corsican, Swahili, French, Romanian and German, and from Thai to Welsh, all show English as the intermediary. Croatian to Bosnian pivots through English, although any language professional in Croatia or Bosnia will explain that it is one language with two governments and a few divergent regional features. A language authority from the Netherlands was certain beforehand, knowing that Google had done some work with the Frisian community on some set of translations, that Frisian-Dutch was a local mix, but confirmed that English was the intermediary when she participated in running the comparison test. Other people who have run similar tests have reached the same conclusion, on the basis of lost grammatical or semantic information, though the tests always have the potential to be out of date: https://www.quora.com/Does-Google-Translate-use-English-as-an-intermediary-step-language-Spanish-English-Italian. On the other hand, a test discussed on Quora indicates that Slovak/Czech is direct matching: http://qr.ae/TUTpRY, which my testing also shows. A thorough test of Catalan-Spanish shows that a direct GT translation is quite different than one forced through English.
- In some cases, errors that enter through the English conversion are smoothed out by reversal in the second phase. For example, the Italian news article shown in Picture 12 with the sentence “14 pastori sono rimasti bloccati” was mistranslated to English as “14 pastors remained stuck” instead of “14 shepherds were stranded”. Many languages, such as Swahili, actually use the same word for pastor and shepherd, so the mistake disappeared in the final output. However, languages such as German that use different words preserved the erroneous English sense.
- link here: http://kamu.si/tyb-methodology
- Natural usage examples are found by searching Twitter for the phrase within quotation marks. I stand by using Twitter as a source for language as used in its natural context. As a corpus, it comes closer to the way people speak to each other in daily life than any other available resource, with zillions of real world examples spontaneously expressed by ordinary people who do not feel the need to adhere to pedantic editorial rules. Certainly, Twitter is a repository of a lot of junk text (typos, abbreviations, misspellings, bad grammar, etc.) that makes it unusable in raw form for many NLP tasks, so needs filtering in order to select those tweets that have use value. It is nevertheless a more natural source for ordinary speech than Wikipedia (as I discuss), the Europarl corpus, or other bodies of consciously polished text. Crucially, tweets often contain colloquial language that is used by millions every day, but never used in formal writing. In a world where people use idioms and informal language and words like “zillions”, it is important that MT services, and readers of papers about MT, be able to bend to the expressions of the average Joe. The words of one anonymous reviewer offer an alternative opinion, however: “It is not scientific to rely on Twitter to justify what is common/uncommon in language. Twitter is just a specific form of social media that can be considered as a specific domain, but hardly represents the whole language.”
- Polysemy in Wiktionary was determined by counting the number of top level senses for each word. This method does not count many senses that Wiktionary categorizes as second or third level sub-senses, but might be different ideas that call for different translations in other languages. On the other hand, the method may count senses that other dictionaries would not include. I also threw out a few clearly irrelevant lines, such as “their” defined as a misspelling of “there”, and cases such as “could” defined as “simple past tense of can” that subsumed multiple senses in one. Many of the words in the top 100 are unusual because they are function words, such as “not” or “because”, rather than standard nouns, verbs, adjectives, or adverbs. The least ambiguous words, with two senses apiece, are “their”, “its”, “also”, and “these”. The most ambiguous are “do” (38), “out” (38), “on” (43), “make” (48), “up” (50), “go” (54), and “take” (66). Two thirds (67) of the words have 10 or more senses. The list does not account for use of words within multiword expressions, such as phrasal verbs like “make up” or “take out”. I do not propose that this dataset is a perfect measure of polysemy, but it does demonstrate the scale. The full “Polysemy in top 100 Oxford English Corpus words within Wiktionary” dataset is available to view and use as open data without restriction at http://kamu.si/polysemy_top_100.
- https://twitter.com/Truthseer1961/status/984766225849954305. English: A common, run of the mill suck up that thought Hillary was going to win and sought to personally profit from it. GT French: Un point commun, une course de l’usine qui a cru que Hillary allait gagner et a cherché à en profiter personnellement.
- https://en.wikipedia.org/wiki/Most_common_words_in_English
- http://www.wordreference.com/enfr/out?start=1600
- I realized too late that the phrase “out of order” is ambiguous, with meanings of “improper” and “misarranged” in addition to the sense I provided, “broken”. Nevertheless, it was one of the highest performing phrases in the study, with a Tarzan rating above 50%. For some languages where the phrase failed as “broken”, it may have captured one of the other senses. This points to the deeper problem of polysemy – that is, even a translation of a polysemous term that is perfect for one sense is guaranteed to be wrong in the preponderance of cases where unrelated source senses map to unrelated target vocabulary. Therefore, “out of order” slightly inflates the scores for every language where it received an A or a B, because the “correct” result would be wrong twice if the other two senses were included in my tests, and it might slightly deflate the scores for languages (if any) that produced a correct rendering for a different sense. It is worth noting that GT has certified “out of order” as a “verified translation” in dozens of languages, almost always with the sense of “broken” – so, in fact, TYB’s test matches GT’s erroneous implication that the phrase has only one meaning, and its assumption of what that meaning is.
- href=”https://twitter.com/T_C_Hadden/status/744538713816862724″
- href=”https://twitter.com/CaplanMatt/status/1026530023325364224″
- href=”https://twitter.com/MyPostcardFrom/status/194555454079254528″
- href=”https://twitter.com/smithlrn/status/679776721403379712″
- href=”https://twitter.com/timkowal/status/526954749045014528″
- href=”https://twitter.com/markjleach/status/63262575550402562″
- href=”https://twitter.com/squeezyjohn/status/989485160373608451″
- href=”https://twitter.com/EmilyRDinsmore/status/989223187241226250″
- What constitutes a “fair” test of translation is controversial. The metric favored by computer scientists, BLEU, produces a numerical score based on certain correspondences between human and machine translations. BLEU has substantial weaknesses, chronicled in the discussion of the Myth of Neural Machine Translation. Controversies have also arisen over exam questions for European students of English; see Kim Willsher, “French teens unable to ‘cope with’ baccalaureate English question”, The Guardian 22 June 2015, and Christopher Schuetze, “Thousands of German Students Protest ‘Unfair’ English Exam“, New York Times, 5 May 2018.
- link here: http://kamu.si/tyb-evaluators
- Esperanto and Latin were evaluated by people with professional proficiency. While some children are raised speaking Esperanto from birth alongside their local or ancestral languages, I did not attempt to locate such individuals for this study. As far as I know, Latin is only spoken by people who learn it through formal study.
- link here: http://kamu.si/tyb-results
- E.g., since 1850, the temperature at point X has risen by °Y.
- E.g., coastal cities will soon be swamped by rising seas because of elevated CO2.
- E.g., achieve carbon neutrality by covering houses with the revolutionary open-source solar roofing tiles we have designed.
- link here: http://kamu.si/tyb-elegance
- link here: http://kamu.si/tyb-gist
- There is a lot of variance within the parameters of “getting the gist”. For example, in a conversation in Chinese (which is totally opaque to me) that was taking place around my head on a New York subway, the speakers used several English phrases, such as “CEO”, “before tax”, and “pension”, to the extent that I could fathom they were discussing whether certain financial opportunities could benefit ordinary people such as themselves. Do I really know what they were talking about? Not at all. Would my understanding pass at the Tarzan level on certain sentences? Perhaps.
- link here: http://kamu.si/tyb-non-english
- For language-to-language scores, I only kept the highest-scoring variety for Portuguese and Spanish. I have not calculated the scores for pairs involving the KOTTU languages added in February 2020, which would take hours and offer little benefit to anyone.
- Ekip Sèvis, Kreyòl VOA, Prezidan Trump Anile yon Somè Ant Li Menm ak Lidè Kore di Nò a, Kim Jong Un, 24 May, 2018. https://www.voanouvel.com/a/trump-kore-di-no-kim-jong-un-some-sanksyon-sengapou/4408762.html
- The Haitian article is a journalist’s modification of an article originally written in English. It is therefore possible for a non-Creole-speaker to gauge much of the Creole-English translation, by comparison of the GT result to the original English article. A Tarzan rating of the back-translation from Haitian to English could be about 70 – that is, the GT translation conveys about 70% of the sense of the original English. The reader may judge, as “planned in Singapore” becomes “engraved in Senegal” (an error of 13,000 km); “foolish or reckless” becomes “fake and frightening” (negative sentiments are conveyed, but not the right ones); and the final two sentences have many correct words, but an overall puzzling effect: “This meeting we’ve been planning for long ago. ‘According to the White House, the latest killers are a failure of North Korea’s foreign minister, Choe Son Hui, launching US Vice President Mike Pence, when he says he views M. Pence as ‘a silly pilitic.’” One must conclude that the model for Haitian Creole to English for full sentences is substantially more effective than the model for English to Haitian Creole for isolated phrases. Steve Herman, VOA News, Trump Calls Off Upcoming North Korea Summit, 24 May 25, 2018. https://www.voanews.com/a/trump-cancels-june-12-summit-with-north-korea/4408007.html
- For example, the phrase “across the board” is incomprehensibly rendered in isolation in French as “à travers le conseil”, but reaches Bard status when the fragment expands to “its performance across the board”, translated as “sa performance à tous les niveaux.”
- The text becomes almost fully comprehensible in English when GT translations are compared to those of Microsoft Translator (https://www.bing.com/translator) and DeepL (https://www.deepl.com), so that the errors of each service can be triangulated out. Nevertheless, the error “in the mirror” is repeated in all three. One can only understand the mistake by knowing that the subject of the article – Der Spiegel, the German weekly news magazine that is one of Europe’s largest publications of its kind – translates literally to English as “The Mirror”.
- link here: https://teachyoubackwards.com/empirical-evaluation/#der-spiegel
- A better methodology would be to compare texts that have been translated by humans with translations of those same texts by GT. Available sources of parallel content are generally not direct translations from one language to another, however. For example, Wikipedia articles in different languages often present much of the same information, but not matched line for line. It is possible that GT uses Wikipedia articles as training data for their system, in which case that would not be a neutral source for testing. Excellent sources of parallel content in a few dozen languages include Voice of America (voanews.com), the BBC (bbc.com), and Deutsche Welle (dw.com). I attempted to use human translations of the same English quotes for cross-lingual comparison, from all three news services, but discovered that not all languages on a service carry the same stories, and, when they do, they often paraphrase quotes instead of translating them verbatim. Global Voices is an excellent source of translated text for a few dozen languages (globalvoices.org). For the many dozen GT languages that are not covered by any of these sources, the act of finding sample sets of direct human translations for comparison would take several weeks, and in some cases might demand paid professional translators. An extensive study to evaluate text translations from 107 languages to English would cost several thousand dollars.
- Filip Stojanovski, “Macedonians manage to joke about a serious naming dispute with Greece”, posted 25 May 2018. https://globalvoices.org/2018/05/25/macedonians-manage-to-joke-about-a-serious-naming-dispute-with-greece/
- 誰もが知るべきネルソン・マンデラの17の知恵, translated by Koichi Higuchi, posted on 2013/12/25. https://jp.globalvoices.org/2013/12/25/26603/
- link here: http://kamu.si/tyb-empirical-conclusions
- Afrikaans evaluators disagreed about whether a translation was perfect in three cases.
About this: “There can be shades of grey about whether a translation conveys the original meaning. For example, “Rule from the back” (Polish) has more of an aspect of dictatorship than the benevolent guidance that Mandela had in mind, blurring but not erasing the overall intent of the quote.” — isn’t this something even a human would get wrong, if you would have told them that Heinrich Himler said it, instead of Mandela ?
[…] loro uso e sviluppo rischiano di acuire il divario fra lingue ‘maggiori’ e lingue ‘minori’. Uno studio recente ha valutato le traduzioni di Google traduttore utilizzando 20 frammenti di testo in inglese, la cui […]